前言
虽然JavaScript的产生与Netscape Navigator浏览器的需求有关系,但它并非只是设计出来用于浏览器前端的。早在1994年,网景公司就公布了其Netscape Enterprise Server中的一种服务器端脚本实现,它的名字叫LiveWire,是最早的服务器端JavaScript,甚至早于浏览器中的JavaScript公布。对于这门图灵完备的语言,网景早就开始尝试将它用在后端。
Node凭借V8的高性能和异步I/O模型将JavaScript重新推向了一个高潮。现在,Node不仅满足JavaScript同时运行在前后端,而且性能还十分高效。前后端要跨语言开发的现状已经开始改变。Node的本意是提供一个高性能的面向网络的执行平台,但无意间促成了JavaScript社区的繁荣,并进而形成强大的生态系统。
第1章 Node简介
除了HTML、WebKit和显卡这些UI相关技术没有支持外,Node的结构与Chrome十分相似。它们都是基于事件驱动的异步架构,浏览器通过事件驱动来服务界面上的交互,Node通过事件驱动来服务I/O。Node不处理UI,但用与浏览器相同的机制和原理运行。
Chrome浏览器和Node的组件构成:
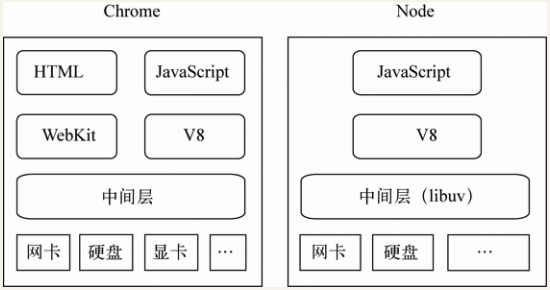
在Node中,绝大多数的操作都以异步的方式进行调用。这样的意义在于,在Node中,我们可以从语言层面很自然地进行并行I/O操作。
Node的特点:
- 异步I/O:在Node中,绝大多数的操作都以异步的方式进行调用。
- 事件与回调函数:将前端浏览器中应用广泛且成熟的事件引入后端,配合异步I/O,将事件点暴露给业务逻辑。代码的编写顺序与执行顺序并无关系。
- 单线程:Node保持了JavaScript在浏览器中单线程的特点。而且在Node中,JavaScript与其余线程是无法共享任何状态的。
- 跨平台:兼容Windows和*nix平台主要得益于Node在架构层面的改动,它在操作系统与Node上层模块系统之间构建了一层平台层架构,即libuv。
单线程的弱点:
- 无法利用多核CPU;
- 错误会引起整个应用退出,应用的健壮性值得考验;
- 大量计算占用CPU导致无法继续调用异步I/O; 像浏览器中JavaScript与UI共用一个线程一样,JavaScript长时间执行会导致UI的渲染和响应被中断。在Node中,长时间的CPU占用也会导致后续的异步I/O发不出调用,已完成的异步I/O的回调函数也会得不到及时执行。为解决单线程的问题,HTML5定制了Web Workers的标准,能够创建工作线程来进行计算,以解决JavaScript大计算阻塞UI渲染的问题。工作线程为了不阻塞主线程,通过消息传递的方式来传递运行结果,这也使得工作线程不能访问到主线程中的UI。 Node采用了与Web Workers相同的思路来解决单线程中大计算量的问题:child_process。子进程的出现,意味着Node可以从容地应对单线程在健壮性和无法利用多核CPU方面的问题。通过将计算分发到各个子进程,可以将大量计算分解掉,然后再通过进程之间的事件消息来传递结果,这可以很好地保持应用模型的简单和低依赖。通过Master-Worker的管理方式,也可以很好地管理各个工作进程,以达到更高的健壮性。
Node对于I/O密集型业务的优势主要在于Node利用事件循环的处理能力,而不是启动每一个线程为每一个请求服务,资源占用极少。
CPU密集型应用给Node带来的挑战主要是:由于JavaScript单线程的原因,如果有长时间运行的计算(比如大循环),将会导致CPU时间片不能释放,使得后续I/O无法发起。Node提供了两种优化方式:
- CPU密集型应用给Node带来的挑战主要是:由于JavaScript单线程的原因,如果有长时间运行的计算(比如大循环),将会导致CPU时间片不能释放,使得后续I/O无法发起。(实测性能可以超过Java)
- 如果单线程的Node不能满足需求,甚至用了C/C++扩展后还觉得不够,那么通过子进程的方式,将一部分Node进程当做常驻服务进程用于计算,然后利用进程间的消息来传递结果,将计算与I/O分离,这样还能充分利用多CPU。
第2章 模块机制
对于JavaScript自身而言,其规范是薄弱的,还有以下缺陷:
- 没有模块系统。
- 标准库较少。(ECMAScript仅定义了部分核心库,对于文件系统,I/O流等常见需求却没有标准的API。)
- 没有标准接口。
- 缺乏包管理系统。
CommonJS规范为JavaScript制定了一个美好的愿景——希望JavaScript能够在任何地方运行。目前,它依旧在成长中,这些规范涵盖了模块、二进制、Buffer、字符集编码、I/O流、进程环境、文件系统、套接字、单元测试、Web服务器网关接口、包管理等。
Node借鉴CommonJS的Modules规范实现了一套非常易用的模块系统。
CommonJS的模块规范:
- 模块引用:
var math = require('math'); - 模块定义:在模块中,上下文提供require()方法来引入外部模块。对应引入的功能,上下文提供了exports对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。在模块中,还存在一个module对象,它代表模块自身,而exports是module的属性。在Node中,一个文件就是一个模块,将方法挂载在exports对象上作为属性即可定义导出的方式 ``` // math.js exports.add = function () { // … };
// program.js
var math = require(‘math’);
exports.increment = function (val) {
return math.add(val, 1);
};
* 模块标识:模块标识其实就是传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以.、..开头的相对路径,或者绝对路径。它可以没有文件名后缀.js。
CommonJS构建的这套模块导出和引入机制使得用户完全不必考虑变量污染,命名空间等方案与之相比相形见绌。
Node的模块实现:Node在实现中并非完全按照规范实现,而是对模块规范进行了一定的取舍,同时也增加了少许自身需要的特性。
在Node中引入模块,需要经历如下3个步骤:
1. 路径分析;
2. 文件定位;
3. 编译执行;
核心模块与文件模块:
在Node中,模块分为两类:一类是Node提供的模块,称为核心模块;另一类是用户编写的模块,称为文件模块。核心模块部分在Node源代码的编译过程中,编译进了二进制执行文件。在Node进程启动时,部分核心模块就被直接加载进内存中,所以这部分核心模块引入时,文件定位和编译执行这两个步骤可以省略掉,并且在路径分析中优先判断,所以它的加载速度是最快的。文件模块则是在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度比核心模块慢。
模块优先从缓存加载:
与前端浏览器会缓存静态脚本文件以提高性能一样,Node对引入过的模块都会进行缓存,以减少二次引入时的开销。不同的地方在于,浏览器仅仅缓存文件,而Node缓存的是编译和执行之后的对象。不论是核心模块还是文件模块,require()方法对相同模块的二次加载都一律采用缓存优先的方式,这是第一优先级的。
模块路径分析:
* 核心模块:优先级仅次于缓存加载,它在Node的源代码编译过程中已经编译为二进制代码,其加载过程最快。
* 路径形式的文件模块:以.、..和/开始的标识符,都被当做文件模块来处理,在分析路径模块时,require()方法会将路径转为真实路径,并以真实路径作为索引,将编译执行后的结果存放到缓存中,以使二次加载时更快。
* 自定义模块:是一种特殊的文件模块,可能是一个文件或者包的形式。在加载的过程中,Node会逐个尝试模块路径中的路径,直到找到目标文件为止,当前文件的路径越深,模块查找耗时会越多。
模块路径:Node在定位文件模块的具体文件时制定的查找策略,具体表现为一个路径组成的数组。(沿路径向上逐级递归,直到根目录下的node_modules目录)
console.log(module.paths);
[ ‘/home/jackson/research/node_modules’, ‘/home/jackson/node_modules’, ‘/home/node_modules’, ‘/node_modules’ ]
从缓存加载的优化策略使得二次引入时不需要路径分析、文件定位和编译执行的过程,大大提高了再次加载模块时的效率。
模块文件定位:
* 文件扩展名分析:当标识符中不包含文件扩展名时,Node会按.js、.json、.node的次序补足扩展名,依次尝试。在尝试的过程中,需要调用fs模块同步阻塞式地判断文件是否存在。因为Node是单线程的,所以这里是一个会引起性能问题的地方。
* 目录分析和包:require()通过分析文件扩展名之后,可能没有查找到对应文件,但却得到一个目录,此时Node会将目录当做一个包来处理。首先,Node在当前目录下查找package.json(CommonJS包规范定义的包描述文件),通过JSON.parse()解析出包描述对象,从中取出main属性指定的文件名进行定位。如果文件名缺少扩展名,将会进入扩展名分析的步骤。如果main属性指定的文件名错误,或者压根没有package.json文件,Node会将index当做默认文件名,然后依次查找index.js、index.node、index.json。
模块编译:
定位到具体的文件后,Node会新建一个模块对象(function Module(id, parent) {...}),然后根据路径载入并编译。对于不同的文件扩展名,其载入方法也有所不同:
* .js 通过fs模块同步读取文件后编译执行。
* .node文件。这是用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。
* .json文件。通过fs模块同步读取文件后,用JSON.parse()解析返回结果。
* 其余扩展名文件都被当做.js文件载入。
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。
如果想对自定义的扩展名进行特殊的加载,可以通过类似require.extensions['.ext']的方式实现。官方不鼓励通过这种方式来进行自定义扩展名的加载,而是期望先将其他语言或文件编译成JavaScript文件后再加载,这样做的好处在于不将烦琐的编译加载等过程引入Node的执行过程中。
JavaScript模块的编译:
在编译的过程中,Node对获取的JavaScript文件内容进行了头尾包装。在头部添加了(function (exports, require, module, __filename, __dirname) {\n,在尾部添加了\n});。一个正常的JavaScript文件会被包装成如下的样子:
(function (exports, require, module, __filename, __dirname) { var math = require(‘math’); exports.area = function (radius) { return Math.PI * radius * radius; }; });
所以在模块内部可以使用如下这些变量:require、exports、module、__filename、__dirname。
这样每个模块文件之间都进行了作用域隔离。包装之后的代码会通过vm原生模块的runInThisContext()方法执行(类似eval,只是具有明确上下文,不污染全局),返回一个具体的function对象。最后,将当前模块对象的exports属性、require()方法、module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个function()执行。在执行之后,模块的exports属性被返回给了调用方。exports属性上的任何方法和属性都可以被外部调用到,但是模块中的其余变量或属性则不可直接被调用。(这就是Node对CommonJS模块规范的实现)
C/C++模块的编译:
.node的模块文件并不需要编译,因为它是编写C/C++模块之后编译生成的,所以这里只有加载和执行的过程。在执行的过程中,模块的exports对象与.node模块产生联系,然后返回给调用者。Node调用process.dlopen()方法进行加载和执行。在Node的架构下,dlopen()方法在Windows和*nix平台下分别有不同的实现,通过libuv兼容层进行了封装。
JSON文件的编译:
JSON文件在用作项目的配置文件时比较有用。如果你定义了一个JSON文件作为配置,那就不必调用fs模块去异步读取和解析,直接调用require()引入即可。此外,你还可以享受到模块缓存的便利,并且二次引入时也没有性能影响。
Node中核心模块其实分为C/C++编写的和JavaScript编写的两部分,其中C/C++文件存放在Node项目的src目录下,JavaScript文件存放在lib目录下。
细节略,大体的实现是将所有内置的JavaScript代码(src/node.js和lib/*.js)转换成C++里的数组,在加载的过程中,JavaScript核心模块经历标识符分析后直接定位到内存中,比普通的文件模块从磁盘中一处一处查找要快很多。与文件模块最重要的区别在于:获取源代码的方式(核心模块是从内存中加载的)以及缓存执行结果的位置。
C++模块主内完成核心,JavaScript主外实现封装的模式是Node能够提高性能的常见方式。Node的buffer、crypto、evals、fs、os等模块都是部分通过C/C++编写的。
其实.node的扩展名只是为了看起来更自然一点,不会因为平台差异产生不同的感觉。实际上,在Windows下它是一个.dll文件,在*nix下则是一个.so文件。为了实现跨平台,dlopen()方法在内部实现时区分了平台,分别用的是加载.so和.dll的方式。普通的扩展模块与内建模块的区别在于无须将源代码编译进Node,而是通过dlopen()方法动态加载。
Node内建模块的编写,略。
包的出现,则是在模块的基础上进一步组织JavaScript代码。包实际上是一个存档文件,即一个目录直接打包为.zip或tar.gz格式的文件,安装后解压还原为目录。完全符合CommonJS规范的包目录应该包含如下这些文件:
* package.json:包描述文件。
* bin:用于存放可执行二进制文件的目录。
* lib:用于存放JavaScript代码的目录。
* doc:用于存放文档的目录。
* test:用于存放单元测试用例的代码。
包描述文件package.json的必备字段:
* name:包名。
* description:包简介。
* version:版本号。
* keywords:键词数组,NPM中主要用来做分类搜索。
* maintainers:包维护者列表。
* contributors:贡献者列表。
* bugs:一个可以反馈bug的网页地址或邮件地址。
* licenses:当前包所使用的许可证列表。
* repositories:托管源代码的位置列表。
* dependencies:使用当前包所需要依赖的包列表。
* homepage:当前包的网站地址。
* os:操作系统支持列表。
* cpu:CPU架构的支持列表。
* engine:支持的JavaScript引擎列表。
* builtin:标志当前包是否是内建在底层系统的标准组件。
* directories:包目录说明。
* implements:实现规范的列表。标志当前包实现了CommonJS的哪些规范。
* scripts:脚本说明对象。它主要被包管理器用来安装、编译、测试和卸载包。
包规范的定义可以帮助Node解决依赖包安装的问题,而NPM正是基于该规范进行了实现。NPM一开始是独立的工具,后来整合进了Node中。NPM实际需要的字段还有另外4个:
* author:包作者。
* bin:一些包作者希望包可以作为命令行工具使用。配置好bin字段后,通过npm install package_name -g命令可以将脚本添加到执行路径中,之后可以在命令行中直接执行。
* main:模块引入方法require()在引入包时,会优先检查这个字段,并将其作为包中其余模块的入口。如果不存在这个字段,require()方法会查找包目录下的index.js、index.node、index.json文件作为默认入口。
* devDependencies:一些模块只在开发时需要依赖。配置这个属性,可以提示包的后续开发者安装依赖包。
CommonJS包规范是理论,NPM是其中的一种实践。对于Node而言,NPM帮助完成了第三方模块的发布、安装和依赖等。借助NPM,Node与第三方模块之间形成了很好的一个生态系统。
全局安装:全局模式并不是将一个模块包安装为一个全局包的意思,它并不意味着可以从任何地方通过require()来引用到它。全局模式这个称谓其实并不精确,存在诸多误导。实际上,-g是将一个包安装为全局可用的可执行命令。它根据包描述文件中的bin字段配置,将实际脚本链接到与Node可执行文件相同的路径下:
“bin”: { “express”: “./bin/express” },
事实上,通过全局模式安装的所有模块包都被安装进了一个统一的目录下,这个目录可以通过如下方式推算出来:
path.resolve(process.execPath, ‘..’, ‘..’, ‘lib’, ‘node_modules’);
如果Node可执行文件的位置是/usr/local/bin/node,那么模块目录就是/usr/local/lib/node_modules。最后,通过软链接的方式将bin字段配置的可执行文件链接到Node的可执行目录下。
本地安装:可以通过将包下载到本地,然后以本地安装。本地安装只需为NPM指明package.json文件所在的位置即可:它可以是一个包含package.json的存档文件,也可以是一个URL地址,也可以是一个目录下有package.json文件的目录位置。
通过镜像源安装:--registry=http://registry.url
发布包:
* 注册仓库账号:
$ npm adduser Username: (jacksontian) Email: (shyvo1987@gmail.com)
* 上传包:
$ npm publish . npm http PUT http://registry.npmjs.org/hello_test_jackson …
在这个过程中,NPM会将目录打包为一个存档文件,然后上传到官方源仓库中。
分析包:分析出当前路径下能够通过模块路径找到的所有包,并生成依赖树
$ npm ls /Users/jacksontian ├─┬ connect@2.0.3 │ ├── crc@0.1.0 │ ├── debug@0.6.0 │ ├── formidable@1.0.9 │ ├── mime@1.2.4 │ └── qs@0.4.2 ├── hello_test_jackson@0.0.1 └── urllib@0.2.3
局域NPM,略。
鉴于网络的原因,CommonJS为后端JavaScript制定的规范并不完全适合前端的应用场景(Node的模块引入过程,几乎全都是同步的)。经过一段争执之后,AMD规范最终在前端应用场景中胜出。
AMD规范:
define(id?, dependencies?, factory);
模块id和依赖是可选的,与Node模块相似的地方在于factory的内容就是实际代码的内容。
CMD规范:与AMD规范的主要区别在于定义模块和依赖引入的部分。AMD需要在声明模块的时候指定所有的依赖,通过形参传递依赖到模块内容中,与AMD模块规范相比,CMD模块更接近于Node对CommonJS规范的定义,在依赖部分,CMD支持动态引入,示例如下:
define(function(require, exports, module) { // The module code goes here });
兼容Node、AMD、CMD以及常见的浏览器环境:
;(function (name, definition) { // 检测上下文环境是否为AMD或CMD var hasDefine = typeof define === ‘function’, // 检查上下文环境是否为Node hasExports = typeof module !== ‘undefined’ && module.exports;
if (hasDefine) { // AMD环境或CMD环境 define(definition); } else if (hasExports) { // 定义为普通Node模块 module.exports = definition(); } else { // 将模块的执行结果挂在window变量中,在浏览器中this指向window对象 this[name] = definition(); } })(‘hello’, function () { var hello = function () {}; return hello; });
# 第3章 异步I/O
异步早就存在于操作系统的底层。在底层系统中,异步通过信号量、消息等方式有了广泛的应用。
在众多高级编程语言或运行平台中,将异步作为主要编程方式和设计理念的,Node是首个。
Node与Nginx的区别:Nginx同样采用事件驱动、异步I/O设计的理念,采用纯C编写,性能表现非常优异。它们的区别在于,Nginx具备面向客户端管理连接的强大能力,但是它的背后依然受限于各种同步方式的编程语言。但Node却是全方位的,既可以作为服务器端去处理客户端带来的大量并发请求,也能作为客户端向网络中的各个应用进行并发请求。
单线程同步编程模型会因阻塞I/O导致硬件资源得不到更优的使用。多线程编程模型也因为编程中的死锁、状态同步等问题让开发人员头疼。Node在两者之间给出了它的方案:利用单线程,远离多线程死锁、状态同步等问题;利用异步I/O,让单线程远离阻塞,以更好地使用CPU。
操作系统内核对于I/O只有两种方式:阻塞与非阻塞。阻塞I/O的一个特点是调用之后一定要等到系统内核层面完成所有操作后(复制数据到内存中),调用才结束。
轮询技术:为了提高性能,内核提供了非阻塞I/O。非阻塞I/O跟阻塞I/O的差别为调用之后会立即返回。但非阻塞I/O是不带数据直接返回,要获取数据,还需要通过文件描述符再次读取。由于完整的I/O并没有完成,立即返回的并不是业务层期望的数据,而仅仅是当前调用的状态。为了获取完整的数据,应用程序需要重复调用I/O操作来确认是否完成。这种重复调用判断操作是否完成的技术叫做轮询。现存的轮询技术主要有以下这些:
* read:最原始的方式,通过重复调用来检查I/O的状态。
* select:通过对文件描述符上的事件状态来进行判断,由于它采用一个1024长度的数组来存储状态,所以它最多可以同时检查1024个文件描述符。
* poll:较select有所改进,采用链表的方式避免数组长度的限制,但是当文件描述符较多的时候,它的性能还是十分低下的。
* epoll:Linux下效率最高的I/O事件通知机制,在进入轮询的时候如果没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒。它是真实利用了事件通知、执行回调的方式,而不是遍历查询,所以不会浪费CPU,执行效率较高。
* kqueue:实现方式与epoll类似,不过它仅在FreeBSD系统下存在。
轮询技术满足了非阻塞I/O确保获取完整数据的需求,但是对于应用程序而言,它仍然只能算是一种同步,因为应用程序仍然需要等待I/O完全返回,依旧花费了很多时间来等待。等待期间,CPU要么用于遍历文件描述符的状态,要么用于休眠等待事件发生。结论是它不够好。
理想的非阻塞异步I/O:完美的异步I/O应该是应用程序发起非阻塞调用,无须通过遍历或者事件唤醒等方式轮询,可以直接处理下一个任务,只需在I/O完成后通过信号或回调将数据传递给应用程序即可。在Linux下存在这样一种方式,它原生提供的一种异步I/O方式(AIO)就是通过信号或回调来传递数据的。但它有缺陷——AIO仅支持内核I/O中的O_DIRECT方式读取,导致无法利用系统缓存。
通过让部分线程进行阻塞I/O或者非阻塞I/O加轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将I/O得到的数据进行传递,这就轻松实现了异步I/O(尽管它是模拟的)。glibc的AIO便是典型的线程池模拟异步I/O。在Node v0.9.3中,自行实现了线程池来完成异步I/O。在Windows平台下采用了IOCP实现异步I/O。由于Windows平台和*nix平台的差异,Node提供了libuv作为抽象封装层。
Node”单线程“的理解:需要强调的地方在于我们时常提到Node是单线程的,这里的单线程仅仅只是JavaScript执行在单线程中罢了。在Node中,无论是*nix还是Windows平台,内部完成I/O任务的另有线程池。
事件循环、观察者、请求对象、I/O线程池这四者共同构成了Node异步I/O模型的基本要素。
事件循环:Node自身的执行模型,正是它使得回调函数十分普遍。在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们称为Tick。每个Tick的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程。
观察者:每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。浏览器采用了类似的机制。事件可能来自用户的点击或者加载某些文件时产生,而这些产生的事件都有对应的观察者。在Node中,事件主要来源于网络请求、文件I/O等,这些事件对应的观察者有文件I/O观察者、网络I/O观察者等。
请求对象:从JavaScript发起调用到内核执行完I/O操作的过渡过程中,存在一种中间产物,它叫做请求对象。请求对象是异步I/O过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行以及I/O操作完毕后的回调处理。组装好请求对象、送入I/O线程池等待执行,实际上完成了异步I/O的第一部分,回调通知是第二部分。
立即异步执行一个任务:由于事件循环自身的特点,定时器的精确度不够。而事实上,采用定时器需要动用红黑树,创建定时器对象和迭代等操作,而setTimeout(fn, 0)的方式较为浪费性能。实际上,process.nextTick()方法的操作相对较为轻量。每次调用process.nextTick()方法,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的操作时间复杂度为O(lg(n)),nextTick()的时间复杂度为O(1)。
事件驱动的实质:即通过主循环加事件触发的方式来运行程序,它与浏览器中的执行模型基本保持了一致。。
Node Web服务器的原理:网络套接字上侦听到的请求都会形成事件交给I/O观察者。事件循环会不停地处理这些网络I/O事件。如果JavaScript有传入回调函数,这些事件将会最终传递到业务逻辑层进行处理。利用Node构建Web服务器,正是在这样一个基础上实现的。每线程/每请求的方式目前还被Apache所采用。Node通过事件驱动的方式处理请求,无须为每一个请求创建额外的对应线程,可以省掉创建线程和销毁线程的开销,同时操作系统在调度任务时因为线程较少,上下文切换的代价很低。这使得服务器能够有条不紊地处理请求,即使在大量连接的情况下,也不受线程上下文切换开销的影响,这是Node高性能的一个原因。
事实上,Node的异步I/O并非首创,但却是第一个成功的平台。因为在那些成熟的语言平台上,异步不是主流,尽管有这些事件驱动的实现库,但开发者总会习惯性地采用同步I/O库,这导致预想的高性能直接落空。
# 第4章 异步编程
高阶函数:可以把函数作为参数,或是将函数作为返回值的函数,如:
function foo(x) { return function () { return x; }; }
后续传递风格:高阶函数比普通的函数要灵活许多。除了通常意义的函数调用返回外,还形成了一种后续传递风格(Continuation Passing Style)的结果接收方式,而非单一的返回值形式。后续传递风格的程序编写将函数的业务重点从返回值转移到了回调函数中:
function foo(x, bar) { return bar(x); }
事件的处理方式正是基于高阶函数的特性来完成的。在自定义事件实例中,通过为相同事件注册不同的回调函数,可以很灵活地处理业务逻辑。
偏函数:创建一个调用另外一个部分——参数或变量已经预置的函数——的函数的用法(通过指定部分参数来产生一个新的定制函数)。
var isType = function (type) { return function (obj) { return toString.call(obj) == ‘[object ‘ + type + ‘]’; }; };
var isString = isType(‘String’); var isFunction = isType(‘Function’);
提升性能的方式过去多用多线程的方式解决,另一个解决I/O性能的方案是通过C/C++调用操作系统底层接口,自己手工完成异步I/O。Node利用JavaScript及其内部异步库,将异步直接提升到业务层面,这是一种创新。
Node带来的最大特性莫过于基于事件驱动的非阻塞I/O模型,这是它的灵魂所在。
尝试对异步方法进行try/catch操作只能捕获当次事件循环内的异常,对callback执行时抛出的异常将无能为力。Node在处理异常上形成了一种约定,将异常作为回调函数的第一个实参传回,如果为空值,则表明异步调用没有异常抛出:
async(function (err, results) { // TODO });
在编写异步方法时,只要将异常正确地传递给用户的回调方法即可,无须过多处理。
浏览器提出了Web Workers,它通过将JavaScript执行与UI渲染分离,可以很好地利用多核CPU为大量计算服务。同时前端Web Workers也是一个利用消息机制合理使用多核CPU的理想模型。
目前异步编程的主要解决方案有3种:事件发布/订阅模式、Promise/Deferred模式、流程控制库。
事件发布/订阅模式:Node自身提供的events模块是发布/订阅模式的一个简单实现,在Node提供的核心模块中,有近半数都继承自EventEmitter。比如Stream:
var events = require(‘events’); function Stream() { events.EventEmitter.call(this); } util.inherits(Stream, events.EventEmitter);
// 订阅
emitter.on(“event1”, function (message) {
console.log(message);
});
// 发布
emitter.emit(‘event1’, “I am message!”);
在事件订阅/发布模式中,通常也有一个once()方法,通过它添加的侦听器只能执行一次,在执行之后就会将它与事件的关联移除。这个特性常常可以帮助我们过滤一些重复性的事件响应。
在异步编程中,也会出现事件与侦听器的关系是多对一的情况,也就是说一个业务逻辑可能依赖两个通过回调或事件传递的结果,回调嵌套过深的原因即是如此。由于多个异步场景中回调函数的执行并不能保证顺序,且回调函数之间互相没有任何交集,所以需要借助一个第三方函数和第三方变量来处理异步协作的结果。通常把这个用于检测次数的变量叫做哨兵变量,如下代码实现事件与侦听器的多对一:
```js
var after = function (times, callback) {
var count = 0, results = {};
return function (key, value) {
results[key] = value;
count++;
if (count === times) {
callback(results);
}
};
};
var done = after(times, render);
使用事件的方式时,执行流程需要被预先设定。即便是分支,也需要预先设定,这是由发布/订阅模式的运行机制所决定的。Promise/Deferred是一种先执行异步调用,延迟传递处理的方式。 具体实现。
其他异步编程流程控制方式,详略。
第5章 内存控制
在Node中通过JavaScript使用内存时就会发现只能使用部分内存(64位系统下约为1.4 GB,32位系统下约为0.7 GB)。在这样的限制下,将会导致Node无法直接操作大内存对象。至于V8为何要限制堆的大小,表层原因为V8最初为浏览器而设计,不太可能遇到用大量内存的场景。对于网页来说,V8的限制值已经绰绰有余。深层原因是V8的垃圾回收机制的限制。
Buffer对象不同于其他对象,它不经过V8的内存分配机制,所以也不会有堆内存的大小限制。
V8的垃圾回收策略主要基于分代式垃圾回收机制。按对象的存活时间将内存的垃圾回收进行不同的分代,然后分别对不同分代的内存施以更高效的算法。在V8中,主要将内存分为新生代和老生代两代。新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。
Scavenge算法:在分代的基础上,新生代中的对象主要通过Scavenge算法进行垃圾回收。将堆内存一分为二,只有一个处于使用中,另一个处于闲置状态。处于使用状态的空间称为From空间,处于闲置状态的空间称为To空间。当我们分配对象时,先是在From空间中进行分配。当开始进行垃圾回收时,会检查From空间中的存活对象,这些存活对象将被复制到To空间中,而非存活对象占用的空间将会被释放。完成复制后,From空间和To空间的角色发生对换。缺点是只能使用堆内存中的一半,但Scavenge由于只复制存活的对象,并且对于生命周期短的场景存活对象只占少部分,所以它在时间效率上有优异的表现。 由于Scavenge是典型的牺牲空间换取时间的算法,所以无法大规模地应用到所有的垃圾回收中。但可以发现,Scavenge非常适合应用在新生代中,因为新生代中对象的生命周期较短,恰恰适合这个算法。
Mark-Sweep & Mark-Compact算法: 对象从From空间中复制到To空间时,会检查它的内存地址来判断这个对象是否已经经历过一次Scavenge回收。如果已经经历过了,会将该对象从From空间复制到老生代空间中,如果没有,则复制到To空间中。另一个判断条件是To空间的内存占用比。当要从From空间复制一个对象到To空间时,如果To空间已经使用了超过25%,则这个对象直接晋升到老生代空间中。
Mark-Sweep是标记清除的意思,它分为标记和清除两个阶段。与Scavenge相比,Mark-Sweep并不将内存空间划分为两半,所以不存在浪费一半空间的行为。与Scavenge复制活着的对象不同,Mark-Sweep在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。可以看出,Scavenge中只复制活着的对象,而Mark-Sweep只清理死亡对象。活对象在新生代中只占较小部分,死对象在老生代中只占较小部分,这是两种回收方式能高效处理的原因。
Mark-Sweep最大的问题是在进行一次标记清除回收后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题。Mark-Compact是标记整理的意思,是在Mark-Sweep的基础上演变而来的。它们的差别在于对象在标记为死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。
为了降低全堆垃圾回收带来的停顿时间,V8先从标记阶段入手,将原本要一口气停顿完成的动作改为增量标记(incremental marking),也就是拆分为许多小“步进”,每做完一“步进”就让JavaScript应用逻辑执行一小会儿,垃圾回收与应用逻辑交替执行直到标记阶段完成。
在JavaScript中能形成作用域的有函数调用、with以及全局作用域。由于标识符的查找方向是向上的,所以变量只能向外访问,而不能向内访问。在JavaScript中,实现外部作用域访问内部作用域中变量的方法叫做闭包(closure)。这得益于高阶函数的特性:函数可以作为参数或者返回值。它的问题在于,一旦有变量引用这个中间函数,这个中间函数将不会释放,同时也会使原始的作用域不会得到释放,作用域中产生的内存占用也不会得到释放。除非不再有引用,才会逐步释放。
如果需要释放常驻内存的对象,可以通过delete操作来删除引用关系。或者将变量重新赋值,让旧的对象脱离引用关系。但是在V8中通过delete删除对象的属性有可能干扰V8的优化,所以通过赋值方式解除引用更好。
查看内存使用情况:process.memoryUsage()可以查看内存使用情况。除此之外,os模块中的totalmem()和freemem()方法也可以查看内存使用情况。
尽管内存泄漏的情况不尽相同,但其实质只有一个,那就是应当回收的对象出现意外而没有被回收,变成了常驻在老生代中的对象。
在Node中,缓存并非物美价廉。一旦一个对象被当做缓存来使用,那就意味着它将会常驻在老生代中。缓存中存储的键越多,长期存活的对象也就越多,这将导致垃圾回收在进行扫描和整理时,对这些对象做无用功,(严格意义的缓存有着完善的过期策略,而普通对象的键值对并没有),所以在Node中,任何试图拿内存当缓存的行为都应当被限制。
由于通过exports导出的函数,可以访问文件模块中的私有变量,这样每个文件模块在编译执行后形成的作用域因为模块缓存的原因,不会被释放。由于模块的缓存机制,模块是常驻老生代的。在设计模块时,要十分小心内存泄漏的出现。
Node提供了stream模块用于处理大文件。由于V8的内存限制,我们无法通过fs.readFile()和fs.writeFile()直接进行大文件的操作,而改用fs.createReadStream()和fs.createWriteStream()方法通过流的方式实现对大文件的操作。
第6章 理解Buffer
在应用中通常会操作字符串,但一旦在网络中传输,都需要转换为Buffer,以进行二进制数据传输。
字符串与Buffer之间有实质上的差异,即Buffer是二进制数据,字符串与Buffer之间存在编码关系。
Buffer是一个典型的JavaScript与C++结合的模块,它将性能相关部分用C++实现,将非性能相关的部分用JavaScript实现。Buffer所占用的内存不是通过V8分配的,属于堆外内存。
简单而言,真正的内存是在Node的C++层面提供的,JavaScript层面只是使用它。当进行小而频繁的Buffer操作时,采用slab的机制进行预先申请和事后分配,使得JavaScript到操作系统之间不必有过多的内存申请方面的系统调用。对于大块的Buffer而言,则直接使用C++层面提供的内存,而无需细腻的分配操作。
Buffer的转换,不支持GBK、GB2312和BIG-5编码,详略。
中文字在UTF-8下占3个字节。所以第一个Buffer对象在输出时,只能显示3个字符,Buffer中剩下的2个字节(e6 9c)将会以乱码的形式显示。对于任意长度的Buffer而言,宽字节字符串都有可能存在被截断的情况,只不过Buffer的长度越大出现的概率越低而已。可读流有一个设置编码的方法setEncoding(),可以用来避免这种问题(原理是对于未完成的字节序列在内部先buffer住)。
通过预先转换静态内容为Buffer对象,可以有效地减少CPU的重复使用,节省服务器资源。在Node构建的Web应用中,可以选择将页面中的动态内容和静态内容分离,静态内容部分可以通过预先转换为Buffer的方式,使性能得到提升:
var http = require('http');
var helloworld = "";
for (var i = 0; i < 1024 * 10; i++) {
helloworld += "a";
}
// helloworld = new Buffer(helloworld); // 性能提高一倍
http.createServer(function (req, res) {
res.writeHead(200);
res.end(helloworld);
}).listen(8001);
第7章 网络编程
Node提供了net、dgram、http、https这4个模块,分别用于处理TCP、UDP、HTTP、HTTPS,适用于服务器端和客户端。
也可以对Domain Socket进行监听:
server.listen('/tmp/echo.sock');
TCP服务的事件:对于通过net.createServer()创建的服务器而言,它是一个EventEmitter实例,它的自定义事件有如下几种:
- listening:在调用server.listen()绑定端口或者Domain Socket后触发。
- connection:每个客户端套接字连接到服务器端时触发。
- close:当服务器关闭时触发,在调用server.close()后,服务器将停止接受新的套接字连接,但保持当前存在的连接,等待所有连接都断开后,会触发该事件。
- error:当服务器发生异常时,将会触发该事件。
TCP连接事件(连接建立之后):服务器可以同时与多个客户端保持连接,对于每个连接而言是典型的可写可读Stream对象。 Stream对象可以用于服务器端和客户端之间的通信,既可以通过data事件从一端读取另一端发来的数据,也可以通过write()方法从一端向另一端发送数据。它具有如下自定义事件:
- data:当一端调用write()发送数据时,另一端会触发data事件,事件传递的数据即是write()发送的数据。
- end:当连接中的任意一端发送了FIN数据时,将会触发该事件。
- connect:该事件用于客户端,当套接字与服务器端连接成功时会被触发。
- drain:当任意一端调用write()发送数据时,当前这端会触发该事件。
- error:当异常发生时,触发该事件。
- close:当套接字完全关闭时,触发该事件。
- timeout:当一定时间后连接不再活跃时,该事件将会被触发,通知用户当前该连接已经被闲置了。
尽管在网络的一端调用write()会触发另一端的data事件,但是并不意味着每次write()都会触发一次data事件,在关闭掉Nagle算法后,另一端可能会将接收到的多个小数据包合并,然后只触发一次data事件。
UDP套接字一旦创建,既可以作为客户端发送数据,也可以作为服务器端接收数据。
调用HTTP客户端同时对一个服务器发起10次HTTP请求时,其实质只有5个请求处于并发状态,后续的请求需要等待某个请求完成服务后才真正发出。这与浏览器对同一个域名有下载连接数的限制是相同的行为。如果在服务器端通过ClientRequest调用网络中的其他HTTP服务,记得关注代理对象对网络请求的限制。 也可以设置agent选项为false值,以脱离连接池的管理,使得请求不受并发的限制。
HTTP服务端和客户端事件,代码,略。
WebSocket之前,网页客户端与服务器端进行通信最高效的是Comet技术。实现Comet技术的细节是采用长轮询(long-polling)或iframe流。
WebSocket的握手部分是由HTTP完成的(使人觉得它可能是基于HTTP实现的),客户端建立连接时,通过HTTP发起请求报文:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
其中:
Upgrade: websocket
Connection: Upgrade
表示请求服务器端升级协议为WebSocket。
Sec-WebSocket-Key
用于安全校验,值是随机生成的Base64编码的字符串。服务器端接收到之后将其与字符串258EAFA5-E914-47DA-95CA-C5AB0DC85B11相连,形成字符串dGhlIHNhbXBsZSBub25jZQ==258EAFA5- E914-47DA-95CA-C5AB0DC85B11,然后通过sha1安全散列算法计算出结果后,再进行Base64编码,最后返回给客户端。
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
这两个字段指定子协议和版本号。
服务器端在处理完请求后,响应如下报文:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: chat
在握手顺利完成后,当前连接将不再进行HTTP的交互,而是开始WebSocket的数据帧协议,实现客户端与服务器端的数据交换。
为了安全考虑,客户端需要对发送的数据帧进行掩码处理,服务器一旦收到无掩码帧(比如中间拦截破坏),连接将关闭。而服务器发送到客户端的数据帧则无须做掩码处理,同样,如果客户端收到带掩码的数据帧,连接也将关闭。
Node在网络安全上提供了3个模块,分别为crypto、tls、https。
TLS/SSL是一个公钥/私钥的结构,它是一个非对称的结构,每个服务器端和客户端都有自己的公私钥。在建立安全传输之前,客户端和服务器端之间需要互换公钥。客户端发送数据时要通过服务器端的公钥进行加密,服务器端发送数据时则需要客户端的公钥进行加密。
HTTPS协议介绍,详略。
第8章 构建Web应用
request事件发生于网络连接建立,客户端向服务器端发送报文,服务器端解析报文,发现HTTP请求的报头时。在已触发reqeust事件前,它已准备好ServerRequest和ServerResponse对象以供对请求和响应报文的操作。
Cookie、Session、数据上传等,详略。
中间件,细节略。
Content-Disposition字段影响的行为是客户端会根据它的值判断是应该将报文数据当做即时浏览的内容,还是可下载的附件。当内容只需即时查看时,它的值为inline,当数据可以存为附件时,它的值为attachment。另外,Content-Disposition字段还能通过参数指定保存时应该使用的文件名:
Content-Disposition: attachment; filename="filename.ext"
第9章 玩转进程
服务模型的变迁:
- 同步;
- 复制进程;
- 多线程;
- 事件驱动;
基于单线程、事件驱动的服务模型存在两个问题:CPU的利用率和进程的健壮性。
PHP也是单线程架构,它的健壮性是由它给每个请求都建立独立的上下文来实现的。但是对于Node来说,所有请求的上下文都是统一的。
Node提供了child_process模块,并且也提供了child_process.fork()函数以实现进程的复制。
根据当前机器上的CPU数量复制出对应Node进程数:
var fork = require('child_process').fork;
var cpus = require('os').cpus();
for (var i = 0; i < cpus.length; i++) {
fork('./worker.js');
}
Master-Worker模式:主进程不负责具体的业务处理,而是负责调度或管理工作进程,它是趋向于稳定的。工作进程负责具体的业务处理。通过fork()复制的进程都是一个独立的进程,这个进程中有着独立而全新的V8实例。它需要至少30毫秒的启动时间和至少10 MB的内存。
child_process提供了4个方法用于创建子进程:
- spawn():启动一个子进程来执行命令。
- exec():启动一个子进程来执行命令,与spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况。
- execFile():启动一个子进程来执行可执行文件。
- fork():与spawn()类似,不同点在于它创建Node的子进程只需指定要执行的JavaScript文件模块即可。
进程间通信:主线程与工作线程之间通过onmessage()和postMessage()进行通信,子进程对象则由send()方法实现主进程向子进程发送数据,message事件实现收听子进程发来的数据。通过fork()或者其他API,创建子进程之后,为了实现父子进程之间的通信,父进程与子进程之间将会创建IPC通道。通过IPC通道,父子进程之间才能通过message和send()传递消息。
父进程在实际创建子进程之前,会创建IPC通道并监听它,然后才真正创建出子进程,并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个IPC通道的文件描述符。子进程在启动的过程中,根据文件描述符去连接这个已存在的IPC通道,从而完成父子进程之间的连接。
由于IPC通道是用命名管道或Domain Socket创建的,它们与网络socket的行为比较类似,属于双向通信。不同的是它们在系统内核中就完成了进程间的通信,而不用经过实际的网络层,非常高效。在Node中,IPC通道被抽象为Stream对象,在调用send()时发送数据(类似于write()),接收到的消息会通过message事件(类似于data)触发给应用层。
由于进程每接收到一个连接,将会用掉一个文件描述符,因此代理方案中客户端连接到代理进程,代理进程连接到工作进程的过程需要用掉两个文件描述符。操作系统的文件描述符是有限的,代理方案浪费掉一倍数量的文件描述符的做法影响了系统的扩展能力。为了解决上述这样的问题,Node在版本v0.5.9引入了进程间发送句柄的功能。send()方法除了能通过IPC发送数据外,还能发送句柄。主进程接收到socket请求后,将这个socket直接发送给工作进程,而不是重新与工作进程之间建立新的socket连接来转发数据: 主进程代码:
// parent.js
var cp = require('child_process');
var child1 = cp.fork('child.js');
var child2 = cp.fork('child.js');
// Open up the server object and send the handle
var server = require('net').createServer();
server.listen(1337, function () {
child1.send('server', server);
child2.send('server', server);
// 关掉
server.close();
});
子进程代码:
// child.js
var http = require('http');
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
});
process.on('message', function (m, tcp) {
if (m === 'server') {
tcp.on('connection', function (socket) {
server.emit('connection', socket);
});
}
});
句柄发送与还原,详略。
独立启动的进程中,TCP服务器端socket套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。Node底层对每个端口监听都设置了SO_REUSEADDR选项,这个选项的涵义是不同进程可以就相同的网卡和端口进行监听,这个服务器端套接字可以被不同的进程复用:
setsockopt(tcp->io_watcher.fd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on))
由于独立启动的进程互相之间并不知道文件描述符,所以监听相同端口时就会失败。但对于send()发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常。 多个应用监听相同端口时,文件描述符同一时间只能被某个进程所用。换言之就是网络请求向服务器端发送时,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求进行服务。这些进程服务是抢占式的。
异常进程自动重启,详略。
Node默认提供的机制是采用操作系统的抢占式策略。
为此Node在v0.11中提供了一种新的策略使得负载均衡更合理,这种新的策略叫Round-Robin,又叫轮叫调度。轮叫调度的工作方式是由主进程接受连接,将其依次分发给工作进程。分发的策略是在N个工作进程中,每次选择第i = (i + 1) mod n个进程来发送连接。在cluster模块中启用它的方式如下:
// 启用Round-Robin
cluster.schedulingPolicy = cluster.SCHED_RR
// 不启用Round-Robin
cluster.schedulingPolicy = cluster.SCHED_NONE
可以避免CPU和I/O繁忙差异导致的负载不均衡。Round-Robin策略也可以通过代理服务器来实现,但是它会导致服务器上消耗的文件描述符是平常方式的两倍。
事实上cluster模块就是child_process和net模块的组合应用。cluster启动时,它会在内部启动TCP服务器,在cluster.fork()子进程时,将这个TCP服务器端socket的文件描述符发送给工作进程。如果进程是通过cluster.fork()复制出来的,那么它的环境变量里就存在NODE_UNIQUE_ID,如果工作进程中存在listen()侦听网络端口的调用,它将拿到该文件描述符,通过SO_REUSEADDR端口重用,从而实现多个子进程共享端口。对于普通方式启动的进程,则不存在文件描述符传递共享等事情。
第10章 测试
略。
第11章 产品化
略。
附录。 略。
