- IO阻塞、非阻塞、同步、异步
- select、poll、epoll
- nohup与&的区别
- 启动Linux守护进程的方法
- 静态链接与动态链接比较
- Linux中通过编译安装的方式安装程序的各步骤
- 进程状态
- Linux ext2和ext3文件系统的区别
- 乐观锁与悲观锁
- 僵尸进程
- 分页和分段
- 后台进程与守护进程
- 查看僵尸进程
- 僵尸进程变为孤儿进程
- 查看Linux进程之间的关系
- 协程理解
- 死锁产生的四个必要条件
- Linux用户身份切换
- 查看系统负载
- IOWait
- DMA(Direct Memory Access)
- 同步阻塞I/O与同步非阻塞I/O
- 多路I/O就绪通知的各种实现
- 直接I/O
- 同步和异步、阻塞和非阻塞概念理解
- rsync
- inotify
- 电子电路对计算机信息的表示
- Y86处理器顺序执行指令的步骤
- 指令集与流水线化处理器
- SRAM、DRAM、RPM、PROM、EPROM、EEPROM
- 存储器层次结构
- 异常处理与过程(函数)调用的区别
- 地址翻译
- 内核空间、系统空间、系统调用、中断概念
- 处理器的运行状态
- 单内核和微内核
- Linux与Unix的差异
- 进程、线程
- 进程状态
- 进程上下文切换
- 写时拷贝
- 线程在Linux中的实现
- 内核线程
- 孤儿进程
- 完全公平调度算法(CFS)
- 睡眠和唤醒
- 上下文切换
- 用户抢占、内核抢占
- 应用程序、C库和内核之间的关系
- 中断相关概念
- 划分工作为上半部或下半部的基本规则
- 下半部的实现机制
- 软中断的实现
- 工作队列的实现
- 内核中有可能造成并发执行的原因
- 自旋锁
- 信号量、互斥信号量、计数信号量
- 互斥体
- 完成变量
- 顺序锁
- jiffies
- 时钟中断处理程序
- 页(page)
- 区(zone)
- slab层
- 内核栈
- 虚拟文件系统
- Unix文件系统相关对象
- 平坦地址空间
- 内存区域
- 页表
- 页高速缓存和页回写
- flusher线程
- 设备类型
- 伪设备
- 模块
- 内核的职责
- 目录权限
- 进程的内存布局
- 进程的用户和组标识符
- init进程
- 内存映射
- 信号并非实时到达
- 执行系统调用所发生的步骤
- 文件空洞
- 内核对文件描述符和打开文件之间关系的描述
- 分散输入和集中输出
- 程序包含的信息
- 从内核的角度理解进程
- 进程内存中的段
- 虚拟内存的好处
- 用户栈帧的内容
- program break
- 一般情况下应该避免使用realloc()
- set-user-ID
- 查看进程执行时间
- 直接I/O
- 文件的i节点所维护的信息
- ext2文件系统中文件的文件块结构
- 目录与普通文件的区别
- 硬链接的限制
- chroot监禁区
- inotify机制
- 信号处理器程序
- 有关进程创建的4个重要的系统调用
- 父进程应该使用wait()来防止僵尸进程的积累
- 调用execve()之后进程ID保持不变
- UNIX内核对脚本的要求
- 线程相对进程的优点与缺点
- pthread_join()
- 各线程所独有的属性
- 互斥量、临界区、条件变量概念
- 线程安全的函数
- 进程组、会话和作业控制概念
- SIGHUP
- nice值
- daemon
- Linux能力
- 登录记账相关文件
- 共享库的安装目录
- SOCKET Domain
- SOCKET相关的系统调用
- UNIX SOCKET
- 伪终端
- 描述Linux中一次进程切换过程中操作系统的行为。
- join命令
- 网络通信中,write返回成功后,是否确保数据发送成功或是被对端服务收到
- 线程与进程继承关系的区别
- nobody
- 将一个进程启动为守护进程
- Linux文件权限0600是什么意思?
IO阻塞、非阻塞、同步、异步
I/O过程总体上分为两步:数据准备、数据复制。同步和异步描述的是整个I/O的工作方式,阻塞和非阻塞描述的是I/O的数据复制方式。
同步和异步 同步和异步是针对应用程序和内核的交互而言的,同步指的是用户进程触发I/O操作并等待或者轮询的去查看I/O操作是否就绪,而异步是指用户进程触发I/O操作以后便开始做自己的事情,而当I/O操作(含数据准备和数据复制)已经完成的时候会得到I/O完成的通知。
阻塞和非阻塞 阻塞和非阻塞是针对于进程在访问数据的时候,根据I/O操作的就绪状态来采取的不同方式,是一种读取或者写入函数的实现方式,阻塞方式下读取或者写入函数将一直等待,而非阻塞方式下,读取或者写入函数会立即返回一个状态值。
服务器IO模型
-
阻塞式模型(blocking IO) 大部分的socket接口都是阻塞型的( listen()、accpet()、send()、recv() 等)。阻塞型接口是指系统调用(一般是 IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。在线程被阻塞期间,线程将无法执行任何运算或响应任何的网络请求,这给多客户机、多业务逻辑的网络编程带来了挑战。
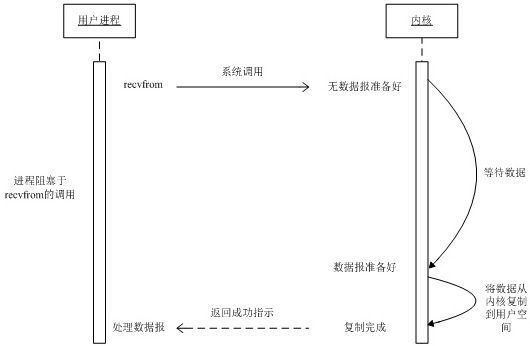
-
多线程的服务器模型(Multi-Thread) 应对多客户机的网络应用,最简单的解决方式是在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。但是如果要同时响应成千上万路的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率。 在多线程的基础上,可以考虑使用线程池或连接池,线程池旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。连接池维持连接的缓存池,尽量重用已有的连接、减少创建和关闭连接的频率。这两种技术都可以很好的降低系统开销,都被广泛应用很多大型系统。
-
非阻塞式模型(Non-blocking IO) 相比于阻塞型接口的显著差异在于,在被调用之后立即返回。
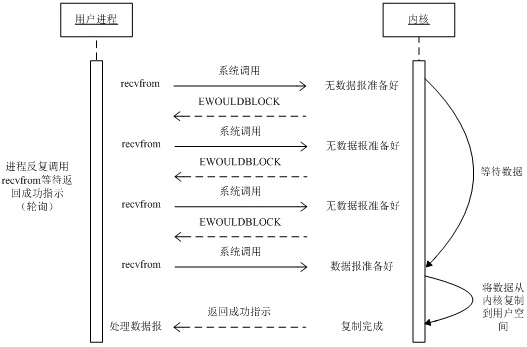 需要应用程序调用许多次来等待操作完成。这可能效率不高,因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止。
另一个问题,在循环调用非阻塞IO的时候,将大幅度占用CPU,所以一般使用select等来检测是否可以操作。
需要应用程序调用许多次来等待操作完成。这可能效率不高,因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止。
另一个问题,在循环调用非阻塞IO的时候,将大幅度占用CPU,所以一般使用select等来检测是否可以操作。 -
多路复用IO(IO multiplexing) 支持I/O复用的系统调用有select、poll、epoll、kqueue等。使用select然需要轮询再检测每个socket的状态(读、写),这样的轮询检测在大量连接下也是效率不高的。因为当需要探测的句柄值较大时,select () 接口本身需要消耗大量时间去轮询各个句柄。 很多操作系统提供了更为高效的接口,如Linux 提供了
epoll,BSD提供了kqueue,Solaris提供了/dev/poll…。如果需要实现更高效的服务器程序,类似epoll这样的接口更被推荐,能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。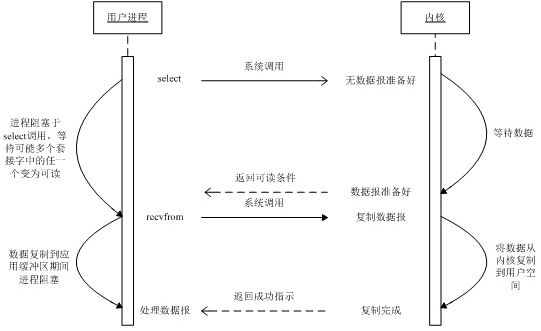
-
使用事件驱动库libevent的服务器模型 libevent是一个事件触发的网络库,适用于Windows、Linux、BSD等多种平台,内部使用select、epoll、kqueue、IOCP等系统调用管理事件机制。 libevent库提供一种事件机制,它作为底层网络后端的包装器。事件系统让为连接添加处理函数变得非常简便,同时降低了底层IO复杂性。这是libevent系统的核心。 创建libevent服务器的基本方法是,注册当发生某一操作(比如接受来自客户端的连接)时应该执行的函数,然后调用主事件循环event_dispatch()。执行过程的控制现在由libevent系统处理。注册事件和将调用的函数之后,事件系统开始自治;在应用程序运行时,可以在事件队列中添加(注册)或 删除(取消注册)事件。事件注册非常方便,可以通过它添加新事件以处理新打开的连接,从而构建灵活的网络处理系统。
-
信号驱动IO模型(Signal-driven IO) 让内核在描述符就绪时发送SIGIO信号通知应用程序。
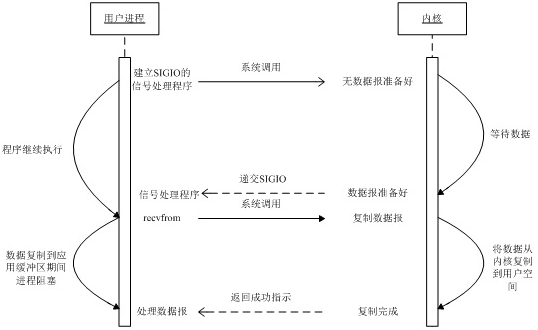
-
异步IO模型(asynchronous IO) 告知内核启动某个操作,并让内核在整个操作(包括将数据从内核复制到用户的缓冲区)完成后通知用户。这种模型与信号驱动模型的主要区别在于:信号驱动式I/O是由内核通知何时可以启动一个I/O操作,而异步I/O模型是由内核通知I/O操作何时完成。
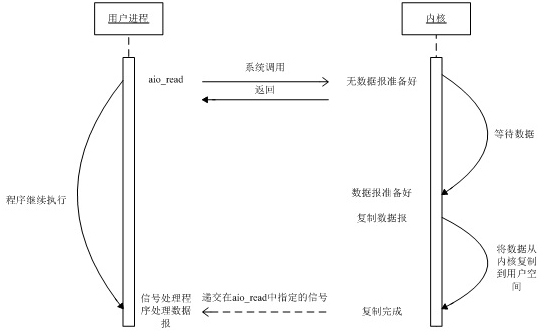
异步IO与同步IO的区别 A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes; An asynchronous I/O operation does not cause the requesting process to be blocked; 两者的区别就在于synchronous IO做IO operation的时候会将process阻塞。按照这个定义阻塞、非阻塞、IO多路复用其实都属于同步IO。
异步IO与非阻塞IO的区别
在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作(分为两步:准备数据、将数据从内核复制到用户空间)交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
select、poll、epoll
文件描述符(fd) 文件描述符是一个简单的整数,用以标明每一个被进程所打开的文件和socket的索引。第一个打开的文件是0,第二个是1,依此类推。最前面的三个文件描述符(0、1、2)分别与标准输入(stdin),标准输出(stdout)和标准错误(stderr)对应。Unix操作系统通常给每个进程能打开的文件数量强加一个限制。当用完所有的文件描述符后,将不能接收用户新的连接,直到一部分当前请求完成,相应的文件和socket被关闭。
IO多路复用技术
select,poll,epoll都是IO多路复用的机制。I/O多路复用通过一种机制,可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。select、poll、epoll本质上都是同步I/O,因为它们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll的改进
- select、poll需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在醒着的时候要遍历整个fd集合,而epoll在醒着的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升(本质的改进在于epoll采用基于事件的就绪通知方式)。
- select、poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。(本质的改进就是使用了内存映射(mmap)技术)
epoll被公认为Linux2.6下性能最好的多路I/O就绪通知方法,实现高效处理百万句柄。
nohup与&的区别
最直观的区别: 使用&执行的命令,要是关闭终端(将发出SIGHUP信号),命令会停止(即后台进程仍然会响应SIGHUP信号)。而使用nohup执行的命令,既使把终端关了,命令仍然会继续运行。 nohup执行的命令会忽略所有挂断(SIGHUP)信号。 一般结合使用:nohup command &
启动Linux守护进程的方法
Linux进程类型 Linux操作系统包括如下3种不同类型的进程,每种进程都有其自己的特点和属性。
- 交互进程:由shell启动的进程。可在前台运行,也可在后台运行;
- 批处理进程:一个进程序列;
- 守护进程:守护进程是指在后台运行而又没有启动终端或登录shell。守护进程一般由系统开机时通过脚本自动激活启动或者由root用户通过shell启动。守护进程总是活跃的,一般在后台运行,所以它所处的状态是等待处理任务的请求。
启动守护进程有如下几种方法
- 在引导系统时启动:通过脚本启动,这些脚本一般位于
/etc/rc.d中。在/etc目录下的很多rc文件都是启动脚本 。rc0.d、rc1.d、rc2.d、rc3.d、rc4.d、rc5.d、rc6.d,其中的数字代表在指定的runlevel下运行相应的描述,0代表关机,6代表重启。其中,以k开头的文件表示关闭,以s开头的文件表示重启。可查看相应文件夹中的readme文件。rc0.d、rc1.d、rc2.d、rc3.d、rc4.d、rc5.d、rc6.d、rcS.d都连接到/etc/init.d文件夹,该目录中存放着守护进程的运行文件。 - 人工手动从shell提示符启动:任何具有权限的用户都可以启动相应的守护进程。
# 启动FTP服务器,ubuntu下默认已经安装了vsfptd服务器 root@Ubuntu:~# /etc/init.d/vsftpd start -
使用crond守护进程启动
-
执行at命令启动
静态链接与动态链接比较
静态链接就是把外部函数库,拷贝到可执行文件中。这样做的好处是,兼容性好,不用担心用户机器缺少某个库文件;缺点是安装包会比较大,而且多个应用程序之间,无法共享库文件。 动态连接的做法正好相反,外部函数库不进入安装包,只在运行时动态引用。好处是安装包会比较小,多个应用程序可以共享库文件;缺点是用户必须事先安装好库文件,而且版本和安装位置都必须符合要求,否则就不能正常运行。 现实中,大部分软件采用动态连接,共享库文件。这种动态共享的库文件,Linux平台是后缀名为.so的文件,Windows平台是.dll文件,Mac平台是.dylib文件。
Linux中通过编译安装的方式安装程序的各步骤
源码要运行,必须先转成二进制的机器码。这是编译器的任务。 对于简单的代码,可以直接调用编译器生成二进制文件后运行,如:
$ gcc test.c
$ ./a.out
对于复杂的项目,编译过程通常分成3个部分:
$ ./configure
$ make
$ make install
整个编译安装过程分为以下步骤:
- 配置
配置信息保存在一个配置文件之中,约定俗成是一个叫做
configure的脚本文件。通常它是由autoconf工具生成的。编译器通过运行这个脚本,获知编译参数。如果用户的系统环境比较特别,或者有一些特定的需求,就需要手动向configure脚本提供编译参数,如:
# 指定安装后的文件保存在www目录,并且编译时加入mysql模块的支持
$ ./configure --prefix=/www --with-mysql
-
确定标准库和头文件的位置 从配置文件中知道标准库和头文件的位置。
-
确定依赖关系
源码文件之间往往存在依赖关系,编译器需要确定编译的先后顺序。假定A文件依赖于B文件,编译器应该保证:只有在B文件编译完成后,才开始编译A文件。且当B文件发生变化时,A文件会被重新编译。
编译顺序保存在一个叫做makefile的文件中,里面列出哪个文件先编译,哪个文件后编译。而makefile文件由configure脚本运行生成,这就是为什么编译时configure必须首先运行的原因。
-
预编译头文件 不同的源码文件,可能引用同一个头文件(比如stdio.h)。编译的时候,头文件也必须一起编译。为了节省时间,编译器会在编译源码之前,先编译头文件。这保证了头文件只需编译一次,不必每次用到的时候,都重新编译了。不过,并不是头文件的所有内容都会被预编译。用来声明宏的#define命令,就不会被预编译。
-
预处理 编译器就开始替换掉源码中的头文件和宏以及移除注释。
-
编译 编译器就开始生成机器码。对于某些编译器来说,还存在一个中间步骤,会先把源码转为汇编码(assembly),然后再把汇编码转为机器码。这种转码后的文件称为对象文件(object file)。
-
链接 把外部函数的代码(通常是后缀名为.lib和.a的文件)添加到可执行文件中。这就叫做链接(linking)。这种通过拷贝,将外部函数库添加到可执行文件的方式,叫做静态连接(static linking) make命令的作用,就是从头文件预编译开始,一直到做完这一步。
-
安装 将可执行文件保存到用户事先指定的安装目录。这一步还必须完成创建目录、保存文件、设置权限等步骤。这整个的保存过程就称为安装(Installation)。
-
操作系统链接 以某种方式通知操作系统,让其知道可以使用这个程序了。这就要求在操作系统中,登记这个程序的元数据:文件名、文件描述、关联后缀名等等。Linux系统中,这些信息通常保存在
/usr/share/applications目录下的.desktop文件中。 make install命令,就用来完成安装和操作系统连接这两步。 -
生成安装包 将上一步生成的可执行文件,做成可以分发的安装包。通常是将可执行文件(连带相关的数据文件),以某种目录结构,保存成压缩文件包,交给用户。
-
动态链接 开发者可以在编译阶段选择可执行文件连接外部函数库的方式,到底是静态连接(编译时连接),还是动态连接(运行时连接)。
进程状态
在多进程程序系统中,进程在处理器上交替运行,在运行、就绪和阻塞3种基本状态之间不断地发生变化。由于进程的不断创建,系统资源(特别是主存资源)已不能满足进程运行的要求。此时就必须将某些进程挂起,对换到磁盘镜像区,暂时不参与进程调度,以平衡系统负载的目的。如果系统出现故障,或者是用户调试程序,也可能需要将进程挂起检查问题。 所谓挂起状态,实际上就是一种静止的状态。一个进程被挂起后,不管它是否在就绪状态,系统都不分配给它处理机(区别于阻塞状态)。这样进程的三态模型(执行、就绪、阻塞)就变为五态模型:运行状态、活动就绪状态、静止就绪状态、活动阻塞状态和静止阻塞状态
-
活动就绪:指进程在主存并且可被调度的状态 (对应于三态的就绪状态)
-
静止就绪:指进程被对换到辅存时的就绪状态,是不能被直接调度的状态,只有当主存中没有活动就绪态进程,或者是挂起态进程具有更高的优先级,系统将把挂起就绪态进程调回主存并转换为活动就绪。
-
活动阻塞:指进程在主存中。一旦等待的事件产生,便进入活动就绪状态(对应于三态的阻塞状态)
-
静止阻塞:指进程对换到辅存时的阻塞状态。一旦等待的事件产生,便进入静止就绪状态。
Linux ext2和ext3文件系统的区别
Linux文件系统 Linux ext2/ext3文件系统使用索引节点来记录文件信息。索引节点是一个结构,它包含了一个文件的长度、创建及修改时间、权限、所属关系、磁盘中的位置等信息。一个文件系统维护了一个索引节点的数组,每个文件或目录都与索引节点数组中的唯一一个元素对应。系统给每个索引节点分配了一个号码,也就是该节点在数组中的索引号,称为索引节点号。
Linux文件系统将文件索引节点号和文件名同时保存在目录中。所以,目录只是将文件的名称和它的索引节点号结合在一起的一张表,目录中每一对文件名称和索引节点号称为一个连接。 对于一个文件来说有唯一的索引节点号与之对应,对于一个索引节点号,却可以有多个文件名与之对应。因此,在磁盘上的同一个文件可以通过不同的路径去访问它。
Linux缺省情况下使用的文件系统为ext2,ext2文件系统的确高效稳定。但是,随着Linux系统在关键业务中的应用,Linux文件系统的弱点也渐渐显露出来:其中系统缺省使用的ext2文件系统是非日志文件系统。这在关键行业的应用是一个致命的弱点。
ext3文件系统是直接从Ext2文件系统发展而来,目前ext3文件系统已经非常稳定可靠。它完全兼容ext2文件系统。用户可以平滑地过渡到一个日志功能健全的文件系统中来。这实际上了也是ext3日志文件系统初始设计的初衷。
ext3日志文件系统的特点
- 高可用性
系统使用了ext3文件系统后,即使在非正常关机后,系统也不需要检查文件系统。宕机发生后,恢复ext3文件系统的时间只要数十秒钟。
- 数据的完整性:
ext3文件系统能够极大地提高文件系统的完整性,避免了意外宕机对文件系统的破坏。在保证数据完整性方面,ext3文件系统有2种模式可供选择。其中之一就是同时保持文件系统及数据的一致性模式。采用这种方式,你永远不再会看到由于非正常关机而存储在磁盘上的垃圾文件。
- 文件系统的速度
尽管使用ext3文件系统时,有时在存储数据时可能要多次写数据,但是,从总体上看来,ext3比ext2的性能还要好一些。这是因为ext3的日志功能对磁盘的驱动器读写头进行了优化。所以,文件系统的读写性能较之ext2文件系统并来说,性能并没有降低。
- 数据转换
由ext2文件系统转换成ext3文件系统非常容易,只要简单地键入两条命令即可完成整个转换过程,用户不用花时间备份、恢复、格式化分区等。用一个ext3文件系统提供的小工具tune2fs,它可以将ext2文件系统轻松转换为ext3日志文件系统。另外,ext3文件系统可以不经任何更改,而直接加载成为ext2文件系统。
- 多种日志模式
ext3有多种日志模式,一种工作模式是对所有的文件数据及metadata(定义文件系统中数据的数据,即数据的数据)进行日志记录(data=journal模式);另一种工作模式则是只对metadata记录日志,而不对数据进行日志记录,也即所谓data=ordered或者data=writeback模式。系统管理人员可以根据系统的实际工作要求,在系统的工作速度与文件数据的一致性之间作出选择。
乐观锁与悲观锁
悲观锁
悲观锁(Pessimistic Lock)每次去读数据的时候都认为数据会被其他任务修改,所以会上锁,这样其他任务想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁、表锁、读锁、写锁等,都是在做操作之前先上锁。
乐观锁
乐观锁(Optimistic Lock)每次去读数据的时候都认为别的任务不会修改,所以不会上锁,但是在更新(写)的时候会判断一下在此期间其他任务有没有去更新这个数据(可以使用版本号等机制)。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
僵尸进程
任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个子进程在结束时都要经过的阶段。
如果子进程在exit()之后,父进程没有来得及处理,这时用ps -el命令就能看到子进程的状态是Z。如果父进程能及时处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。
僵尸进程的危害 由于**子进程的结束和父进程的运行是一个异步过程**,即父进程永远无法预测子进程到底什么时候结束。UNIX提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息,就可以得到。这种机制就是: 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。 但是仍然为其保留一定的信息(包括进程号、退出状态、运行时间等)。直到父进程通过wait/waitpid来取时才释放。但这样就导致了问题,如果进程不调用wait/waitpid的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程。此即为僵尸进程的危害,应当避免。
分页和分段
-
页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率。或者说,分页仅仅是由于系统管理的需要而不是用户的需要。段则是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好地满足用户的需要。
-
页的大小固定且由系统决定,由系统把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而在系统中只能有一种大小的页面;而段的长度却不固定,决定于用户所编写的程序,通常由编译程序在对源程序进行编译时,根据信息的性质来划分。
-
分页的作业地址空间是一维的,即单一的线性地址空间,程序员只需利用一个记忆符,即可表示一个地址;而分段的作业地址空间则是二维的,程序员在标识一个地址时,既需给出段名, 又需给出段内地址。
后台进程与守护进程
-
最直观的区别:守护进程没有控制终端,而后台进程还有。如通过命令
firefox &在后台运行firefox,此时firefox虽然在后台运行,但是并没有脱离终端的控制,如果把终端关掉则firefox也会一起关闭。 -
后台进程的文件描述符继承自父进程,例如shell,所以它也可以在当前终端下显示输出数据。但是守护进程自己变成进程组长,其文件描述符号和控制终端没有关联,是控制台无关的。
-
守护进程肯定是后台进程,但后台进程不一定是守护进程。基本上任何一个程序都可以后台运行,但守护进程是具有特殊要求的程序,比如它能够脱离自己的父进程,成为自己的会话组长等(这些需要在程序代码中显式地写出来)。
查看僵尸进程
ps -el,查看S状态:
-
Z:僵尸进程 -
S:休眠状态 -
D:不可中断的休眠状态 -
R:运行状态 -
T:停止或跟踪状态
僵尸进程变为孤儿进程
父进程死后,僵尸进程成为”孤儿进程”,过继给1号进程init,init会负责清理僵尸进程。
查看Linux进程之间的关系
ps -o pid,pgid,ppid,comm | cat
输出:
PID PGID PPID COMMAND
3003 3003 2986 su
3004 3004 3003 bash
3423 3423 3004 ps
3424 3423 3004 cat
每个进程都会属于一个进程组(process group),每个进程组中可以包含多个进程。进程组会有一个组长进程 (process group leader),组长进程的PID成为进程组的ID (process group ID, PGID),以识别进程组。PID为进程自身的ID,PGID为进程所在的进程组的ID, PPID为进程的父进程ID。
协程理解
普通程序调用的执行方式 子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。 所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。子程序调用总是一个入口,一次返回,调用顺序是明确的。
协程的执行方式 协程 又称微线程,纤程。英文名Coroutine。 **协程的调用和子程序(函数调用)不同**。 协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序(**是中断后执行,而不是函数调用其他的子程序**),在适当的时候再返回来接着执行。
优点 协程的特点在于是一个线程执行(所以不是多线程)。优势就是极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。另一个优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
缺点
- 无法利用多核资源:协程的本质是个单线程,它不能同时将单个CPU的多个核用上,协程需要和进程配合才能运行在多CPU上。当然日常所编写的绝大部分应用都没有这个必要,除非是CPU密集型应用。
- 进行阻塞操作会阻塞掉整个程序:这一点和事件驱动一样,可以使用异步IO操作来解决。
死锁产生的四个必要条件
- 互斥条件:一个资源每次只能被一个进程使用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件。只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
Linux用户身份切换
将一般用户变成root:
[test@test test]$ su
将身份变成username的身份:
[root @test /root ]# sudo [-u username] [command]
root可以执行test用户的指令,建立test的文件不需要root的密码仍可以执行root的工具,这时就可以使用sudo。由于执行root身份的工作时,输入的密码是用户的密码,而不是root的密码,所以可以减少root密码外泄的可能性。
查看系统负载
通过查看/proc/loadavg可以了解到运行队列的情况:
cat /proc/loadavg
1.63 0.48 0.21 10/200 17145
其中:
- 1.63 0.48 0.21是不同时间内(最近1分钟、5分钟、15分钟)的系统负载,是**单位时间内运行队列中就绪等待的进程数的平均值**,如果值为0,说明每个进程只要就绪后就可以马上获得CPU,无需等待,这时系统的响应速度最快。
- 10/200中的10代表此时运行队列中的进程个数,而200代表此时的进程总数。
- 17145代表最后创建的一个进程ID。
- 也可以通过top命令或者w命令来获得系统负载,它们其实仍然来自于/proc/loadavg。
IOWait
指CPU空闲并且等待I/O操作完成的时间比例。
DMA(Direct Memory Access)
一开始磁盘和内存之间的数据传输是由CPU控制的,即数据需要经过CPU存储转发,这种方式称为PIO。后来有了DMA(Direct Memory Access),可以**不经过CPU而直接进行磁盘和内存的数据交换**。CPU只需要向DMA控制器下达指令,让其处理数据传送,DMA控制器**使用系统总线**传输数据,完毕后再通知CPU。
同步阻塞I/O与同步非阻塞I/O
同步阻塞I/O指当进程调用某些涉及I/O操作的系统调用或函数库时(accept()、send()、recv()等),进程暂停,等待I/O操作完成后再继续运行。 同步非阻塞I/O的调用不会等待数据的就绪,如果数据不可读或者不可写,它会立即告诉进程。相比于阻塞I/O这种非阻塞I/O结合反复轮询来尝试数据是否就绪,最大的好处是便于在一个进程里同时处理多个I/O操作。缺点在于会花费大量的CPU时间,使得进程处于忙碌等待状态。 非阻塞I/O一般只对网络I/O有效,比如在socket的选项中设置O_NONBLOCK。
多路I/O就绪通知的各种实现
多路I/O就绪通知允许进程通过一种方法来同时监视所有文件描述符,并可以快速获得所有就绪的文件描述符,然后只对这些文件描述符进行数据访问。 I/O就绪通知只是有助于快速获得就绪的文件描述符,当得知数据就绪后,就访问数据本身而言,仍然需要选择阻塞或者非阻塞的访问方式。
-
select 监视包含多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符会被修改标志位使得进程可以获得这些文件描述符从而进行后续的读写操作。有点在于几乎所有平台都支持,缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上为1024,假如维持的连接已达上限,新的连接请求将被拒绝。此外,select所维护的数据结构复制开销较大,对于非活跃状态的TCP连接也会进行线性扫描等,也是缺陷。
-
poll 本质上和select没有太大区别(实现者不同),包含大量文件描述符的数组被整体复制于用户态和内核态的地址空间,而不论这些文件描述符是否就绪,但是poll没有最大文件描述符的数量限制。
-
SIGIO 通过实时信号来通知,不同于select/poll,对于变为就绪状态的文件描述符,SIGIO只通知一遍。所以存在事件丢失的情况,需要采用其他方法弥补。
-
/dev/poll 使用虚拟的/dev/poll设备,可以将要监视的文件描述符数组写入这个设备,然后通过ioctl()来等待事件通知,当ioctl()返回就绪的文件描述符后,可以从/dev/poll中读取所有就绪的文件描述符数组,节省了扫描所有文件描述符的开销。
-
/dev/epoll 在/dev/poll的基础上增加了内存映射(mmap)的技术
-
epoll Linux2.6中由内核直接支持的实现方法,公认的Linux2.6下性能最好的多路I/O就绪通知方法。 epoll的本质改进在于其基于事件的就绪通知方式,事先通过epoll_ctl()来注册每一个文件描述符,一旦某个文件描述符就绪时,内核会采用类似callback的回调机制迅速激活这个文件描述符,当进程调用epoll_wait()时得到通知,获得就绪的文件描述符的数量的值,然后只需要去epoll指定的数组中依次取得相应数量的文件描述符即可。
-
kqueue 性能和epoll接近,但很多平台不支持。
直接I/O
在Linux2.6中,内存映射和直接访问文件没有本质上的差异,因为数据从进程用户态内存空间到磁盘都要经过两次复制:磁盘到内核缓冲区、内核缓冲区到用户态内存空间。 对于一些复杂的应用,比如数据库服务器,为了提高性能希望绕过内核缓冲区由自己在用户态空间实现并管理I/O缓冲区以支持独特的查询机制。Linux提供了对这种需求的支持,即在open()系统调用中添加参数O_DIRECT,有效避免CPU和内存的多余时间开销。
同步和异步、阻塞和非阻塞概念理解
同步和异步、阻塞和非阻塞修饰的是不同的对象。 阻塞和非阻塞指当进程访问的数据未就绪时,进程是直接返回还是继续等待。 同步和异步指访问数据的机制,同步指主动请求并等待I/O操作完毕,在数据就绪后,读写时必须阻塞。异步指主动请求数据后便可以继续处理其他任务,随后等待I/O操作完毕的通知,使得进程在数据读写时也不发生阻塞。
rsync
SCP和WebDAV属于主动分发方式的文件复制,Linux的rsync工具属于被动同步的方式,即接收文件的一端主动向服务器发起同步请求,并根据两端文件列表的差异有选择地进行更新。 可以配置crontab脚本定期同步。
inotify
Linux的inotify模块基于Hash Tree(即一旦某个文件发生更新,就更新从它开始至根目录的整个路径上的所有目录)来监控文件的更改,以此提高文件更新的效率。原生提供C语言的API,PECL有相应的扩展。
电子电路对计算机信息的表示
在硬件设计中用电子电路来计算和存储位,大多数现代电路技术都是用信号线上的高低电压来表示不同的值,如逻辑1用1v左右的高电压表示,而逻辑0用0v左右低电压表示。要实现一个数字系统需要三个主要的组成部分:对位进行操作的组合逻辑、存储位的存储器元素、控制存储器元素更新的时钟信号。
硬件控制语言HCL用来描述不同处理器设计的控制逻辑。HCL表达式可以清楚地表明组合逻辑电路和C语言中逻辑表达式(&&、||、!等)的对应之处。 逻辑门是数字电路的基本计算元素,它们产生的输出等于它们输入位值的某个布尔函数。(图略) 很多逻辑门组合成一个网,就能构建计算块,称为组合电路。 通过将逻辑门组合成更大的网,可以构造出能计算更加复杂逻辑的组合电路,比如设计对字进行操作的电路,而不仅仅是对位进行操作。组合逻辑电路可以设计成在字级数据上执行许多不同类型的操作。算术逻辑单元ALU是一种组合电路,这个电路有3个输入:两个数据输入和一个控制输入,根据控制输入的设置,电路会对数字输入执行不同的算术或逻辑操作。组合电路可以实现将一个信号与多个可能匹配信号的比较,以此来检测正在处理的某个指令代码是否属于某一类指令代码。
组合电路不存储任何信息,为了产生时序电路,即有状态且在这个状态上进行计算的系统,必须引入按位存储信息的设备。存储设备都是由同一个时钟控制,时钟周期性发出信号决定什么时候要把新值加载到设备中。
寄存器文件有两个读端口和一个写端口,这样一个多端口随机访问存储器允许同时进行多个读和写操作,比如可以读两个程序寄存器的值,同时更新第三个寄存器的状态。
Y86处理器顺序执行指令的步骤
- 取指:从存储器读取指令字节,地址为程序计数器PC的值。取出的长度取决于具体指令的字节编码,然后按顺序方式计算当前指令的下一条指令的地址(等于PC的值加上已取出指令的长度)。
- 译码:从寄存器文件读入最多两个操作数,通常读入rA和rB字段指明的寄存器,不过有些指令是读寄存器%esp的。
- 执行:ALU要么执行指令指明的操作(根据ifun值),计算存储器引用的有效地址,要么增加或者减少栈指针。在此,也可能设置条件码。对于跳转指令,这个阶段会验证条件码和(ifun给出的)分支条件,看是不是应该选择分支。
- 访存:将数据写入存储器或者从存储器中读出。
- 写回:最多可以写两个结果到寄存器文件。
- 更新PC:将PC设置为下一条指令的地址。 发生任何异常时,处理器就会停止:执行halt指令或非法指令。
一个时钟变化会引发一个经过组合逻辑的流来执行整个指令。
指令集与流水线化处理器
顺序处理器的问题在于太慢了,时钟必须非常慢,以使信号能在一个周期内传播所有的阶段(对应不同的硬件单元)。这种实现方式不能充分利用硬件单元。
流水线化可以增加系统的吞吐量,即单位时间内服务的总用户数。但是对单个用户而言,则会轻微地增加延迟(从头到尾执行一条指令所需要的时间称为延迟)。
相邻指令之间很可能是相关的,可以通过引入含有反馈路径的流水线系统来解决。
CPU能够执行的指令被编码为一个或多个字节序列组成的二进制格式,一个CPU能够执行的所有指令和指令的字节级编码被称为它的指令集体系结构(ISA Instruction-Set Architecture)。
ISA模型看上去应该是顺序执行指令,但是现代处理器的实际工作方式并非如此:通过同时处理多条指令的不同部分,处理器可以获得较高的性能(流水线化处理器)。为了保证处理器能达到同顺序执行相同的结果,处理器又采取了一些特殊的机制。
SRAM、DRAM、RPM、PROM、EPROM、EEPROM
随机访问存储器(Random Access Memory)分为两类:静态的和动态的。静态的(SRAM)比动态的(DRAM)更快,也更贵。SRAM用来做高速缓存,DRAM用来做主存及图形系统的帧缓冲区。
SRAM将每个位存储在一个双稳态的存储器单元里,每个单元是一个六晶体管电路,这个电路有这样一个属性:它可以无限期地保持在两个不同的电压状态之一,其他任何状态都是不稳定的。只要有电,它就会永远地保持它的值。
DRAM将每一位存储为一个电容,与SRAM不同的是,DRAM存储器单元对干扰非常敏感,暴露在光线下也会导致电容电压改变,当电容电压被扰乱后,它就永远不会恢复了。存储器系统必须周期性地通过读出,然后重写来刷新存储器的每一位。
SRAM与DRAM的比较:
每位晶体管数 相对访问时间 是否持续 是否敏感 相对花费
SRAM 6 1 是 否 100
DRAM 1 10 否 是 1
SRAM和DRAM在断电后都会丢失信息,因此它们都属于易失的。非易失性存储器即使在断电后也仍然能够保存它们的信息,通常指ROM。由于历史原因,虽然ROM中有的类型既可以读也可以写,但是它们整体上都称为只读存储器ROM。
PROM指可以进行一次编程的ROM,PROM的每个存储器单元有一种熔丝,它只能用高电流熔断一次。
EPROM指可擦写可编程ROM,有一个透明的石英窗口,允许光到达存储单元,紫外线照射后,EPROM单元就被清除为0.对其写入1需要使用特殊的设备来完成。EPROM能够被擦除和重编程的次数大概为1000次。
EEPROM指电子可擦除PROM,类似于EPROM,但是它不需要一个物理上独立的编程设备,且可编程次数超过10万次。
闪存基于EEPROM。
固件(firmware)指存储在ROM中的程序,当计算机通电后,会运行存储在ROM中的固件,如BIOS。复杂的设备,如显卡、磁盘控制器也依赖固件翻译来自CPU的I/O请求。
总线是一种共享电子电路,数据流通过总线在处理器和DRAM之间来回传送。如:
磁盘(略)
固态硬盘(Solid State Disk)是一种基于闪存的存储技术。
存储器层次结构
寄存器 -> L1高速缓存 -> L2高速缓存 -> L3高速缓存 -> 主存 -> 本地磁盘 -> 远程存储
异常处理与过程(函数)调用的区别
异常处理类似于过程调用,但又有一些不同之处:
- 过程调用在跳转到处理程序之前,处理器会将返回地址压入栈中,而异常的返回地址则会根据类型可能是当前指令,也可能是下一条指令。
- 处理器会把处理器状态压到用户栈里以便在处理程序返回时重新开始被中断的程序。如果异常控制从一个用户程序转移到内核,那么所有这些项目都被压到内核栈中,而不是压到用户栈中。
- 异常处理程序运行在内核模式下,因此它们对所有的系统资源都有完全的访问权限。
一旦硬件触发了异常,剩下的工作就由异常处理程序在软件中完成,在处理程序处理完事件之后,它通过执行一条特殊的“从中断返回”指令,可选地返回到被中断的程序,该指令将适当的状态弹回到处理器的控制和数据寄存器中,如果异常中断的是一个用户程序,就将状态恢复为用户模式,然后将控制返回给被中断的程序。
地址翻译
当页命中时,CPU硬件的执行步骤如下:
-
- 处理器生成一个虚拟地址,并把它传送给MMU;
-
- MMU生成PTE地址,并从高速缓存/主存中请求得到它;
-
- 高速缓存/主存向MMU返回PTE;
-
- MMU构造物理地址,并把它传送给高速缓存/主存;
-
- 高速缓存/主存返回所请求的数据字给处理器; 可见页命中完全是由硬件处理的。
当缺页时,需要硬件和操作系统内核协作完成,步骤如下:
-
- 处理器生成一个虚拟地址,并把它传送给MMU;
-
- MMU生成PTE地址,并从高速缓存/主存中请求得到它’
-
- 高速缓存/主存向MMU返回PTE;
-
- PTE中的有效位为零,所以MMU触发一次异常,传递CPU中的控制到操作系统内核中的缺页异常处理程序;
-
- 缺页处理程序确定出物理存储器中的牺牲页,如果这个页已经被修改了,则把它换出到磁盘;
-
- 缺页处理程序调入新的页,并更新存储器中的PTE;
-
- 缺页处理程序返回到原来的进程,再次执行导致缺页的指令,CPU将引起缺页的虚拟地址重新发送给MMU。因为虚拟页面现在缓存在物理存储器中,所以就会被命中,主存会将所请求的字返回给处理器。
在MMU中包括了一个关于PTE的小的缓存,称为TLB(翻译后备缓冲器)。在有TLB,且TLB命中的情况下,CPU的执行步骤如下:
-
- 处理器生成一个虚拟地址,并把它传送给MMU;
-
- MMU从TLB中取出相应的PTE;
-
- MMU构造物理地址,并把它传送给高速缓存/主存;
-
-
高速缓存/主存返回所请求的数据字给处理器;
-
内核空间、系统空间、系统调用、中断概念
-
内核空间:内核独立于普通应用程序,拥有受保护的内存空间和访问硬件设备的所有权限。
-
用户空间:应用程序在用户空间执行,只能看到允许它们使用的部分系统资源,并且只使用某些特定的系统功能,不能直接访问硬件,也不能访问内核划给别人的内存空间。当内核运行的时候,系统以内核态进入内核空间执行,而执行一个普通用户程序时,系统将以用户态进入用户空间执行。
-
系统调用:应用程序通过系统调用来与内核通信,通常调用库函数,再由库函数通过系统调用界面让内核代其完成各种不同任务(比如调用C库函数printf(),该库函数会格式化数据后调用内核的write()函数将数据写到控制台上)。在这种情况下,应用程序被称为通过系统调用在内核空间运行,而内核被称为运行于进程上下文中,这是应用程序完成其工作的基本行为方式。
-
中断:内核基于中断机制来管理系统的硬件设备,当硬件设备想要和系统通信的时候会首先发出一个异步的中断信号去打断处理器的执行,继而打断内核的执行。中断对应着一个中断号,内核通过这个中断号查找相应的中断服务程序。中断服务程序不在进程上下文中执行,而是在一个与所有进程都无关的、专门的中断上下文中运行,以此保证中断服务程序能够在第一时间响应和处理中断请求,然后快速地退出。
处理器的运行状态
处理器在任何指定时间点上的活动必然属于以下三种情况之一:
-
运行于用户空间,执行用户进程;
-
运行于内核空间,处于进程上下文,代表某个特定的进程执行;(CPU空闲时,内核执行空进程)
-
运行于内核空间,处于中断上下文,与任何进程无关,处理某个特定的中断;
单内核和微内核
-
单内核:将内核从整体上作为一个单独的大过程来实现,同时也运行在一个单独的地址空间上。这样的内核以单个静态二进制文件的形式存放于磁盘中,内核之间通信的开销微不足道,因为可以直接调用函数,大多数Unix系统都设计为单内核。
-
微内核:内核的功能被划分为多个独立的过程,每个过程称为一个服务器,所有服务器都保持独立并运行在各自的地址空间上。因此不能像单内核那样直接调用函数,而是通过消息传递来处理内核通信(IPC),消息传递需要一定的周期,其开销大于函数调用。优点在于避免了因为一个服务的失效祸及另一个。Windows NT和Mach都是设计为微内核。 Linux是一个单内核,但是在具体设计上也汲取了微内核的精华,比如模块化设计、抢占式内核、支持内核线程以及动态装载内核模块的能力。
Linux与Unix的差异
-
Linux支持动态加载内核模块;(尽管Linux内核也是单内核)
-
Linux支持对称多处理机制(SMP);(每个处理器有相等的机会读/写存储器,也有相同的访问速度)
-
Linux内核可以抢占;
-
Linux内核不区分线程和一般进程;
-
Linux提供面向对象的设备模型、热插拔事件,以及用户空间的设备文件系统;
-
Linux忽略了一些设计拙劣的Unix特性,如STREAMS;
进程、线程
进程是处于执行期的程序以及相关的资源的总称。 线程是在进程中活动的对象,每个线程都拥有一个独立的程序计数器、进程栈和一组进程寄存器。 Linux不特别区分进程和线程,线程被当做一种特殊的进程对待,内核调度的对象是线程而不是进程。
进程状态
task_struct中的state域描述了进程的当前状态,有5种情况:
-
TASK_RUNNING:进程是可执行的,它或者正在执行,或者在运行队列中等待执行,这是进程在用户空间中执行的唯一可能的状态,也可以应用到内核空间中正在执行的进程。
-
TASK_INTERRUPTIBLE:进程是可中断的,进程被阻塞等待某些条件的达成,一旦这些条件达成,内核会把进程状态设置为可执行。
-
TASK_UNINTERRUPTIBLE:进程是不可中断的,处于此状态的进程对信号不做响应。
-
__TASK_TRACED:被其他进程跟踪的进程,例如正在被调试程序跟踪。
-
__TASK_STOPPED:进程停止执行,进程没有投入运行也不能投入运行,通常发生在接收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU等信号的时候,此外在调试期间接收到任何信号都会使进程进入这种状态。
进程上下文切换
可执行程序代码从一个可执行文件载入到进程的地址空间执行,将运行在用户空间。当程序执行了系统调用,或者触发了某个异常,它就陷入了内核空间,此时称内核代表进程执行,并处于进程上下文中。在此上下文中current宏是有效的。除非在此期间有更高优先级的进程需要执行,并由调度器做出了相应调整,否则在内核退出的时候,程序恢复在用户空间会继续执行。
写时拷贝
传统的fork()系统调用直接把所有的资源复制给新创建的进程,这种实现效率低下,因为也许拷贝的数据并不共享。Linux的fork()使用写时拷贝,即不复制整个进程的地址空间,而是让父进程和子进程共享同一个拷贝,只有在需要写入的时候,数据才会被复制,在此之前只以只读方式共享。在页根本不会被写入的情况下,如fork()后立即exec(),它们就无须复制了。
线程在Linux中的实现
从内核角度来说,Linux并没有线程这个概念,Linux把所有的线程都当做进程来实现,内核并没有准备特别的调度算法或是定义特别的数据结构来表征线程,**线程仅仅被视为一个与其他进程共享某些资源的进程**。每个线程都拥有自己的task_struct,所以在内核中它看起来就像是一个普通的进程,只是线程和其他一些进程共享某些资源(创建线程时指定),如地址空间。对于Linux来说,它只是一种进程间共享资源的手段。 线程的创建与普通进程的创建类似,只不过在调用clone()的时候需要传递一些参数标志来指明需要共享的资源,如共享地址空间、文件系统资源、文件描述符: clone( CLONE_VM | CLONE_FS | CLONE_FILES, 0);
内核线程
内核通过内核线程实现在后台执行一些操作,内核线程即独立运行在内核空间的标准进程,与普通的进程的区别在于内核线程没有独立的地址空间(指向地址空间的mm指针被设为NULL),它们只能在内核空间运行,不能切换到用户空间去。可以被调度、可以被抢占。 运行ps -ef可以看到内核线程。
孤儿进程
如果父进程在子进程之前退出,必须有机制来保证子进程能够找到一个新的父进程,否则这些成为孤儿的进程就会在退出时永远处于僵死状态,白白耗费内存。对于这个问题解决方法是给子进程在当前线程组内找一个线程作为父亲,如果不行,就让init做其父进程。init进程会例行调用wait()来检查其子进程,清除所有与其相关的僵死进程。
完全公平调度算法(CFS)
Linux自2.6.23内核版本开始使用称为完全公平调度算法的进程调度算法,该算法不直接分配时间片到进程,而是将处理器的使用比划分给进程,因此进程所获得的处理器时间和系统的负载密切相关。nice值(-20到+19)不再像标准Unix系统那样用来表示优先级,而是作为权重来影响进程的处理器使用比例,具有高nice值的进程将被赋予低权重,从而丧失一小部分处理器使用比。 Linux系统是抢占式的,其抢占时机取决于新的可运行程序消耗了多少处理器使用比,如果消耗的使用比比当前进程小,则新进程立刻投入运行,抢占当前进程。否则将推迟其运行。 CFS不再有时间片的概念,但是也必须维护每个进程运行时间的记账,以此确保每个进程只在公平分配给它的处理器时间内运行。CFS使用调度器实体结构struct sched_entity来跟踪进程运行并记账。sched_entity在task_struct中以一个名为se的成员变量被嵌入。在sched_entity中有一个名为vruntime的变量用来存放进程的虚拟运行时间,该运行时间称为虚拟实时,其值的计算是经过了所有可运行进程总数的标准化,即被加权的,单位为ns,因此和定时器的节拍不相关。CFS使用vruntime变量来记录一个程序到底运行了多长时间以及它还应该再运行多久。 CFS试图利用一个简单规则去均衡进程的虚拟运行时间,当要选择下一个运行进程时,它会挑一个具有最小vruntime的进程,这也是CFS调度算法的核心。CFS使用红黑树(rbtree)来组织可运行的进程队列,并利用其找到最小vruntime值的进程。
睡眠和唤醒
睡眠即被阻塞,此时进程处于一个特殊的不可执行的状态,进程把自己标志成睡眠状态,从可执行红黑树中移除,放入等待队列,然后调用schedule()选择和执行一个其他进程。唤醒的过程则相反,进程被设置为可执行状态,然后再从等待队列中移到可执行二叉树中。
上下文切换
上下文切换,即从一个可执行进程切换到另一个可执行进程,由context_switch()函数负责处理。每当一个新的进程被选出来准备投入运行的时候,schedule()就会调用该函数,它完成两项基本的工作:
- 调用switch_mm(),把虚拟内存从上一个进程映射切换到新进程中;// 切换虚拟内存
- 调用switch_to(),从上一个进程的处理器状态切换到新进程的处理器状态,包括保存、恢复栈信息和寄存器信息,以及其他任何与体系结构相关的状态信息。 // 切换处理器状态
用户抢占、内核抢占
每个进程都包含一个need_resched标志,用来表明是否需要重新执行一次调度。当某个进程应该被抢占时,scheduler_tick()会设置这个标志;当一个优先级高的进程进入可执行状态时,try_to_wake_up()也会设置这个标志。内核会检查该标志(如返回用户空间以及从中断返回的时候),确认其被设置,然会调用schedule()来切换到一个新的进程。
-
用户抢占 在从系统调用或者中断处理程序返回用户空间时,如果need_resched标志被设置,会导致schedule()被调用,内核会选择一个其他(更合适的)进程投入运行,即发生用户抢占。即用户抢占发生在: 从系统调用返回用户空间时; 从中断处理程序返回用户空间时;
-
内核抢占 Linux支持内核抢占,前提是重新调度是安全的。只要进程没有持有锁,就是安全的。具体实现就是在每个进程的thread_info中引入preempt_count计数器,初始为0,每当使用锁的时候+1,释放锁的时候-1,当数值为0时,内核就可以抢占。从中断返回内核空间时,内核会检查need_resched和preempt_count的值,以决定是调用调度程序(内核抢占)还是返回执行进程。如果内核中的进程被阻塞了,或者它显式地调用了schedule(),内核抢占也会显式地发生。即内核抢占会发生在: (1)中断处理程序正在执行,且返回内核空间之前; (2)内核代码再一次具有可抢占性的时候; (3)内核中的任务显式调用schedule(); (4)内核中的任务阻塞(这同样也会导致调用schedule());
应用程序、C库和内核之间的关系
在Linux中,系统调用是用户空间访问内核的唯一手段,除异常和陷入外,它们是内核唯一的合法入口。一般情况下,应用程序通过在用户空间实现的应用编程接口(API),而不是直接通过系统调用来编程。调用printf()函数时,应用程序、C库和内核之间的关系:
 用户程序通过包含标准头文件并和C库链接,就可以使用系统调用。
用户程序通过包含标准头文件并和C库链接,就可以使用系统调用。
中断相关概念
中断机制 处理器的速度跟外围的硬件设备不在一个数量级上,因此提供一种机制让硬件在需要的时候向内核发出信号。
中断 本质上是一种特殊的电信号,由硬件设备生成,并直接送入中断控制器(简单的电子芯片)的输入引脚中,中断控制器采用复用技术将多路中断管线只通过一个和处理器相连接的管线与处理器通信。处理器一经检测到此信号,便中断自己的当前工作转而处理中断。硬件设备生成中断的时候并不考虑与处理器的时钟同步,即中断随时可以产生,因此内核随时可能因为新到来的中断而被打断。
中断请求线(IRQ)每个中断都通过一个唯一的数字标志,这样操作系统才能够给不同的中断提供对应的中断处理程序。这些中断值即中断请求线,例如IRQ 0是时钟中断、IRQ 1是键盘中断。对于连接在PCI总线上的设备而言,中断请求线是动态分配的。
中断与异常的区别 异常与中断不同,中断是由硬件引起的,异常则发生在编程失误而导致错误指令,或者在执行期间出现特殊情况必须要靠内核来处理的时候(比如缺页)。它在产生时必须考虑与处理器时钟同步,因此异常也称同步中断。
中断处理程序 产生中断的每个设备都有一个相应的中断处理程序,一个设备的中断处理程序是它设备驱动程序的一部分(设备驱动程序是用于对设备进行管理的内核代码),在响应一个特定中断的时候,内核会执行特定的中断处理程序(驱动程序事先通过request_irq()注册中断处理程序)。在Linux中中断处理程序就是C函数,这些C函数按照特定类型声明,以便内核能够按照标准的方式传递处理程序的信息,中断处理程序要负责通知硬件设备中断已经被接收。
中断处理程序与其他内核函数的真正区别在于:中断处理程序是被内核调用来响应中断的,而它们运行于中断上下文中,中断上下文也称原子上下文,该上下文中执行的代码不可阻塞。
中断屏蔽 如果当前有一个中断处理程序正在执行,根据注册中断处理程序是设置的参数的不同,屏蔽情况也不同: 如果没有设置IRQF_DISABLED,与该中断同级的其他中断都会被屏蔽; 如果设置了IRQF_DISABLED,当前处理器上所有其他中断都会被屏蔽;
上半部与下半部 中断处理程序运行需要快速执行(因为不可阻塞),同时要能完成尽可能多的工作,这里存在矛盾。因此把中断处理切分为两个部分,上半部分(top half)接收到一个中断后立即执行,但是只做有严格时限的工作,例如对接收到的中断进行应答或复位硬件。能够被允许稍后完成的工作会推迟到下半部分(bottom half)去,此后在合适的时机下半部分会被中断执行,Linux提供了实现下半部分的各种机制。
查看处理器中断统计信息 cat /proc/interrupts
划分工作为上半部或下半部的基本规则
-
如果一个任务对时间非常敏感,将其放在上半部;
-
如果一个任务和硬件相关,将其放在上半部;(例如从网卡的缓存中拷贝数据)
-
如果一个任务要保证不被其他中断(特别是相同的中断)打断,将其放在上半部;
-
其他所有任务考虑放在下半部;
下半部的实现机制
下半部执行的关键在于当它们运行的时候,允许响应所有的中断。至于具体的执行时间并不确定,只是为了把一些任务推迟一点,让它们在系统不太繁忙并且中断恢复后执行就可以了。通常下半部在中断处理程序一返回就会马上运行。 和上半部只能通过中断处理程序实现不同,下半部可以通过多种机制实现:
-
最早的BH机制:提供一个静态创建、由32个bottom halves组成的链表,上半部通过一个32位整数中的一位来标识出哪个bottom half可以执行;这种机制简单但不够灵活,存在性能瓶颈;
-
任务队列:内核定义一组队列,其中每个队列都包含一个由等待调用的函数组成的链表,驱动程序可以把自己的下半部注册到合适的队列上去;这种机制无法替代整个BH接口,对于性能要求较高的子系统(比如网络)也不能胜任;
-
软中断和tasklet:这里的软中断指一组静态定义的下半部接口,共32个,可以在所有处理器上同时执行,软中断必须在编译期间就进行静态注册(最多只能注册32个,当前内核已使用9个)。tasklet是一种基于软中断实现的灵活性强、动态创建的下半部实现机制,其实是一种在性能和易用性之间寻求平衡的产物,对于大部分下半部处理来说,使用tasklet就足够了,对于网络这种性能要求较高的情况才需要使用软中断;
-
定时器:不同于其他实现方式,定时器可以把操作推迟到某个确定的时间段之后执行;
软中断的实现
软中断保留给系统中对时间要求最严格以及最重要的下半部使用,目前只有两个子系统(网络、SCSI)直接使用软中断。此外,tasklet和内核定时器都是建立在软中断上的。 软中断是在编译期间静态分配的,不像tasklet那样能够被动态地注册或注销。软中断由softirq_action结构表示。softirq_vec数组是一个包含32个该结构体的数组,每个被注册的软中断都占据该数组的一项,因此最多可能有32个软中断,在当前版本的内核中这32个项中只用到了9个。 当内核运行一个软中断处理程序的时候,会执行softirq_handler()函数,其唯一的参数是指向softirq_vec某个softirq_action结构体的指针。 一个注册的软中断必须在被标记后才会执行,中断处理程序在返回前会标记它的软中断。在下列场景待处理的软中断会被检查和执行:
- 从一个硬件中断代码处返回时;
- 在ksoftirqqd内核线程中;
- 在那些显式检查和执行待处理的软中断的代码中,比如网络子系统;
软中断最终在do_softirq()中执行,该函数很简单,如果有待处理的软中断,则循环遍历每一个,并调用它们的处理程序。
ksoftirqd线程 对于软中断,内核通常会选择在中断处理程序返回时进行处理,软中断的触发频率有时可能很高,而且处理函数有时还会自行重复触发(当一个软中断执行的时候,它可以重新触发自己以便再次得到执行),此时就会导致用户空间进程无法获得足够的处理器时间,因而处于饥饿状态。为解决该问题,当大量软中断出现的时候,内核会唤醒一组内核线程来处理这些负载,这些线程在最低优先级上运行(nice值为19),以保证它们不会和其他重要任务抢夺资源,但是最终肯定会被执行,这个线程名为ksoftirqd,每个处理器都有一个这样的线程。
工作队列的实现
工作队列可以把工作推后,交由一个内核线程去执行,因此可以运行在进程上下文中,允许重新调度甚至睡眠。因此,当需要用一个可以重新调度的实体来执行下半部处理的时候,比如需要获得大量内存、需要获取信号量、以及需要执行阻塞式的IO操作时,就应该选择工作队列。它是唯一能够在进程上下文中运行的下半部实现机制,也只有它才可以睡眠。 工作队列子系统是一个用于创建内核线程的接口,通过它创建的进程负责执行由内核其他部分排到队列里的任务,它创建的这些内核线程称为工作者线程。驱动程序可以使用工作队列来创建一个专门的工作者线程来处理需要推后的工作。工作队列子系统提供了一个缺省的工作者线程events/n(n为CPU编号),以处理被推后的工作。除非一个驱动程序必须建立一个属于它自己的内核线程,否则最好使用缺省线程。 工作者线程用workqueue_struct表示,该结构内部维护了一个cpu_workqueue_struct的数组,数组的每一项对应系统中一个处理器。所有的工作者线程都是用普通的内核线程实现的,它们都要执行worker_thread()函数,在它初始化完成以后,这个函数执行一个死循环并开始休眠,当有操作被插入到队列里的时候,线程就被唤醒,并执行这些操作。工作用work_struct表示,每个处理器上的每种类型的队列(cpu_workqueue_struct的数组)都有一个该结构的链表,当一个工作者线程被唤醒时,它会执行它链表上的所有工作,执行完毕后就移除该工作,当链表上不再有对象时,它就会继续休眠。
内核中有可能造成并发执行的原因
-
中断:中断几乎可以在任何时刻异步发生,也就可能随时打断当前正在执行的代码;
-
软中断和tasklet:内核能在任何时刻唤醒或者调度软中断和tasklet,打断当前正在执行的代码;
-
内核抢占:因为内核具有抢占性,所以内核中的任务可能会被另一个任务抢占;
-
睡眠及与用户空间的同步:在内核执行的进程可能会睡眠,这就会唤醒调度程序,从而导致另一个新的用户进程执行;
-
对称多处理:两个或者多个处理器可以同时执行代码;
用户空间之所以需要同步,是因为用户程序会被调度程序抢占和重新调度,造成一个程序正处于临界区时被非自愿地抢占了。而新的线程可能会访问同样的临界区。用锁来保护共享资源并不困难,辨认出真正需要共享的数据和相应的临界区才是真正有挑战的地方。
自旋锁
Linux内核中最常见的锁是自旋锁(其他的比如睡眠锁),自旋锁最多只能被一个可执行线程持有,如果一个执行线程试图获得一个已经被持有的自旋锁,那么该线程就会一直进行忙循环-旋转-等待锁重新可用。如果锁未被争用,请求锁的执行线程便能立刻得到它,继续执行。 自旋锁的初衷在于在短期内进行轻量级加锁。因为一个被争用的自旋锁使得请求它的线程在等待锁重新可用时自旋(特别浪费处理器时间),所以自旋锁不应该被长时间持有。还可以采取另外的方式来处理对锁的争用,比如让请求线程睡眠,直到锁重新可用时再唤醒它,这样处理器就不必循环等待,可以去执行其他代码,但这也会带来额外的开销(两次上下文切换)。
自旋锁的实现与体系结构密切相关,代码往往通过汇编实现,基本使用形式如下:
DEFINE_SPINLOCK(mr_lock);
spin_lock(&mr_lock);
/* 临界区 */
spin_unlock(&mr_lock);
自旋锁可以使用在中断处理程序中,在中断处理程序中使用自旋锁时,一定要在获取锁之前首先禁止本地中断(当前处理器上的中断请求),否则中断处理程序就会打断正持有锁的内核代码,有可能会视图去争用这个已经被持有的自旋锁,于是造成死锁。
信号量、互斥信号量、计数信号量
Linux中的信号量是一种睡眠锁,如果有一个任务试图获得一个不可用(已经被占用)的信号量时,信号量会将其推进一个等待队列,然后让其睡眠。此时处理器就可以执行其他代码,当持有的信号量可用后,处于等待队列中的那个任务将被唤醒,并获得该信号量。
互斥信号量和计数信号量 不同于自旋锁,信号量可以同时允许任意数量的锁持有者,同时允许的持有者数量在声明信号量的时候指定,这个值称为使用者数量。使用者为1的信号量和自旋锁一样,在一个时刻仅允许一个锁持有者,这样的信号量称为二值信号量或者互斥信号量。初始化时使用者数量大于1的信号量被称为计数信号量。
信号量支持两个原子操作P()和V(),P操作通过对信号量计数减1来获得一个信号量,如果结果是0或大于0,则获得信号量锁,任务就可以进入临界区,如果结果是负数,任务会被放入等待队列。当临界区执行完成后,V操作用来释放信号量,即将信号量计数加1。
信号量用struct semaphore表示:
/* 创建一个名为mr_sem的信号量 */
struct semaphore mr_sem;
sema_init(&mr_sem,count);
互斥体
互斥体在内核中对应数据结构mutex,其行为与使用计数为1的信号量类似,但操作接口更简单,实现也更高效,而且使用限制更强。引入互斥体的初衷是提供一个更简单的睡眠锁,即一个不需要管理任何使用计数的简化版的信号量。其使用上也有更多的限制:
-
mutex的使用计数永远是1;
-
给mutex上锁者必须负责给其解锁,不能在一个上下文中锁定一个mutex,而在另一个上下文中给他解锁,因此mutex不适合内核同用户空间复杂的同步场景,最常使用的方式是在同一个上下文中上锁和解锁。
-
当持有一个mutex时,进程不可以退出;
-
不能在中断或者下半部中使用;
完成变量
完成变量提供了代替信号量的一个简单的解决方法,由结构completion表示。在一个指定的完成变量上,需要等待的任务调用wait_for_completion()来等待特定事件,当特定事件发生后,产生事件的任务调用complete()来发送信号唤醒正在等待的任务。例如当子进程执行或者退出时,vfork()系统调用使用完成变量唤醒父进程。
顺序锁
简称seq锁,在2.6中引入的一种新型锁,提供了一种很简单的机制,用于读写共享数据,其实现主要依靠一个序列计数器。当有疑义的数据被写入时,会得到一个锁,并且序列值会增加,在读取数据之前和之后,序列号都被读取,如果读取的序列号值相同,说明在读操作进行的过程中没有被写操作打断过。如果读取的值是偶数,就表明写操作没有发生。
jiffies
全局变量jiffies用来记录自系统启动以来产生的节拍的总数。系统启动时内核将该变量初始化为0,此后每次时钟中断处理程序会增加该变量的值,一秒内增加的值即HZ,系统运行时间以秒为单位计算就等于jiffies/HZ。Jiffies定义在文件linux/jiffies.h中:
extern unsigned long volatile jiffies;
常用的一些运算:
unsigned long time_stamp = jiffies; /* 现在 */
unsigned long next_tick = jiffies+1; /* 从现在开始的下一个节拍 */
unsigned long later = jiffies + 5*HZ; /* 从现在开始后的5秒 */
unsigned long fraction = jiffies + HZ/10; /* 从现在开始后的100ms */
因为jiffies使用unsigned long,所以在32位机器上,时钟频率为100HZ的情况下,497天后会溢出,如果频率为1000HZ,49.7天后就会溢出。溢出后其值会绕回到0。内核中提供了四个宏用来帮助比较节拍计数,它们能正确地处理节拍计数回绕的情况。
时钟中断处理程序
时钟中断处理程序可以划分为两个部分:体系结构相关部分和体系结构无关部分。 与体系结构相关的部分作为系统定时器的中断处理程序注册到内核中,以便在产生时钟中断时运行,虽然不同体系结构的具体工作方式不同,但是最低限度也要执行如下工作:
-
- 获得xtime_lock锁,以便对访问jiffies和墙上时间xtime进行保护
-
- 需要时,应答或者重新设置系统时间;
-
- 周期性地使用墙上时间更新实时时钟;
-
- 调用体系结构无关的函数tick_periodic();
tick_periodic()函数主要执行体系结构无关部分的工作,主要包括:
-
- 给jiffies变量加1;
-
- 更新资源消耗的统计值,比如当前进程所消耗的系统时间和用户时间;
-
- 执行已经到期的动态定时器;
-
- 执行sheduler_tick()函数;
-
- 更新墙上时间xtime;
-
-
计算平均负载值;
-
页(page)
内核把物理页做为内存管理的基本单元:内存管理单元(MMU,管理内存并把虚拟地址转换为物理地址的硬件)以页为单位来管理系统中的页表,从虚拟内存的角度来看,页就是最小单位。体系结构不同,支持的页大小也不尽相同,大多数32位体系结构支持4KB的页,因此在支持4KB页大小并有1GB物理内存的机器上,物理内存会被划分为262144个页。
内核中用struct page结构表示系统中的每个物理页,该数据结构用于描述物理内存本身,而不是描述包含在其中的数据。其中有一个flags域用来表示页的状态,比如页是不是脏的、是不是被锁定在内存中,等等。flags中的每一位单独表示一种状态,因此它至少可以同时表示出32种不同的状态。_count域用于表示页的引用计数,当计数变为-1时,就说明当前内核并没有引用这一页,于是可以用于新的内存分配。virtual域表示页的虚拟地址,即页在虚拟内存中的地址。
区(zone)
由于硬件存在如下引起内存寻址问题的缺陷,所以内核使用区从逻辑上对具有相似特性的页进行分组,主要是以下缺陷:
-
- 一些硬件只能用某些特定的内存地址来执行内存直接访问;
-
- 一些体系结构的内存物理寻址范围比虚拟寻址范围大得多,这样就有一些内存不能永久地映射到内核空间上;
Linux主要使用了4种区:
-
- ZONE_DMA:这个区包含的页能用来执行内存直接访问操作;
-
- ZONE_DMA32:和ZONE_DMA类似,主要区别在于这些页面只能被32位设备访问;
-
- ZONE_NORMAL:这个区包含的都是能正常映射的页;
-
- ZONE_HIGHEM:这个区包含“高端内存”,其中的页并不能永久地映射到内核地址空间。 区的实际使用和分布是与体系结构相关的。
区使用struct zone表示,lock域是一个自旋锁,用来防止该结构被并发访问。watermark数组持有该区的最小值、最高和最低水位值,内核使用水位为每个内存区设置合适的内存消耗基准,该水位值随空闲的内存的多少而变化。name是一个表示区名字的字符串,内核启动期间会初始化这个值。
slab层
空闲链表包含可供使用的、已经分配好的数据结构块,当代码需要一个新的数据结构实例时,就可以从空闲链表中抓取一个,而不需要先分配内存然后再把数据结构放进去。当不再需要这个数据结构的实例时,就把它放回空闲链表,而不是释放它。空闲链表相当于高速缓存。 空闲链表的主要问题之一是不能全局控制,当可用内存变得紧缺时,内核无法通知每个空闲链表让其收缩缓存的大小以便释放一些内存出来,因为内核根本就不知道存在任何空闲链表。Linux内核提供slab层用来解决该缺陷。 slab层把不同的对象划分为高速缓存组,每个组存放不同类型的对象,如一个高速缓存组用于存放进程描述符,另一个用于存放索引节点对象(inode)。每个高速缓存由多个slab组成,一般情况下slab仅仅由一页组成。每个高速缓存都使用kmem_cache结构表示,该结构包含3个链表:slabs_full(满)、slabs_partial(部分满)、slabs_empty(空)。
内核栈
内核栈小而且固定。每个进程的内核栈大小既依赖体系结构,同时也与内核编译时的选项有关,通常为两页的大小。每个进程的整个调用链必须放在自己的内核栈中,不过中断处理程序也会使用它们所中断的进程的内核栈,这样中断处理程序也要放在内核栈中,这会使内核栈附加更严格的约束条件。为此在2.6的早期加入一个设置单页内核栈的选项,激活时,每个进程的内核栈只有一页,而中断处理程序将使用专门的中断栈。
虚拟文件系统
虚拟文件系统(VFS)作为内核子系统为用户空间程序提供了文件和文件系统相关的接口,通过虚拟文件系统,程序可以使用标准的Unix系统调用对不同的文件系统,甚至不同介质上的文件系统进行读写操作(即用户可以直接使用open()、read()、write()等系统调用,而无需考虑具体文件系统和实际物理介质)。之所以可以使用这种通用接口,是因为内核在它的底层文件系统接口上建立了一个抽象层,使Linux能够支持各种文件系统。 Linux在标准内核中已支持的文件系统超过60种(包括本地文件系统和网络文件系统),VFS层提供给这些不同文件系统一个统一的实现框架,而且也提供了能和标准系统调用交互工作的统一接口。
Unix文件系统相关对象
从本质上讲文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。Unix使用了4种和文件系统相关的传统抽象概念:文件、目录、索引节点、安装点(mount point)。 在Unix中目录属于普通文件,它列出包含在其中的所有文件,由于VFS把目录当做文件对待,所以可以对目录执行和文件相同的操作。 Unix系统将文件的相关信息和文件本身这两个概念加以区分,例如访问控制权限、大小、拥有者、创建时间等信息。文件相关信息,有时被称为文件的元数据,被存储在一个单独的数据结构中,该结构被称为索引节点(inode)。文件系统的控制信息存储在超级块中。 Unix文件系统在磁盘中的布局也按照上述概念实现,如在磁盘中,文件(包括目录)信息按照索引节点的形式存储在单独的块中;控制信息被集中存储在磁盘的超级块中。Linux的VFS的设计目标就是要保证能与支持和实现了这些概念的文件系统协同工作,比如支持像FAT、NTFS这样的非Unix风格的文件系统。
VFS对象 VFS使用一组数据结构来代表通用文件对象,这些结构体包含数据的同时也包含操作这些数据的函数指针,其中的操作函数由具体文件系统实现。一共有四个主要的VFS对象:
- 1.超级块对象,代表一个具体的已安装文件系统;
- 2.索引节点对象,代表一个具体文件;
- 3.目录项对象,代表一个目录项,是路径的一个组成部分;(不是目录对象,VFS中将目录作为文件来处理)
- 4.文件对象,代表由进程打开的文件;
超级块对象 各种文件系统都必须实现超级块对象,该对象用于存储特定文件系统的信息,通常对应于存放在磁盘特定扇区中的文件系统超级块或文件系统控制块。对于并非基于磁盘的文件系统,它们会在使用现场创建超级块,并将其保存到内存中。超级块对象用super_block结构体表示。在文件系统安装时,会调用alloc_super()函数以便从磁盘读取文件系统超级块,并且将其信息填充到内存中的超级块对象中。
索引节点对象 索引节点对象包含了内核在操作文件或目录时需要的全部信息(如用户、用户组、文件大小、最后访问时间、访问权限等等),这些信息可以从磁盘索引节点直接导入。由struct inode表示,索引节点仅当文件被访问时,才在内存中创建,一个索引节点代表文件系统中的一个文件,它也可以是设备或者管道这样的特殊文件。
目录项对象 VFS把目录当做文件对待,所以在路径/bin/vi中,bin和vi都属于文件,bin是特殊的目录文件,而vi是一个普通文件,路径中的每个组成部分都由一个索引节点对象表示。为了方便目录查找和路径解析等操作,VFS引入了目录项的概念,由detry结构体表示。每个detry代表路径中的一个特定部分,如/、bin和vi都属于目录项对象,前两个是目录,最后一个是普通文件。目录项对象没有对应的磁盘数据结构,VFS根据字符串形式的路径名现场创建它。为提高效率,目录项对象提供了缓存功能。detry结构体中的d_inode域指向目录项相关联的索引节点。
文件对象 文件对象表示进程已打开的文件,是已打开的文件在内存中的表示。由open()系统调用创建,由close()系统调用撤销。因为多个进程可以同时打开和操作一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已打开的文件,它反过来指向目录项对象(的索引节点),只有目录项对象才表示已打开的实际文件。虽然一个文件对应的文件对象不是唯一的,但对应的索引节点及目录项对象则是唯一的。文件对象由file结构体表示,f_detry域指向对应的目录项。
平坦地址空间
内核除了管理本身的内存外,还必须管理用户空间中进程的内存,这个内存即进程地址空间。 Linux采用虚拟内存技术,系统中的所有进程之间以虚拟方式共享内存,对一个进程而言它好像可以访问整个系统的所有物理内存。 进程可寻址的虚拟内存组成了进程的地址空间,内核允许进程使用这种虚拟内存中的地址。 每个进程都有一个32位或者64位的平坦(flat)地址空间,具体大小取决于体系结构。平坦指地址空间范围是一个独立的连续空间,如0~4294967295(2^32)。因为每个内存都有唯一的平坦地址空间,所以一个进程的地址空间与另一个进程的地址空间即使有相同的内存地址,实际上也彼此互不相干。
内存区域
尽管一个进程可以寻址4GB的虚拟内存,但这并不代表它有权访问所有的虚拟地址。可被访问的合法地址空间称为内存区域(memory areas),通过内核,进程可以给自己的地址空间动态地添加或减少内存区域。进程只能访问有效内存区域内的内存地址,每个内存区域也具有相关权限属性(可读、可写、可执行)。如果一个进程访问了不在有效范围内的内存地址,或者以不正确的方式访问了有效地址,那么内核就会终止该进程,并返回段错误信息。
内存区域可以包含进程的各种内存对象 如:
- 代码段:可执行文件代码的内存映射;
- 数据段:可执行文件的已初始化全局变量的内存映射;
- BSS段:未初始化全局变量的内存映射,页面中的信息全部为0;
- 进程的用户空间栈(不同于进程内核栈);
- 共享库(C库、动态链接库等)的代码段、数据段、bss段;
- 任何内存映射文件;
- 任何共享内存段;
- 任何匿名的内存映射,比如通过malloc()分配的内存;
虚拟内存区域 内存区域由vm_area_struct结构体表示,描述了指定地址空间内连续区间上的一个独立内存范围。内核将每个内存区域作为一个单独的内存对象管理,每个内存区域都有一致的属性,比如访问权限等,相应的操作也都一致。vm_start、vm_end分别用来表示内存区域的首、尾地址,内存区域的位置就在[vm_start,vm_end]之间。vm_mm域指向对应的mm_struct,所以两个独立的进程将同一个文件映射到各自的地址空间,它们分别都会有一个vm_area_struct来标志自己的内存区域,而如果两个线程共享一个地址空间,那么它们也同时共享其中所有的vm_area_struct结构体。
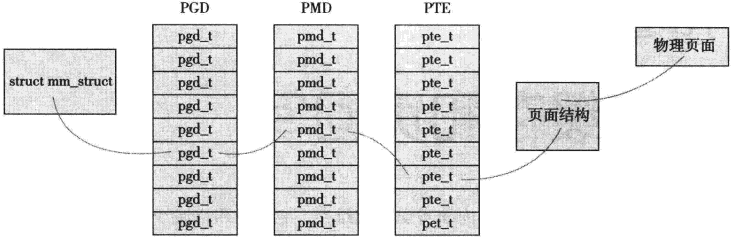
页表
当程序访问一个虚拟地址时,必须将其转化为物理地址,然后处理器才能解析地址并访问请求。地址的转换工作需要通过查询页表才能完成:将虚拟地址分段,使每段虚拟地址都作为一个索引指向页表,而页表项则指向下一级别的页表或指向最终的物理页面。Linux中使用三级页表完成地址转换:
页高速缓存和页回写
页高速缓存是Linux内核实现的磁盘缓存,通过把磁盘中的数据缓存到物理内存中,以此减少对磁盘的I/O操作。页高速缓存由内存中的物理页组成,其内容对应磁盘上的物理块。页高速缓存大小能动态调整。Linux页高速缓存使用address_space结构体管理。 页回写则是将高速缓存中的变更数据刷新回磁盘的操作。程序执行写操作直接写到缓存中,后端存储(磁盘、块设备文件等等)不会立即直接更新,而是将页高速缓存中被写入的页面标记成“脏”,并且被加入到脏页链表中,然后由一个进程(回写进程)周期性地将脏页链表中的页写回到磁盘。 之所以要使用磁盘高速缓存,主要源自两个因素: 访问磁盘的速度要远远低于访问内存的速度:ms和ns的差距; 数据一旦被访问,就很可能在短期内再次被访问到:临时局部原理;
flusher线程
在2.6中由一群内核线程(flusher线程)负责将内存中累积的脏页写回磁盘。当以下情况发生时,脏页会被写回:
-
当空闲内存低于一个特定的阈值时;
-
当脏页在内存中驻留时间超过一个特定的阈值时;
-
当用户进程调用sync()和fsync()系统调用时;
设备类型
在Linux中,设备被分为以下三种类型:
-
块设备:可寻址,寻址以块为单位,块大小取决于设备。通常支持对数据的随机访问,如硬盘、蓝光光碟、闪存等。通过称为“块设备节点”的特殊文件来访问,通常被挂载为文件系统。
-
字符设备:不可寻址,仅提供数据的流式访问,即一个个字符或一个个字节,如键盘、鼠标、打印机等。通过称为“字符设备节点”的特殊文件来访问,与块设备不同,应用程序通过直接访问设备节点与字符设备交互。
-
网络设备:通过一个物理适配器和一种特定的网络协议提供了对网络的访问,打破了Unix所有东西都是文件的设计原则,不是通过设备节点来访问,而是通过套接字API这样的特殊接口来访问。
伪设备
并不是所有设备驱动都表示物理设备,有些设备驱动是虚拟的,仅提供访问内核功能而已,被称为“伪设备”,如内核随机数发生器(/dev/random)、空设备(/dev/null)、零设备(/dev/zero)等等。
模块
Linux内核是模块化组成的,允许在运行时动态地向其中插入或删除代码,这些代码被组合在一个单独的二进制镜像中,即所谓的可装载内核模块,简称模块。支持模块的好处是基本内核镜像可以尽可能地小,因为可选的功能和驱动程序可以利用模块形式再提供。
内核的职责
-
进程调度:Linux属于抢占式多任务操作系统,多任务指多个进程(即运行中的程序)可以同时驻留于内存,且都能获得对CPU的使用权。抢占指一组规则,这组规则控制着哪些进程获得对CPU的使用以及能使用多长时间。
-
内存管理:Linux采用了虚拟内存管理机制,该技术主要有2个优势:(1)不同进程之间、进程与内核之间彼此隔离,因此一个进程无法读取或者修改内核或者其他进程的内存内容;(2)只需将进程的一部分保持在内存中,降低了进程对内存的需求量且还能在RAM中同时加载更多的进程(因而使得在任意时刻CPU都能够有至少一个进程可以执行,从而使得对CPU资源的利用更加充分)。
-
提供了文件系统:创建、获取、更新、删除文件;
-
创建和终止进程;
-
对设备的访问:内核既要为程序访问设备提供简化版的标准接口,同时还要仲裁多个进程对同一个设备的访问;
-
联网:内核以用户进程的名义收发网络数据;
-
提供系统调用应用编程接口(API);
-
为每个用户营造一种抽象:虚拟私有计算机;(多用户)
目录权限
也可对目录进程权限设置,但是其意义与普通文件的权限设置不同:
-
读权限允许列出目录内容;
-
写权限允许对目录的内容进行修改(添加、修改、删除文件名)
-
执行权限允许对目录中的文件进行访问(仍需受文件自身访问权限的约束);
进程的内存布局
-
文本段:程序的指令;
-
数据段:程序使用的静态变量;
-
堆:程序可从该区域动态分配额外内存;
-
栈:随函数调用、返回而增减的一片内存,用于为局部变量和函数调用链接信息分配存储空间; 内核通过对父进程的复制来创建子进程,子进程从父进程处继承数据段、栈、堆的副本后可以修改这些内容而不影响父进程的内容。在内核中文本段被标记为只读,并由父子进程共享。execve()系统调用会销毁现有的文本段、数据段、栈、堆,并根据新程序的代码创建新段来替换它们。
进程的用户和组标识符
- 真实用户ID和组ID:进程所属的用户和组;
- 有效用户ID和组ID:进程在访问受保护资源时会使用这两个ID来确定访问权限,一般情况下有效ID和相应的真实ID值相同。改变进程的有效ID实际上是一种机制,用来使进程具有其他用户和组的权限;
- 补充组ID:用来标识进程所属的额外组;
特权进程指有效用户ID为0(超级用户)的进程,通常由内核所施加的权限限制对此类进程无效。
init进程
系统启动时内核会创建一个名为init的进程,即所有进程之父,该进程的程序文件为/sbin/init。系统中的所有进程不是由init创建就是由其后代创建。init进程的进程号总是1,且总是以超级用户身份运行。只有关闭系统才能终止该进程。
内存映射
mmap()系统调用会在虚拟地址空间中创建一个新的内存映射。由某一进程所映射的内存可以与其它进程的映射共享,共享实现的方式主要有2种:
- (1)两个进程都针对某一文件的相同部分加以映射;
- (2)由fork()创建的子进程从父进程中继承映射。
多个进程共享的内存页面相同时,进程之一对页面的修改其他进程是否可见取决于创建映射时所传入的标志参数。
信号并非实时到达
信号从产生直至送达进程期间一直处于挂起状态,系统会在接收进程下次获得调度时将处于挂起状态的信号同时送达。如果接收进程正在运行,则会立即将信号送达。
执行系统调用所发生的步骤
- 1.应用程序通过调用C语言函数库中的wrapper函数来发起系统调用;
- 2.外壳函数将调用参数复制到寄存器;
- 3.外壳函数将系统调用的编号复制到特殊的CPU寄存器(%eax)中,方便内核区分是哪一个系统调用;
- 4.外壳函数执行一条中断机器指令,引发处理器从用户态切换到核心态,并执行系统中断的中断矢量所指向的代码;
- 5.为响应中断内核会调用system_call()例程来处理本次中断,包括检验系统调用编号的有效性、发现并调用相应系统调用的服务例程并获取执行结果、从内核栈中恢复各寄存器值并将系统调用返回值置于栈中、返回至外壳函数同时将处理器切换回用户态;
- 6.若系统调用服务例程的返回值表明调用有误,外壳函数会使用该值来设置全局变量errno,然后外壳函数会返回到调用程序;
系统调用的执行步骤
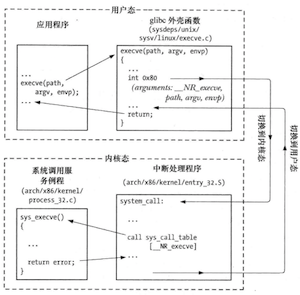
因此从C语言编程的角度来看,调用C语言函数库的外壳函数等同于调用相应的系统调用服务例程。
文件空洞
write()函数可以在文件结尾后的任意位置写入数据。从文件结尾后到新写入数据间的这段空间称为文件空洞。从编程角度看文件空洞中是存在字节的,读取空洞将返回以0填充的缓冲区。然而文件空洞不占用任何磁盘空间,直到后续某个时刻在文件空洞中写入了数据,文件系统才会为其分配磁盘块。文件空洞的主要优势在于:与为实际需要的空字节分配磁盘块相比,稀疏填充的文件会占用较少的磁盘空间。 在大多数文件系统中文件的空间是以块为单位进行分配的,块的大小通常为1024字节、2048字节等。如果空洞的边界落在块内,而非恰好落在块边界上,则会分配一个完整的块来存储数据,块中与空洞相关的部分则以空字节填充。 空洞的存在意味着一个文件名义上的大小可能要比其占用的磁盘存储空间要大。向空洞中写入字节,内核需要为其分配存储单元。
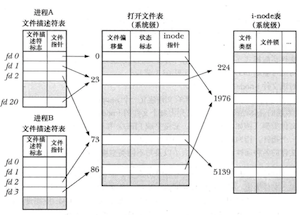
内核对文件描述符和打开文件之间关系的描述
多个文件描述符可能指向同一个打开的文件,且这些文件描述符可在相同或者不同的进程中打开。
对于文件描述符与打开的文件之间的关系,内核维护了3个数据结构:
- 进程级的文件描述符表;(进程当前打开的文件描述符)
- 系统级的打开文件表;(当前文件偏移量、打开文件的状态标志、文件访问模式、该文件i-node对象的引用)
- 文件系统的i-node表;(文件类型、文件持有的锁的列表、文件的大小类型等属性)
两个不同的文件描述符若指向同一个打开的文件句柄,将共享同一文件偏移量,即当通过其中一个文件描述符修改了文件的偏移量,从另一个文件描述符中将会观察到这一变化。
文件描述符、打开的文件句柄和i-node之间的关系
分散输入和集中输出
readv()和writev()系统调用分别实现了分散输入和集中输出的功能,它们并非只对单个缓冲区进行读写操作,而是一次即可传输多个缓冲区的数据。 readv()从文件描述符中读取一片连续的字节,然后将其散置于一组缓冲区中,最后一个缓冲区中可能只有部分数据。 writev()将一组缓冲区中的所有数据拼接起来,然后以连续的字节序列写入文件描述符指定的文件中。
程序包含的信息
程序是包含了一系列信息的文件,这些信息描述了如何在运行时创建一个进程,主要包括以下内容:
-
二进制格式标识:用于描述其他可执行文件格式的元信息;
-
机器语言指令:对程序算法进行编码;
-
程序入口地址:标识程序开始执行时的起始指令位置;
-
数据:变量初始值和字面常量;
-
符号表及重定位表:描述程序中函数和变量的位置及名称;
-
共享库和动态链接信息;
从内核的角度理解进程
进程是由内核定义的抽象实体,并为该实体分配用以执行程序的各项系统资源。从内核角度看,进程由用户内存空间和一系列内核数据结构组成,其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程状态信息。记录在内核数据结构中的信息包括许多与进程相关的标识号、虚拟内存表、打开的文件描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
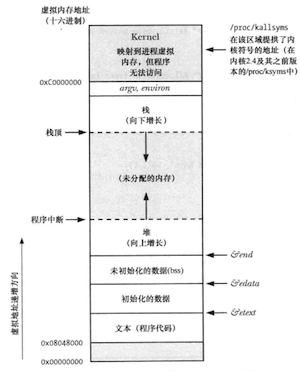
进程内存中的段
每个进程所分配的内存由很多部分组成,通常称之为段(segment):
- 文本段:程序的机器语言指令,具有只读属性,可以被运行同一程序的所有进程共享;
- 初始化数据段:显式初始化的全局变量和静态变量,当程序加载到内存时从可执行文件中读取这些变量的值;
- 未初始化数据段(BSS段):未进行显式初始化的全局变量和静态变量,程序启动之前系统会将本段内的所有内存初始化为0;
- 栈:是一个动态增长和收缩的段,由栈帧组成,系统会为每个当前调用的函数分配一个栈帧,其中存储了函数的局部变量、实参、返回值;
- 堆:在运行时动态进行内存分配的一块区域;(堆的顶端称为program break)
size命令可以显示二进制可执行文件的文本段、初始换数据段、BSS段的大小。
在Linux/x86-32中典型的进程内存结构:
虚拟内存的好处
虚拟内存将每个程序使用的内存切割为小型的、固定大小的页单元,相应地将RAM划分为一系列与虚拟内存页尺寸相同的页帧。任何时刻每个程序仅有部分页需要驻留于物理内存页帧中,这些页构成了所谓的驻留集,程序未使用的页拷贝保存在**交换区**中(磁盘空间中的保留区域),仅在需要时才会载入物理内存。
内核为每个进程维护一张页表,描述了每页在进程虚拟地址空间中的位置,页表中每个条目要么指出一个虚拟页面再RAM中的位置,要么表明其当前驻留在磁盘上。虚拟内存的实现需要硬件中的分页内存管理单元(PMMU)的支持,PMMU把要访问的每个虚拟内存地址转换为相应的物理内存地址,当特定的虚拟内存地址所对应的页没有驻留于RAM中时,将以页面错误通知内核。
虚拟内存概览
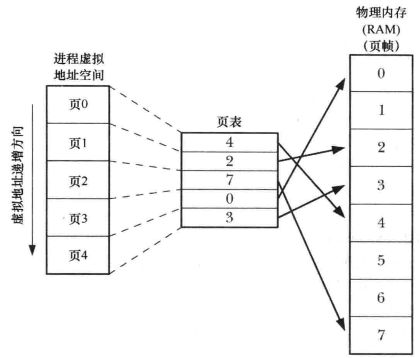
虚拟内存管理使得进程的虚拟地址空间与RAM物理地址空间隔离开来,这带来许多优点:
-
进程与进程、进程与内核相互隔离,一个进程不能读取或修改另一进程或内核的内存;
-
适当情况下不同的进程能够共享内存,比如指向同一程序的不同进程或者使用mmap()显式进行内存共享(内核可以使不同进程的页表条目指向相同的RAM页);
-
便于实现内存保护机制:可以对页表条目进行标记以表示相关页面内容是可读、可写、可执行的;多个进程共享RAM页面时,允许每个进程对内存采取不同的保护措施;
-
程序员和编译器、链接器之类的工具无需关注程序在RAM中的物理布局;
-
因为驻留在内存中的仅是程序的一部分,所以程序的加载和运行都很快,而且一个进程所占用的内存(即虚拟内存大小)能够超出RAM的容量;
-
由于每个进程使用的RAM减少了,RAM中同时可以容纳的进程数量就增多了,这增大了如下事件的概率:任何时刻CPU都至少可以执行一个进程,从而提高CPU的利用率;
用户栈帧的内容
每个用户栈帧主要包含如下信息:
-
函数的实参、局部变量,函数在返回时会自动销毁这些变量;
-
函数调用的链接信息:每个函数调用另一个函数时,会在被调用函数的栈帧中保存寄存器的副本,以便函数返回时能够为函数调用者将寄存器恢复原样;
program break
通常将堆的当前内存边界称为“program break”,改变堆的大小(分配或者释放内存)其实就像命令内核改变进程的program break位置一样简单。传统的UNIX内核提供了两个操纵program break的系统调用:brk()和sbrk()。
一般情况下free()并不降低program Break的位置,而是将这块内存添加到空闲的内存列表中供后续的malloc()函数循环使用。仅当堆顶空闲内存足够大的时候,free()函数的glibc实现才会调用sbrk()来降低program break的地址。
一般情况下应该避免使用realloc()
通常情况下当增大已分配内存时,realloc()会试图去合并在空闲列表中紧随其后且大小满足要求的内存块。若原内存块位于堆的顶部,那么realloc()会对堆进行扩展,如果原内存块位于堆的中部,且紧邻其后的空闲内存空间大小不足,realloc()会分配一块新内存,并将原有数据复制到新内存块中,这将占用大量的CPU资源,一般情况下应该避免使用realloc()。
set-user-ID
实际用户ID和实际组ID确定了进程所属的用户和组。 当进程尝试执行各种操作(即系统调用)时,将结合有效用户ID、有效组ID,连同辅助组ID一起来确定授予进程的权限。 有效用户ID为0的进程拥有超级用户的所有权限,这样的进程也称为特权级进程。某些系统调用只能由特权级进程执行。 通常有效ID与实际ID相等,可以通过系统调用或者执行set-user-ID、set-group-ID程序来修改。
**set-user-ID程序会将进程的有效用户ID设置为可执行文件的属主用户ID**,从而获得常规情况下并不具有的权限。区别于一般文件,可执行文件还拥有两个特别的权限位set-user-ID位和set-group-ID位,当设置了这两个位时,相应的文件权限位显示为s:
$ su
Password:
# ls -l prog
-rwxr-xr-x 1 root root ...
# chmod u+s prog
# chmod g+s prog
# ls -l prog
-rwsr-sr-x 1 root root ...
查看进程执行时间
进程时间是进程创建后使用的CPU时间数量,内核把CPU时间分为两部分:
- 用户CPU时间是在用户模式下执行所花费的时间数量,对于进程来说是它已经得到的CPU时间;
- 系统CPU时间是在内核模式中执行所花费的时间数量,是内核用于执行系统调用或代表程序执行其他任务的时间;
在执行shell程序时加上time命令,将获得这两个部分的时间:
$ time ./myprog real 0m4.84s user 0m1.030s sys 0m3.43s
直接I/O
Linux允许应用程序在执行磁盘I/O时绕过缓冲区高速缓存,从用户空间直接将数据传递到文件或者磁盘设备,称为直接I/O或者裸I/O。对于大多数应用而言,使用直接I/O可能会大大降低性能。直接I/O只适用于有特定I/O需求的应用,例如数据库系统,其高速缓存和I/O优化机制均自成一体,无需内核消耗CPU时间和内存去完成相同任务。
文件的i节点所维护的信息
-
文件类型(常规文件、目录、符号链接、字符设备等);
-
文件属主;
-
文件属组;
-
3类用户的访问权限;
-
3个时间戳(最后访问时间、最后修改时间、文件状态的最后改变时间);
-
指向文件的硬链接数量;
-
文件的大小,以字节为单位;
-
实际分配给文件的块数量,这一数字可能不会简单等同于文件的字节大小(考虑文件中包含空洞的情形);
-
指向文件数据块的指针;
ext2文件系统中文件的文件块结构
类似于大多数UNIX文件系统,ext2文件系统在存储文件时数据块不一定连续,甚至不一定按顺序存放。为了定位文件数据块,内核在i节点内维护一组指针。
ext2文件系统中文件的文件块结构
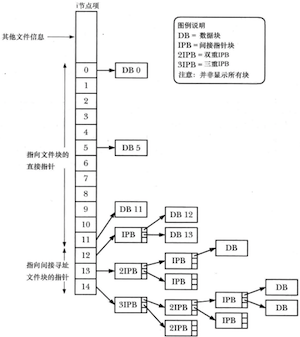 每个i节点包含15个指针,其中前12个指针指向文件前12个块在文件系统中的位置。接下来是一个指向指针块的指针,提供了文件的第13个以及后续数据块的位置。指针块中指针的数量取决于文件系统中块的大小,每个指针需占用4字节因此指针的数量可能在256(块容量1024字节)~1024(块容量4096字节)之间,这样就考虑到了大型文件的情况。即便是对于巨型文件,第14个指针是一个双重间接指针,指向**指针块**,其块中指针进而指向指针块,此块中指针最终才指向文件的**数据块**。只要有体量巨大的文件,就会随之产生更深一层的递进。
每个i节点包含15个指针,其中前12个指针指向文件前12个块在文件系统中的位置。接下来是一个指向指针块的指针,提供了文件的第13个以及后续数据块的位置。指针块中指针的数量取决于文件系统中块的大小,每个指针需占用4字节因此指针的数量可能在256(块容量1024字节)~1024(块容量4096字节)之间,这样就考虑到了大型文件的情况。即便是对于巨型文件,第14个指针是一个双重间接指针,指向**指针块**,其块中指针进而指向指针块,此块中指针最终才指向文件的**数据块**。只要有体量巨大的文件,就会随之产生更深一层的递进。
这一设计的好处在于:
-
在维持i节点结构大小固定的同时支持任意大小的文件;
-
文件系统可以以不连续方式来存储文件块,又可以通过lseek()随机访问文件,而内核只需计算所要遵循的指针;
-
对于在大多数系统中占绝对多数的小文件而言,这种设计满足了对文件数据块的快速访问(通过i节点的直接指针访问);
-
文件可以有空洞,只需将i节点和间接指针块中的相应指针打上标记(值0),表明这些指针并未指向实际的磁盘块即可,而无需为文件空洞分配空字节数据块;
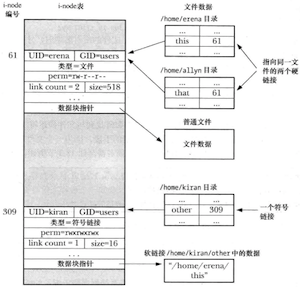
目录与普通文件的区别
- 在其i-node条目中会将目录标记为一种不同的文件类型;
- 目录是经特殊组织而成的文件,本质上是一个表格,包含文件名和i-node编号;
以文件/etc/passwd为例展示i-node和目录结构之间的关系
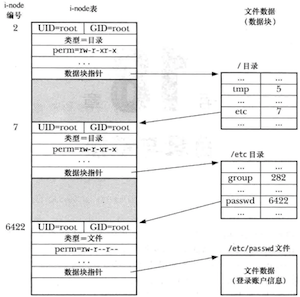 i-node中并没有存储文件名,而是通过目录列表内的一个映射来定义文件名称,好处在于可以在相同或者不同目录中创建多个名称,每个均指向相同的i-node节点,也将这些名称称为硬链接。
仅当i-node的链接计数降为0时才会删除文件的i-node记录和数据块。
无法通过文件描述符来查找关联的文件名,因为一个文件描述符指向一个i-node,而指向这个i-node的文件名则可能有多个。
i-node中并没有存储文件名,而是通过目录列表内的一个映射来定义文件名称,好处在于可以在相同或者不同目录中创建多个名称,每个均指向相同的i-node节点,也将这些名称称为硬链接。
仅当i-node的链接计数降为0时才会删除文件的i-node记录和数据块。
无法通过文件描述符来查找关联的文件名,因为一个文件描述符指向一个i-node,而指向这个i-node的文件名则可能有多个。
硬链接的限制
对硬链接的限制有二,均可以用符号链接来加以规避:
- 因为目录条目(硬链接)对文件的指代采用了i-node编号,而i-node编号的唯一性仅在一个文件系统之内才能得到保障,所以硬链接必须与其指代的文件驻留在同一文件系统中;
- 不能为目录创建硬链接,从而避免出现另诸多系统程序陷入混乱的链接环路;
符号链接,也称软链接,是一种特殊的文件类型,其数据是另一文件的名称。文件的链接计数中并未将符号链接计算在内,因此如果移除了符号链接所指向的文件名,符号链接本身还将继续存在,尽管无法再对其进行解引用操作,此类链接也称为悬空链接(甚至可以为并不存在的文件名创建一个符号链接)。
对硬链接和符号链接的展现
 因为符号链接指代一个文件名,而非i-node编号,所以可以用其来链接不同文件系统中的文件。
因为符号链接指代一个文件名,而非i-node编号,所以可以用其来链接不同文件系统中的文件。
大部分操作会无视符号链接的所有权和权限,仅当在带有粘性权限位的目录中对符号链接进行移除或改名操作时才会考虑符号链接自身的所有权。
当移除指向文件的最后一个链接时,如果仍有进程持有指代该文件的打开文件描述符,那么在关闭所有此类描述符之前,系统实际上将不会删除该文件。
chroot监禁区
每个进程都有一个根目录,该目录是解释绝对路径时的起点,默认情况下这是文件系统的真实根目录。特权进程可以通过chroot()系统调用来改变一个进程的根目录,这会将应用程序限定于文件系统的特定区域,因此也称为设立了一个chroot监禁区。ftp程序就是应用chroot()的典型实例:当匿名用户登录ftp时,ftp程序将使用chroot()为新进程设置根目录,即设置为一个专门预留给匿名用户的目录,用户将受困于文件系统中新根目录下的子树中。
并非任何程序都能在chroot监禁区中运行,因为大多数程序与共享库之间采取的是动态链接方式。因此,要么只能局限于运行静态链接程序,要么就在监禁区中复制一套标准的共享库系统目录。
通常最好不要在chroot监禁区文件系统内放置set-user-ID-root程序,此外必须关闭所有指向监禁区外目录的文件描述符(遭到监禁的进程仍然能够利用UNIX套接字来接受另一进程指向监禁区之外目录的文件描述符)。
inotify机制
自内核2.6.13起,Linux提供inotify机制,以允许应用程序监控文件事件(打开、关闭、创建、删除、修改、重命名等)。关键步骤如下:
- 应用程序使用inotify_init()来创建一个inotify实例,该系统调用返回的文件描述符用于在后续操作中指代该实例;
- 应用程序使用inotify_add_watch()向inotify实例的监控列表添加条目,从而告知内核哪些文件是自己的兴趣所在(通过位掩码的组合来指定关注的事件,比如被访问、被修改等等);
- 为获得事件通知,应用程序需针对inotify文件描述符执行read()操作,每次对read()的成功调用都会返回一个或多个inotify_event结构,其中记录了处于inotify实例监控之下的某一路径名所发生的事件,如果读取时尚未发生任何事件,read()将会阻塞下去,直至有事件产生;
- 应用程序在结束监控时会关闭inotify文件描述符,这将会自动清除与inotify实例相关的所有监控项; inotify机制可用于监控文件或目录,当监控目录时与路径自身及其所包含文件相关的事件都会通知给应用程序。inotify监控机制为非递归,若应用程序有意监控整个目录子树内的事件,则需对该树种的每个目录发起inotify_add_watch()调用。
可以使用select()、poll()、epoll()以及由信号驱动的I/O来监控inotify文件描述符,只要有事件可供读取,上述API就会将inotify文件描述符标记为可读。
信号处理器程序
信号处理器程序是由程序员编写的函数,用于为响应传递来的信号而执行适当任务。调用信号处理器程序可能会随时打断主程序流程,内核代表进程来调用处理器程序,当处理器返回时,主程序会在处理器打断的位置恢复执行。
为SIGINT信号安装一个处理器程序
#include <signal.h>
#include "tlpi_hdr.h"
static void
sigHandler(int sig)
{
printf("Ouch!\n");
}
int
main(int argc, char *argv[])
{
int j;
if (signal(SIGINT, sigHandler) == SIG_ERR)
errExit("signal");
/* Loop continuously waiting for signals to be delivered */
for (j = 0; ; j++) {
printf("%d\n", j);
sleep(3); /* Loop slowly... */
}
}
有关进程创建的4个重要的系统调用
4个重要的系统调用:
- fork():允许一个进程创建一个新进程,新的子进程几近于对父进程的翻版,子进程将获得父进程的栈、数据段、堆和执行文本段的拷贝;
- exit(status):终止一个进程,将进程占用的资源交还给内核,其参数status为一个整型变量表示进程的退出状态,父进程可以用系统调用wait()来获取该状态;
- wait(&status):如果子进程尚未调用exit()终止,那么wait()会挂起父进程直至子进程终止,子进程的终止状态会通过status参数返回;
- execve(pathname,argv,envp):加载一个新程序到当前进程的内存,这将丢弃现存的程序文本段,并为新程序重新创建栈、数据段以及堆;
概述函数fork()、exit()、wait()、execve()的协同使用
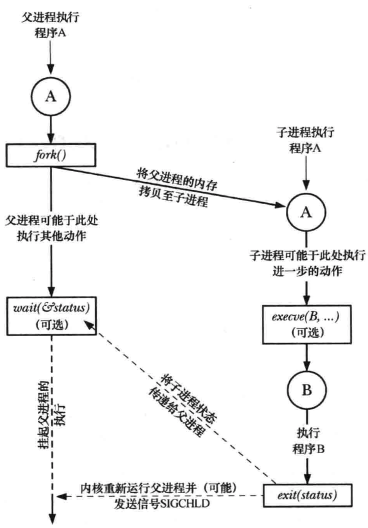
理解fork()的诀窍是要意识到完成对其调用后将存在两个进程,且两个进程都会从fork()的返回处继续执行。这两个进程将执行相同的程序文本段,但却拥有各自的栈段、数据段以及堆段拷贝。程序代码可以通过fork()的返回值来区分父、子进程。调用fork()后系统率先执行哪个进程是无法确定的。
执行fork()时,子进程会获得父进程所有的文件描述符的副本。对于shell来说,shell创建子进程后会调用wait()来暂停运行,并等待子进程退出,只有当执行命令的子进程退出后,shell才会打印自己的提示符。
虽然从概念上可以将fork()理解为对父进程程序段、数据段、堆、栈的拷贝,但实际可能并非这样。因为fork()之后常常伴随着exec(),这将会使用新程序替换进程的代码段并重新初始化其数据段、堆段、栈等。大部分现代UNIX实现采用两种技术来避免这种浪费:
-
内核将每一进程的代码段标记为只读,从而使进程无法修改自身代码,这样父子进程可共享同一代码段;
-
对于父进程数据段、堆段和栈段中的各页,内核采用写时复制技术来处理:最初内核做一些设置令这些段的页表项指向与父进程相同的物理内存页,并将这些页面标记为只读。调用fork()之后,内核会捕获所有父进程或者子进程针对这些页面的修改企图,并为将要修改的页面创建拷贝。系统将新的页面拷贝分配给遭内核捕获的进程,还会对子进程的相应页表做适当调整。
父进程应该使用wait()来防止僵尸进程的积累
如果父进程创建了某一子进程,但并未执行wait(),那么在内核的进程表中将为该子进程永久保留一条记录,如果存在大量此类僵尸进程,它们势必填满内核进程表,从而阻碍新进程的创建。因为僵尸进程无法通过信号杀死,从系统中移除它们的唯一方法就是杀掉它们的父进程,由init进程接管和等待这些僵尸进程,从而清除它们。
无论一个子进程何时终止,系统都会向其父进程发送SIGCHLD信号,对该信号的默认处理是将其忽略,不过也可以安装信号处理程序来捕获并调用wait()来处理僵尸进程。
调用execve()之后进程ID保持不变
调用execve()之后,因为同一进程仍然存在,所以进程ID保持不变。由于是将调用程序取而代之,对execve()的成功调用将永不返回,而且也无需检查execve()的返回值,因为该值肯定为-1.实际上一旦函数返回,就表明发生了错误。
UNIX内核对脚本的要求
UNIX内核运行解释器脚本的方式与二进制程序无异,前提是脚本必须满足下面两点要求:
-
必须赋予脚本文件可执行权限;
-
文件的起始行必须指定运行脚本解释器的路径名,例如:
#! /bin/shexec()如果检测到传入的文件以#!这两个字节开始,就会析取该行的剩余部分(路径名、参数),并执行解释器程序。
线程相对进程的优点与缺点
线程主要是为了解决进程存在的两个问题:
- 进程间的信息难以共享:除去只读代码段外父子进程并未共享内存,因此必须采用一些进程间通信方式在进程间交换信息;
- 调用fork()来创建进程的代价相对较高,即便采用写时复制技术仍然需要复制诸如内存页表和文件描述符表之类的多种进程属性; 创建线程比创建进程通常要快10倍甚至更多,线程的创建之所以较快是因为调用fork()创建子进程时所需复制的诸多属性在线程间本来就是共享的。
线程相对于进程的优点:
- 线程间的数据共享很简单;
- 创建线程要快于创建进程,线程的上下文切换其消耗时间一般比进程要短;
线程相对于进程的缺点:
-
多线程编程时需要确保调用线程安全的函数,或者以线程安全的方式来调用函数;
-
某个线程中的bug可能会危及该进程的所有线程,因为它们共享着相同的地址空间和属性;
-
每个线程都在争用宿主进程中有限的虚拟地址空间;(每个进程都可以使用全部的有效虚拟内存)
pthread_join()
函数pthread_join()等待由thread标识的线程终止,如果线程已经终止,pthread_join()会立即返回。若线程未分离,则必须使用pthread_join()来进行连接,如果未能连接那么线程终止时将产生僵尸线程(与僵尸进程的概念类似)。pthread_join()执行的功能类似于针对进程的waitpid()调用,不过二者之间存在一些显著差别:
- 线程之间的关系是对等的,进程中的任意线程均可以调用pthread_join()与该进程的其他任何线程连接起来。而如果父进程使用fork()创建了子进程,那么它将是唯一能够对子进程调用wait()的进程;
- 无法连接任意线程,也不能以非阻塞方式进行连接;
默认情况下线程是可连接的,即当线程退出时其他线程可以通过调用pthread_join()获取其返回状态。有时候可能不关心线程的返回状态,只是希望系统在线程终止时能够自动清理并移除之,在这种情况下可以调用pthread_detach()并向thread参数传入指定线程的标识符,将该线程标记为处于分离状态。一旦线程处于分离状态,就不能再使用pthread_join()来获取其状态,也无法使其重返可连接状态。
各线程所独有的属性
-
线程ID;
-
信号掩码;
-
线程持有数据;
-
备选信号栈;
-
errno变量;
-
浮点型环境;
-
实时调度策略和优先级;
-
CPU亲和力;
-
能力;
-
栈;
互斥量、临界区、条件变量概念
互斥量可以帮助线程同步对共享资源的使用,以防止如下情况的发生:线程甲试图访问一共享变量时,线程乙正在对其进行修改。 条件变量是对互斥量的补充,允许线程相互通知共享变量的状态发生了变化。
临界区是指访问某一共享资源的代码片段,并且这段代码的执行应为原子操作,即同时访问同一共享资源的其他线程不应中断该片段的执行。
当超过一个线程加锁同一组互斥量时,就可能发生死锁,要避免此类死锁问题最简单的方法是定义互斥量的层级关系,当多个线程对一组互斥量操作时总是应该以相同的顺序对改组互斥量进行锁定。
条件变量允许一个线程就某个共享变量或其他资源的状态变化通知其他线程,并让其他线程等待(阻塞于)这一通知。即允许一个线程休眠,直至接获另一线程的通知去执行某些操作。条件变量总是和互斥量结合使用,条件变量就共享变量的状态改变发出通知,而互斥量则提供对该共享变量访问的互斥。
条件变量的主要操作是发送信号和等待。发送信号操作即通知一个或多个处于等待状态的线程某个共享变量的状态已经改变。等待操作是指在收到一个通知前一直处于阻塞状态。
线程安全的函数
若函数可同时供多个线程安全调用,则称之为线程安全函数。导致线程不安全的典型原因是:使用了在所有线程之间共享全局或静态变量。实现函数线程安全最为有效的方式是使其可重入(应以这种方式来实现所有新的函数库)。
进程组、会话和作业控制概念
进程组是一组相关进程的集合,会话是一组相关进程组的集合。 进程组由一个或多个共享同一进程组标识符的进程组成。每个进程组拥有一个首进程,即创建该组的进程,其进程ID为该进程组的ID,新进程会继承其父进程所属的进程组ID。一个进程可能会因为终止而退出进程组,也可能会因为加入了另外一个进程组而退出进程组(进程组首进程无需是最后一个离开进程组的成员)。
会话首进程是创建该新会话的进程,其进程ID会成为会话ID,新进程会继承其父进程的会话ID。一个会话中的所有进程共享单个控制终端,控制终端会在会话首进程首次打开一个终端设备时被建立。一个终端最多可能会成为一个会话的控制终端。在任一时刻会话中的其中一个进程组会成为终端的前台进程组,其他进程组会成为后台进程组。只有前台进程组中的进程才能从控制终端中读取输入。当用户在控制终端中输入一个信号生成终端字符后,该信号会被发送到前台进程组中的所有成员。
会话和进程组的主要用途是用于shell作业控制。如对于交互式登录来讲,控制终端是用户登录的途径。登录shell是会话首进程和终端的控制进程,也是其自身进程组的唯一成员。从shell中发出的每个命令或通过管道连接的一组命令都会导致一个或多个进程的创建,并且shell会把所有这些进程都放在一个新进程组中。当命令或以管道连接的一组命令以&符号结束时,会在后台进程组中运行这些命令,否则就会在前台进程组中运行这些命令。在登录会话中创建的所有进程都会成为该会话的一部分。
进程组具备两个有用的属性:
-
在特定的进程组中父进程能够等待任意子进程;
-
信号能够被发送给进程组中的所有成员;
SIGHUP
当一个控制进程失去其终端连接之后,内核会向其发送一个SIGHUP信号来通知它这一事实,这种情况可能会在两种场景中出现:
- 当终端驱动器检测到连接断开后,表明调制解调器或终端上信号的丢失;
- 当工作站上的终端窗口被关闭时;
SIGHUP信号的默认处理方式是终止进程。
nohup命令可以用来使一个命令对SIGHUP信号免疫,即将SIGHUP信号的处理设置为SIG_IGN。bash内置的disdown命令提供类似的功能。
作业控制允许一个shell用户同时执行多个命令,其中一个命令在前台运行,其他命令在后台运行。作业可以被停止和恢复以及在前后台之间移动。
当输入的命令以&符号结束时,该命令会作为后台任务运行。可以使用jobs命令列出所有后台作业。使用fg命令来将后台作业移动到前台。
nice值
Linux与大多数其他UNIX实现一样,调度进程使用CPU的默认模型是循环时间共享。每个进程轮流使用CPU直至时间片被用光或自己自动放弃CPU(如sleep或者被I/O阻塞)。
进程特性nice值(-20~19)允许进程间接地影响内核的调度算法。非特权进程只能降低自己的优先级,即赋予一个大于默认值0的nice值,这样做之后就对其他进程“友好(nice)”了。给一个进程赋予一个低优先级(即高nice值)并不会导致它完全无法用到CPU,但会导致它使用CPU的时间变少。
daemon
daemon是一种具备下列特征的进程:
- 生命周期很长,通常伴随系统的整个运行过程;
- 在后台运行且不拥有控制终端。由于没有控制终端,因此内核永远不会为daemon自动生成任何任务控制信号以及终端相关的信号,比如SIGHUP等;
常见的daemon进程:cron、sshd、httpd、inetd;(很多daemon程序都以d结尾)
要变成daemon,一个程序需要完成下面的步骤:
- 执行fork(),之后父进程退出,子进程继续执行(使子进程成为init的子进程);之所以需要这样做是因为假设程序是从命令行启动的,父进程终止时会被shell发现,shell在发现之后会显示出另一个shell提示符,并让子进程继续在后台运行;
- 子进程调用setsid()开启一个新会话,并释放它与控制终端之间的所有关联关系;
- 清除进程的umask,以确保当daemon创建文件和目录时拥有所需的权限;
- 修改进程的当前工作目录,一般会改为根目录;
- 关闭daemon从其父进程继承而来的所有打开着的文件描述符;
- 在关闭了文件描述符0、1、2之后,daemon通常会打开/dev/null并使用dup2()使所有这些描述符指向这个设备; /dev/null是一个虚拟设备,会直接丢弃写入的数据。
becomeDaemon()函数用来完成上述步骤以将调用者变成一个daemon。该函数接收一个掩码参数用来有选择地执行其中的步骤。
Linux能力
Linux能力模型将传统的all-or-nothing UNIX权限模型划分为一个个被称为能力的单元,一个进程能够独立地启用或禁用单个的能力。通过只启用进程所需的能力使得程序能够在不拥有完整的root权限的情况下运行。
传统的UNIX权限模型将进程分为两类:能通过所有权限检测的有效用户ID为0的进程和其他所有需要根据用户和组ID进行权限检测的进程。这个模型的粗粒度划分是一个问题,Linux能力模型优化了这个问题。 在大多数时候Linux能力模型对程序员来讲都是不可见的,原因是当一个对能力一无所知的应用程序的有效用户ID为0时,内核会赋予该进程所有能力。
每个进程都拥有3个相关的能力集:
- 许可的:一个进程可能使用的能力;
- 有效的:内核会使用这些能力来对进程执行权限检查;
- 可继承的:当这个进程执行一个程序时可以将这些权限带入许可集中;
实际上能力是一个线程级的特性,进程中的每个线程的能力都可以单独进行调整,在/proc/PID/task/TID/status文件中可以查看一个多线程进程中某个具体线程的能力,/proc/PID/status文件显示了主线程的能力。
登录记账相关文件
登录记账关注的是哪些用户当前登录进了系统,以及记录过去的登录和登出行为:
-
utmp文件维护着当前登录进系统的用户记录;
-
wtmp文件包含着所有用户登录和登出行为的记录信息以供审计之用;
-
lastlog文件记录着每个用户最近一次登录系统的时间,who、last等命令都使用了这些文件中的信息;
共享库的安装目录
一般共享库及其关联的符号链接会被安装在标准目录中以方便编译器搜索,标准目录包括:
- /usr/lib 大多数标准库安装的目录;
- /lib 应该将系统启动时用到的库安装在这个目录中(因为在系统启动时还没有挂载/usr/lib);
- /usr/local/lib 应该将非标准或实验性的库安装在这个目录;
- 在/etc/ld.so.conf中列出的目录; 搜索的记录会创建缓存,如/etc/ld.so.cache。每当安装了一个新的库,或者更新、删除了已有的库,或者修改了/etc/ld.so.conf文件中的目录列表,都应该运行ldconfig以生成缓存。
在默认情况下当链接器能够选择名称一样的共享库和静态库时,会优先使用共享库。
SOCKET Domain
socket存在于一个通信domain中,它确定了识别出一个socket的方法,以及socket通信的范围。
现代操作系统至少支持下列domain:
-
UNIX(AF_UNIX):在同一台主机上的应用程序之间进行通信;
-
IPv4(AF_INET)
-
IPv6(AF_INET6)
每种socket的实现都至少提供了两种socket:流、数据报。流socket提供了一个可靠的双向的字节流通信信道。而数据报socket在使用时无需与另一个socket连接。在Internet Domain中,数据报socket使用了UDP协议,流socket使用了TCP协议。
SOCKET相关的系统调用
- socket() 创建一个新socket()
- bind() 将一个socket()绑定到一个地址上
- listen() 允许一个流socket接受来自其他socket的接入连接
- accept() 在一个监听流socket上接受来自一个对等应用程序的连接
- connect() 建立与另一个socket之间的连接
**理解accept()的关键点是它会创建一个新socket(),并且正是这个新socket()会与执行connect()的对等socket进行连接。**
socket I/O可以使用传统的read()和write()系统调用或使用一组socket()特有的系统调用如send()、recv()、sendto()以及recvfrom()来完成。默认情况下,这些系统调用在I/O操作无法被立即完成时会阻塞。
UNIX SOCKET
在UNIX domain中,socket地址以路径名来表示,但在这些socket上发生的I/O无须对底层设备进行操作。
对于UNIX domain socket来讲,数据报的传输是在内核中发生的,并且**也是可靠的**。所有消息都会按序被递送并且也不会发生重复的情况。
socket文件的所有权和权限决定了哪些进程能够与这个socket进行通信。 UNIX domain的数据报socket是可靠的,但UDP socket则是不可靠的:数据报可能会丢失、重复或到达的顺序与被发送的顺序不一致。 在一个UNIX domain数据报socket上发送数据会在接收socket的数据队列满时阻塞,与之不同的是,使用UDP时如果进入的数据报会使接受者的队列溢出,那么数据报就会没静默丢弃。
系统上运行的服务和端口号信息会记录在/etc/services文件中。
之所以要选择使用UNIX domain socket是存在几个原因的:
-
在一些实现上,UNIX domain socket的速度比Internert domain socket的速度快;
-
可以使用目录权限来控制对UNIX domain socket的访问;
-
使用UNIX domain socket可以传递打开的文件描述符和发送者的验证信息;
伪终端
伪终端是一对互联的虚拟设备:主伪终端和从伪终端。伪终端对提供了一条双向IPC通道,从伪终端表现得就像一个标准终端一样,所有可以施加于终端设备的操作同样可以施加于伪终端从设备上。
两个程序通过伪终端通信
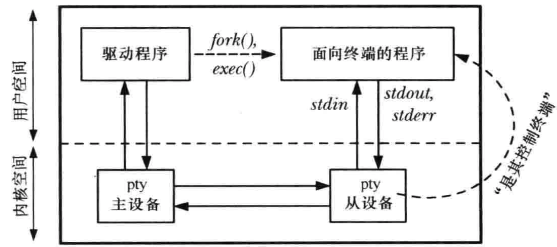
ssh使用伪终端的原理
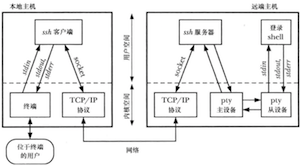
一对伪终端同一个双向管道相似,任何写入到伪终端主设备的数据都会在从设备端作为输入出现,而任何写入到从设备的数据也会在主设备端作为输入出现。
描述Linux中一次进程切换过程中操作系统的行为。
这是一道考察应聘者对操作系统理解程度的半开放性问题,可根据应聘者的回答引导性的展开提问相关概念,如什么状态下会发生进程切换;进程、线程的区别,及其在创建时内部实现方式的区别。
-
主要是保存原执行进程的状态信息,初始化将被执行进程的状态信息。
首先应区分内核态和用户态,进程切换只发生在内核态。
-
硬件上下文切换
在Linux中进程硬件上下文一部分存放在TSS段,剩余部分存放在内核态的堆栈中。在执行进程切换之前,用户态进程使用的所有寄存器内容都保存在内核态堆栈上。 在切换前,schedule()函数还会禁用内核抢占,并初始化一些局部变量。
-
任务状态段(TSS)
Linux为每个CPU创建一个TSS,每次进程切换时,内核都会更新TSS的某些字段(存放在tss_struct结构体中)。 每个进程描述符有一个thread_struct类型的thread字段,被切换出去的进程的硬件上下文就保存在其自身的thread_struct结构体中。
-
分配CPU时钟,schedule()调度其运行
join命令
网络通信中,write返回成功后,是否确保数据发送成功或是被对端服务收到
不是,只是表明待发送数据已被写入系统缓存;
线程与进程继承关系的区别
USER VIEW
<-- PID 43 --> <----------------- PID 42 ----------------->
+---------+
| process |
_| pid=42 |_
_/ | tgid=42 | \_ (new thread) _
_ (fork) _/ +---------+ \
/ +---------+
+---------+ | process |
| process | | pid=44 |
| pid=43 | | tgid=42 |
| tgid=43 | +---------+
+---------+
<-- PID 43 --> <--------- PID 42 --------> <--- PID 44 --->
KERNEL VIEW
nobody
许多系统中都按惯例地默认创建一个nobody,尽量限制它的权限至最小,当服务器向外服务时,可能会让client以nobody的身份登录。nobody是一个普通用户,非特权用户。 使用nobody用户名的目的是,使任何人都可以登录系统,但是其UID和GID不提供任何特权,即该uid和gid只能访问人人皆可读写的文件。 nobody就是一个普通账户,因为默认登录shell是/sbin/nologin,所以这个用户是无法直接登录系统的,也就是黑客很难通过漏洞连接到你的服务器来做破坏。此外这个用户的权限也给配置的很低。因此有比较高的安全性。一切都只给最低权限。这就是nobody存在的意义。
它们是用来完成特定任务的,比如nobody和ftp等,我们访问LinuxSir.Org的网页程序时,官网的服务器就是让客户以’nobody’身份登录的(相当于Windows系统中的匿名帐户);我们匿名访问ftp时,会用到用户ftp或nobody。
将一个进程启动为守护进程
有如下Web程序server.js:
var http = require('http');
http.createServer(function(req, res) {
console.log('server starts...'); // 用到标准输出
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World');
}).listen(5000);
各种启动方式:
启动为普通的前台任务,会独占命令行窗口,只有运行完了或者手动中止,才能执行其他命令
$ node server.js
启动为后台任务,后台任务继承当前session的标准输出和标准错误。因此,后台任务的所有输出依然会同步地在命令行下显示。后台任务不再继承当前session的标准输入,无法向这个任务输入指令。如果它试图读取标准输入,就会暂停执行(halt)。
$ node server.js &
使用disown命令 在用户退出session时,系统向session发出SIGHUP信号,同时session会向所有子进程发送SIGHUP信号,子进程在收到SIGHUP信号后会退出 前台任务在session退出时必然会收到SIGHUP信号 后台任务是否会收到SIGHUP信号,取决于Shell的huponexit参数的配置,可以使用shopt | grep huponexit查看该配置 disown会将任务从后台任务列表(可以通过jobs命令查看)中移除,一个”后台任务”只要不在这个列表之中,session就肯定不会向它发出SIGHUP信号
$ node server.js &
$ disown
使用disdown后还有一个问题:退出 session 以后,如果后台进程与标准I/O有交互,它还是会挂掉,因为"后台任务"的标准 I/O 继承自当前 session,disown命令并没有改变这一点。一旦”后台任务”读写标准 I/O,就会发现它已经不存在了,所以就报错终止执行。为了解决这个问题,需要对”后台任务”的标准 I/O 进行重定向。
$ node server.js > stdout.txt 2> stderr.txt < /dev/null &
$ disown
比disown更方便的命令,就是nohup
$ nohup node server.js &
它完成以下事情: 1.阻止SIGHUP信号发到这个进程 2.关闭标准输入。该进程不再能够接收任何输入,即使运行在前台 3.重定向标准输出和标准错误到文件nohup.out nohup命令实际上将子进程与它所在的 session 分离了。
Linux文件权限0600是什么意思?
0600表示分配给文件的权限。 一共四位数,第一位数表示gid/uid一般不用,剩下三位分别表示owner,group,other的权限每个数可以转换为三位二进制数,分别表示rwx(读,写,执行)权限,为1表示有权限,0无权限。如6是上面第二个数,可以表示为二进制数110,表示owner有读,写权限,无执行权限。
