- 第 1 章 概述
- 第 2 章 物理层
- 第 3 章 数据链路层
- 第 4 章 网络层
- 第 5 章 运输层
- 第 6 章 应用层
- 第 7 章 网络安全
- 第 8 章 因特网上的音频/视频服务
- 第 9 章 无线网络
- 第 10 章 下一代因特网
第 1 章 概述
两种通信方式:在网络边缘的端系统中运行的程序之间的通信方式通常可划分为两大类:客户服务器方式(C/S 方式)、对等方式(P2P 方式)。
分组交换带来的问题:分组在各结点存储转发时需要排队,这就会造成一定的时延。分组必须携带的首部(里面有必不可少的控制信息)也造成了一定的开销。
计算机网络的性能指标
1.速率即数据率(data rate)或比特率(bit rate)是计算机网络中最重要的一个性能指标。速率的单位是 b/s,或kb/s, Mb/s, Gb/s 等。速率往往是指额定速率或标称速率。
2.带宽是数字信道所能传送的“最高数据率”的同义语,单位是“比特每秒”,或 b/s (bit/s)。
3.吞吐量(throughput)表示在单位时间内通过某个网络(或信道、接口)的数据量。更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。
4.时延:数据经历的总时延就是发送时延、传播时延、处理时延和排队时延之和: 传输时延(发送时延):发送数据时,数据块从结点进入到传输媒体所需要的时间。也就是从发送数据帧的第一个比特算起,到该帧的最后一个比特发送完毕所需的时间。
5.时延带宽积:时延带宽积 = 传播时延*带宽;链路的时延带宽积又称为以比特为单位的链路长度。
6.利用率:信道利用率指出某信道有百分之几的时间是被利用的(有数据通过)。完全空闲的信道的利用率是零。网络利用率则是全网络的信道利用率的加权平均值。信道利用率并非越高越好。根据排队论的理论,当某信道的利用率增大时,该信道引起的时延也就迅速增加。
网络的体系结构
OSI的七层协议:应用层、表示层、会话层、运输层、网络层、数据链路层、物理层;
具有五层协议的体系结构 :TCP/IP 是四层的体系结构:应用层、运输层、网际层和网络接口层。但最下面的网络接口层并没有具体内容。因此往往采取折中的办法,即综合 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构 。
第 2 章 物理层
数据(data)——运送消息的实体。
信号(signal)——数据的电气的或电磁的表现。
“模拟的”(analogous)——代表消息的参数的取值是连续的。
“数字的”(digital)——代表消息的参数的取值是离散的。
码元(code)——在使用时间域(或简称为时域)的波形表示数字信号时,代表不同离散数值的基本波形。
基带信号(即基本频带信号)——来自信源的信号。像计算机输出的代表各种文字或图像文件的数据信号都属于基带信号。
带通信号——把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道)。
最基本的二元制调制方法
调幅(AM):载波的振幅随基带数字信号而变化。
调频(FM):载波的频率随基带数字信号而变化。
调相(PM) :载波的初始相位随基带数字信号而变化。
多模光纤与单模光纤
可以存在许多条不同角度入射的光线在一条光纤中传输的光纤称为多模光纤。多模光纤只适合于近距离传输。若光纤的直径减小到只有一个光的波长,即可使光纤一直向前传播,而不会产生多次反射,这样的光纤就称为单模光纤。
信道复用技术
1.频分复用:用户在分配到一定的频带后,在通信过程中自始至终都占用这个频带。频分复用的所有用户在同样的时间占用不同的带宽资源。
2.时分复用:将时间划分为一段段等长的时分复用帧(TDM 帧)。每一个时分复用的用户在每一个 TDM 帧中占用固定序号的时隙。时分复用的所有用户是在不同的时间占用同样的频带宽度。时分复用可能会造成线路资源的浪费
3.统计时分复用 STDM:STDM帧不是固定分配时隙,而是按需动态地分配时隙,因此也称为异步时分复用。
4.波分复用 WDM:波分复用就是光的频分复用。
5.码分复用 CDM:常用的名词是码分多址 CDMA ,各用户使用经过特殊挑选的不同码型,因此彼此不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
xDSL 技术就是用数字技术对现有的模拟电话用户线进行改造,使它能够承载宽带业务。xDSL 技术就把 0~4 kHz 低端频谱留给传统电话使用,而把原来没有被利用的高端频谱留给用户上网使用。
ADSL 的特点:上行和下行带宽做成不对称的。上行指从用户到 ISP,而下行指从 ISP 到用户。ADSL 在用户线(铜线)的两端各安装一个 ADSL 调制解调器。
光纤同轴混合网HFC:HFC 网是在目前覆盖面很广的有线电视网 CATV 的基础上开发的一种居民宽带接入网。HFC 网除可传送 CATV 外,还提供电话、数据和其他宽带交互型业务。
第 3 章 数据链路层
数据链路层使用的信道主要有以下两种类型:点对点信道、广播信道;
三个基本问题
1.封装成帧:在一段数据的前后分别添加首部和尾部,然后就构成了一个帧。确定帧的界限。首部和尾部的一个重要作用就是进行帧定界。
2.透明传输:用字节填充法解决透明传输的问题;
3.差错检测:在数据链路层传送的帧中,广泛使用了循环冗余检验 CRC 的检错技术。
帧检验序列 FCS :在数据后面添加上的冗余码称为帧检验序列 FCS (Frame Check Sequence)。 循环冗余检验 CRC 和帧检验序列 FCS并不等同。CRC 是一种常用的检错方法,而 FCS 是添加在数据后面的冗余码。FCS 可以用 CRC 这种方法得出,但 CRC 并非用来获得 FCS 的唯一方法。
应当注意仅用循环冗余检验 CRC 差错检测技术只能做到无差错接受。要做到“可靠传输”(即发送什么就收到什么)就必须再加上确认和重传机制。
点对点协议 PPP
现在全世界使用得最多的数据链路层协议是点对点协议 PPP (Point-to-Point Protocol)。用户使用拨号电话线接入因特网时,一般都是使用 PPP 协议。
PPP 协议应满足的需求:简单、封装成帧、透明性、多种网络层协议、多种类型链路、差错检测、检测连接状态、最大传送单元、网络层地址协商、数据压缩协商;
PPP 协议不需要的功能:纠错、流量控制、序号、多点线路、半双工或单工链路;
PPP 协议有三个组成部分:
1.一个将 IP 数据报封装到串行链路的方法。
2.链路控制协议 LCP (Link Control Protocol)。
3.网络控制协议 NCP (Network Control Protocol)。
PPP 协议的帧格式
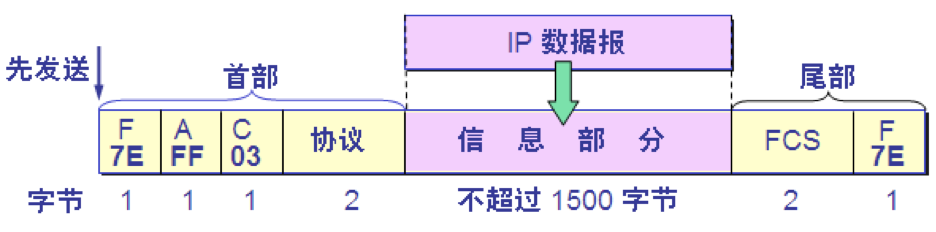 1.标志字段 F = 0x7E。
2.地址字段 A 只置为 0xFF。地址字段实际上并不起作用。
3.控制字段 C 通常置为 0x03。
4.PPP 有一个 2 个字节的协议字段:
当协议字段为 0x0021 时,PPP 帧的信息字段就是IP 数据报。
若为 0xC021, 则信息字段是 PPP 链路控制数据。
若为 0x8021,则表示这是网络控制数据。
1.标志字段 F = 0x7E。
2.地址字段 A 只置为 0xFF。地址字段实际上并不起作用。
3.控制字段 C 通常置为 0x03。
4.PPP 有一个 2 个字节的协议字段:
当协议字段为 0x0021 时,PPP 帧的信息字段就是IP 数据报。
若为 0xC021, 则信息字段是 PPP 链路控制数据。
若为 0x8021,则表示这是网络控制数据。
PPP 是面向字节的,所有的 PPP 帧的长度都是整数字节。
透明传输问题:当 PPP 用在异步传输时,就使用一种特殊的字符填充法;PPP 协议用在 SONET/SDH 链路时,是使用同步传输(一连串的比特连续传送)。这时 PPP 协议采用零比特填充方法来实现透明传输。
PPP 协议的工作状态:
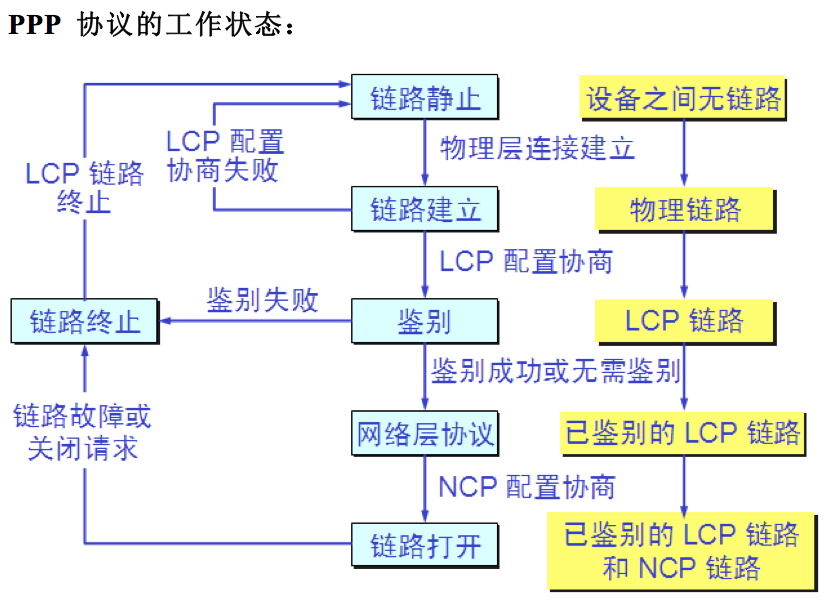
1.当用户拨号接入 ISP 时,路由器的调制解调器对拨号做出确认,并建立一条物理连接。 2.PC 机向路由器发送一系列的 LCP 分组(封装成多个 PPP 帧)。 3.这些分组及其响应选择一些 PPP 参数,和进行网络层配置,NCP 给新接入的 PC机分配一个临时的 IP 地址,使 PC 机成为因特网上的一个主机。 4.通信完毕时,NCP 释放网络层连接,收回原来分配出去的 IP 地址。接着,LCP 释放数据链路层连接。5.最后释放的是物理层的连接。
适配器的重要功能
1.进行串行/并行转换。 2.对数据进行缓存。 3.在计算机的操作系统安装设备驱动程序。 4.实现以太网协议。
为了通信的简便以太网采取了两种重要的措施: 采用较为灵活的无连接的工作方式,即不必先建立连接就可以直接发送数据。 以太网对发送的数据帧不进行编号,也不要求对方发回确认。
载波监听多点接入/碰撞检测 CSMA/CD
“多点接入”表示许多计算机以多点接入的方式连接在一根总线上。 “载波监听”是指每一个站在发送数据之前先要检测一下总线上是否有其他计算机在发送数据,如果有,则暂时不要发送数据,以免发生碰撞。 “碰撞检测”就是计算机边发送数据边检测信道上的信号电压大小。所谓“碰撞”就是发生了冲突。因此“碰撞检测”也称为“冲突检测”。 检测到碰撞后:在发生碰撞时,总线上传输的信号产生了严重的失真,无法从中恢复出有用的信息来。 每一个正在发送数据的站,一旦发现总线上出现了碰撞,就要立即停止发送,免得继续浪费网络资源,然后等待一段随机时间后再次发送。 传播时延对载波监听有影响。
重要特性:
使用 CSMA/CD 协议的以太网不能进行全双工通信而只能进行双向交替通信(半双工通信)。
每个站在发送数据之后的一小段时间内,存在着遭遇碰撞的可能性。
这种发送的不确定性使整个以太网的平均通信量远小于以太网的最高数据率。
争用期: 最先发送数据帧的站,在发送数据帧后至多经过时间 2t(两倍的端到端往返时延)就可知道发送的数据帧是否遭受了碰撞。以太网的端到端往返时延2t称为争用期,或碰撞窗口。经过争用期这段时间还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
争用期的长度 以太网取 51.2 微秒为争用期的长度。 对于 10 Mb/s 以太网,在争用期内可发送512 bit,即 64 字节。 以太网在发送数据时,若前 64 字节没有发生冲突,则后续的数据就不会发生冲突。
最短有效帧长:如果发生冲突,就一定是在发送的前 64 字节之内。 由于一检测到冲突就立即中止发送,这时已经发送出去的数据一定小于 64 字节。 以太网规定了最短有效帧长为 64 字节,凡长度小于 64 字节的帧都是由于冲突而异常中止的无效帧。
集线器的一些特点
集线器是使用电子器件来模拟实际电缆线的工作,因此整个系统仍然像一个传统的以太网那样运行。 使用集线器的以太网在逻辑上仍是一个总线网,各工作站使用的还是 CSMA/CD 协议,并共享逻辑上的总线。 集线器很像一个多接口的转发器,工作在物理层。
以太网的 MAC 层
以太网的 MAC 帧格式
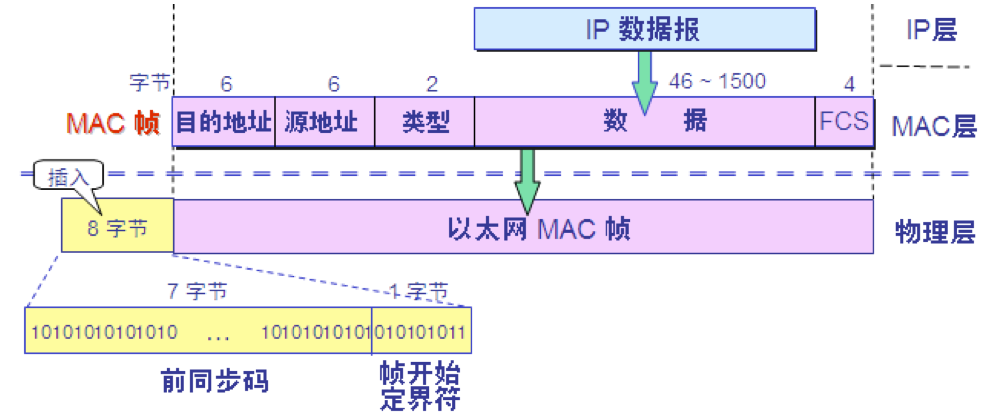
类型字段用来标志上一层使用的是什么协议,以便把收到的 MAC 帧的数据上交给上一层的这个协议。 最小长度 64 字节 18 字节的首部和尾部 = 数据字段的最小长度;当数据字段的长度小于 46 字节时, 应在数据字段的后面加入整数字节的填充字段,以保证以太网的 MAC 帧长不小于 64 字节。 为了达到比特同步,在传输媒体上实际传送的要比 MAC 帧还多 8 个字节
无效的 MAC 帧 1.数据字段的长度与长度字段的值不一致; 2.帧的长度不是整数个字节; 3.用收到的帧检验序列 FCS 查出有差错; 4.数据字段的长度不在 46 ~ 1500 字节之间。 5.有效的 MAC 帧长度为 64 ~ 1518 字节之间。 对于检查出的无效 MAC 帧就简单地丢弃。以太网不负责重传丢弃的帧。
帧间最小间隔:一个站在检测到总线开始空闲后,还要等待 9.6 s 才能再次发送数据。 这样做是为了使刚刚收到数据帧的站的接收缓存来得及清理,做好接收下一帧的准备。
用集线器扩展局域网 优点: 使原来属于不同碰撞域的局域网上的计算机能够进行跨碰撞域的通信。 扩大了局域网覆盖的地理范围。 缺点: 碰撞域增大了,但总的吞吐量并未提高。 如果不同的碰撞域使用不同的数据率,那么就不能用集线器将它们互连起来。
在数据链路层扩展局域网 在数据链路层扩展局域网是使用网桥。网桥工作在数据链路层,它根据 MAC 帧的目的地址对收到的帧进行转发。网桥具有过滤帧的功能。当网桥收到一个帧时,并不是向所有的接口转发此帧,而是先检查此帧的目的 MAC 地址,然后再确定将该帧转发到哪一个接口
使用网桥带来的好处: 1.过滤通信量。 2.扩大了物理范围。 3.提高了可靠性。 4.可互连不同物理层、不同 MAC 子层和不同速率(如10 Mb/s 和 100 Mb/s 以太网)的局域网。
使用网桥带来的缺点: 1.存储转发增加了时延。 2.在MAC 子层并没有流量控制功能。 3.具有不同 MAC 子层的网段桥接在一起时时延更大。 4.网桥只适合于用户数不太多(不超过几百个)和通信量不太大的局域网,否则有时还会因传播过多的广播信息而产生网络拥塞。这就是所谓的广播风暴。
网桥和集线器(或转发器)不同
集线器在转发帧时,不对传输媒体进行检测。 网桥在转发帧之前必须执行 CSMA/CD 算法。若在发送过程中出现碰撞,就必须停止发送和进行退避。
网桥应当按照以下自学习算法处理收到的帧和建立转发表:
1.若从 A 发出的帧从接口 x 进入了某网桥,那么从这个接口出发沿相反方向一定可把一个帧传送到 A。
2.网桥每收到一个帧,就记下其源地址和进入网桥的接口,作为转发表中的一个项目。
3.在建立转发表时是把帧首部中的源地址写在“地址”这一栏的下面。
4.在转发帧时,则是根据收到的帧首部中的目的地址来转发的。这时就把在“地址”栏下面已经记下的源地址当作目的地址,而把记下的进入接口当作转发接口。
5.网桥在转发表中登记以下三个信息:在网桥的转发表中写入的信息除了地址和接口外,还有帧进入该网桥的时间。
网桥的自学习和转发帧的步骤归纳 网桥收到一帧后先进行自学习。查找转发表中与收到帧的源地址有无相匹配的项目。如没有,就在转发表中增加一个项目(源地址、进入的接口和时间)。如有,则把原有的项目进行更新。 转发帧。查找转发表中与收到帧的目的地址有无相匹配的项目。如没有,则通过所有其他接口(但进入网桥的接口除外)按进行转发。如有,则按转发表中给出的接口进行转发。 若转发表中给出的接口就是该帧进入网桥的接口,则应丢弃这个帧(因为这时不需要经过网桥进行转发)。
透明网桥使用了生成树算法,这是为了避免产生转发的帧在网络中不断地兜圈子。
多接口网桥——以太网交换机 以太网交换机的每个接口都直接与主机相连,并且一般都工作在全双工方式。 交换机能同时连通许多对的接口,使每一对相互通信的主机都能像独占通信媒体那样,进行无碰撞地传输数据。 以太网交换机由于使用了专用的交换结构芯片,其交换速率就较高。
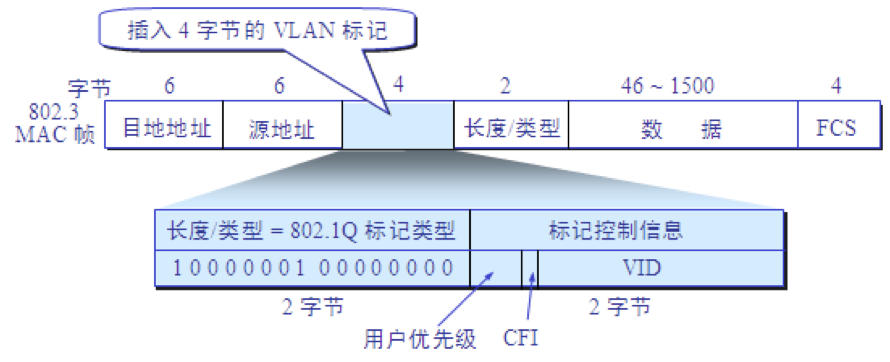
虚拟局域网 VLAN 是由一些局域网网段构成的与物理位置无关的逻辑组。 这些网段具有某些共同的需求。 每一个 VLAN 的帧都有一个明确的标识符,指明发送这个帧的工作站是属于哪一个 VLAN。 虚拟局域网其实只是局域网给用户提供的一种服务,而并不是一种新型局域网。
虚拟局域网使用的以太网帧格式
虚拟局域网协议允许在以太网的帧格式中插入一个 4 字节的标识符,称为 VLAN 标记(tag),用来指明发送该帧的工作站属于哪一个虚拟局域网。
第 4 章 网络层
网际协议IP
网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一。与 IP 协议配套使用的还有四个协议: 1.地址解析协议 ARP 2.逆地址解析协议 RARP 3.网际控制报文协议 ICMP 4.网际组管理协议 IGMP
虚拟互连网络的意义:所谓虚拟互连网络也就是逻辑互连网络,它的意思就是互连起来的各种物理网络的异构性本来是客观存在的,但是我们利用 IP 协议就可以使这些性能各异的网络从用户看起来好像是一个统一的网络。使用 IP 协议的虚拟互连网络可简称为 IP 网。使用虚拟互连网络的好处是:当互联网上的主机进行通信时,就好像在一个网络上通信一样,而看不见互连的各具体的网络异构细节。
分类的 IP 地址
常用的三种类别的 IP 地址
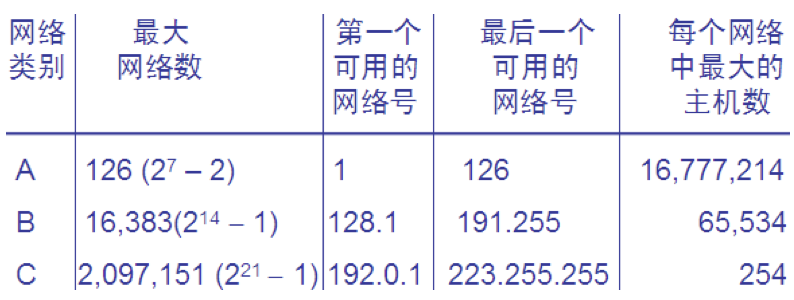
网络号为127保留作为本地软件环回测试本主机的进程之间的通信之用。目的地址为环回地址的IP数据报永远不会出现在任何网络上。
地址解析协议 ARP 和逆地址解析协议 RARP
不管网络层使用的是什么协议,在实际网络的链路上传送数据帧时,最终还是必须使用硬件地址。每一个主机都设有一个 ARP 高速缓存(ARP cache),里面有所在的局域网上的各主机和路由器的 IP 地址到硬件地址的映射表。当主机 A 欲向本局域网上的某个主机 B 发送 IP 数据报时,就先在其 ARP 高速缓存中查看有无主机 B 的 IP 地址。如有,就可查出其对应的硬件地址,再将此硬件地址写入 MAC 帧,然后通过局域网将该 MAC 帧发往此硬件地址。
为了减少网络上的通信量,主机 A 在发送其 ARP 请求分组时,就将自己的 IP 地址到硬件地址的映射写入 ARP 请求分组。
当主机 B 收到 A 的 ARP 请求分组时,就将主机 A 的这一地址映射写入主机 B 自己的 ARP 高速缓存中。这对主机 B 以后向 A 发送数据报时就更方便了。
ARP 是解决同一个局域网上的主机或路由器的 IP 地址和硬件地址的映射问题。
从IP地址到硬件地址的解析是自动进行的,主机的用户对这种地址解析过程是不知道的
逆地址解析协议 RARP 使只知道自己硬件地址的主机能够知道其 IP 地址。这种主机往往是无盘工作站。 因此 RARP协议目前已很少使用。
IP 数据报的格式
一个 IP 数据报由首部和数据两部分组成。
首部的前一部分是固定长度,共 20 字节,是所有 IP 数据报必须具有的。
在首部的固定部分的后面是一些可选字段,其长度是可变的。
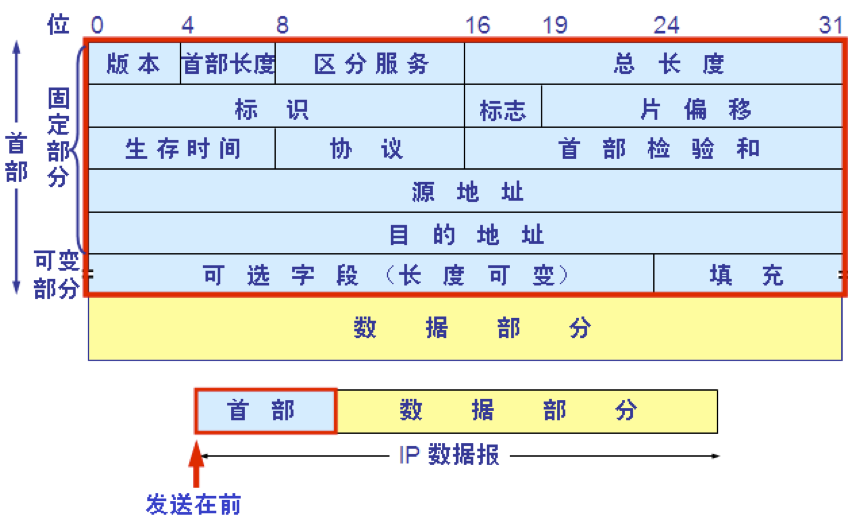
1.版本——占 4 位,指 IP 协议的版本目前的 IP 协议版本号为 4 (即 IPv4)
2.首部长度——占 4 位,可表示的最大数值是 15 个单位(一个单位为 4 字节)因此 IP 的首部长度的最大值是 60 字节。
3.区分服务——占 8 位,用来获得更好的服务在旧标准中叫做服务类型,但实际上一直未被使用过。
4.总长度——占 16 位,指首部和数据之和的长度,单位为字节,因此数据报的最大长度为 65535 字节。总长度必须不超过最大传送单元 MTU。
5.标识(identification) 占 16 位,它是一个计数器,用来产生数据报的标识。
6.标志(flag) 占 3 位,目前只有前两位有意义。标志字段的最低位是 MF (More Fragment)。
MF 1 表示后面“还有分片”。MF 0 表示最后一个分片。标志字段中间的一位是 DF (Don’t Fragment) 。
只有当 DF 0 时才允许分片。
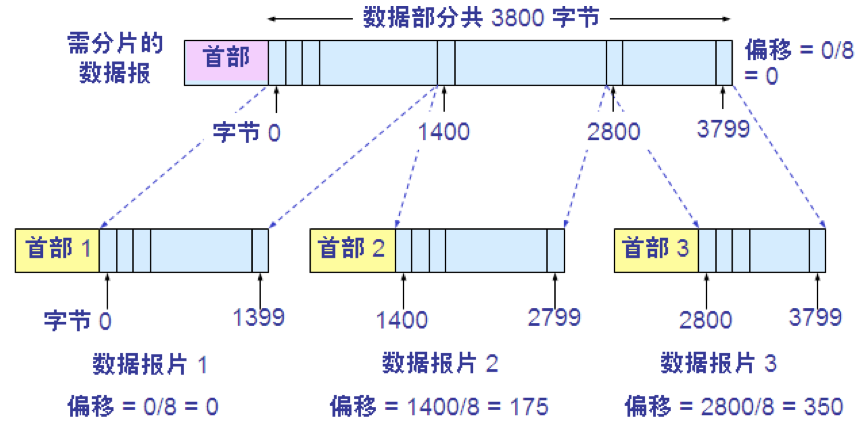
7.片偏移(12 位)指出:较长的分组在分片后某片在原分组中的相对位置。片偏移以 8 个字节为偏移单位。
IP 数据报分片举例:
8.生存时间(8 位)记为 TTL (Time To Live)数据报在网络中可通过的路由器数的最大值。
9.协议(8 位)字段指出此数据报携带的数据使用何种协议以便目的主机的 IP 层将数据部分上交给哪个处理过程
10.首部检验和(16 位)字段只检验数据报的首部不检验数据部分。
11.源地址和目的地址都各占 4 字节
12.IP 数据报首部的可变部分:
IP 首部的可变部分就是一个选项字段,用来支持排错、测量以及安全等措施,内容很丰富。
选项字段的长度可变,从 1 个字节到 40 个字节不等,取决于所选择的项目。
增加首部的可变部分是为了增加 IP 数据报的功能,但这同时也使得 IP 数据报的首部长度成为可变的。这就增加了每一个路由器处理数据报的开销。
实际上这些选项很少被使用。
IP 层转发分组的流程
IP 数据报的首部中没有地方可以用来指明“下一跳路由器的 IP 地址”。当路由器收到待转发的数据报,不是将下一跳路由器的 IP 地址填入 IP 数据报,而是送交下层的网络接口软件。网络接口软件使用 ARP 负责将下一跳路由器的 IP 地址转换成硬件地址,并将此硬件地址放在链路层的 MAC 帧的首部,然后根据这个硬件地址找到下一跳路由器。
分组转发算法 (1) 从数据报的首部提取目的主机的 IP 地址 D, 得出目的网络地址为 N。 (2) 若网络 N 与此路由器直接相连,则把数据报直接交付目的主机 D;否则是间接交付,执行(3)。 (3) 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行(4)。 (4) 若路由表中有到达网络 N 的路由,则把数据报传送给路由表指明的下一跳路由器;否则,执行(5)。 (5) 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则,执行(6)。 (6) 报告转发分组出错。
划分子网和构造超网
划分子网纯属一个单位内部的事情。单位对外仍然表现为没有划分子网的网络。凡是从其他网络发送给本单位某个主机的 IP 数据报,仍然是根据 IP 数据报的目的网络号 net-id,先找到连接在本单位网络上的路由器。然后此路由器在收到 IP 数据报后,再按目的网络号 net-id 和子网号 subnet-id 找到目的子网。
子网掩码是一个重要属性 子网掩码是一个网络或一个子网的重要属性。 路由器在和相邻路由器交换路由信息时,必须把自己所在网络(或子网)的子网掩码告诉相邻路由器。 路由器的路由表中的每一个项目,除了要给出目的网络地址外,还必须同时给出该网络的子网掩码。 若一个路由器连接在两个子网上就拥有两个网络地址和两个子网掩码。 不同的子网掩码可能得出相同的网络地址。但不同的掩码的效果是不同的。
在划分子网的情况下路由器转发分组的算法 (1) 从收到的分组的首部提取目的 IP 地址 D。 (2) 先用各网络的子网掩码和 D 逐位相“与”,看是否和相应的网络地址匹配。若匹配,则将分组直接交付。否则就是间接交付,执行(3)。 (3) 若路由表中有目的地址为 D 的特定主机路由,则将分组传送给指明的下一跳路由器;否则,执行(4)。 (4) 对路由表中的每一行的子网掩码和 D 逐位相“与”,若其结果与该行的目的网络地址匹配,则将分组传送给该行指明的下一跳路由器;否则,执行(5)。 (5) 若路由表中有一个默认路由,则将分组传送给路由表中所指明的默认路由器;否则,执行(6)。 (6) 报告转发分组出错。
无分类编址 CIDR
1.CIDR 最主要的特点 2.CIDR 消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,因而可以更加有效地分配 IPv4 的3.地址空间。 CIDR使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号。 IP 地址从三级编址(使用子网掩码)又回到了两级编址。
CIDR 还使用“斜线记法”(slash notation),它又称为CIDR记法,即在 IP 地址面加上一个斜线“/”,然后写上网络前缀所占的位数(这个数值对应于三级编址中子网掩码中 1 的个数)。 CIDR 把网络前缀都相同的连续的 IP 地址组成“CIDR 地址块”。
路由聚合 一个 CIDR 地址块可以表示很多地址,这种地址的聚合常称为路由聚合,它使得路由表中的一个项目可以表示很多个(例如上千个)原来传统分类地址的路由。 路由聚合也称为构成超网(supernetting)。 CIDR 虽然不使用子网了,但仍然使用“掩码”这一名词(但不叫子网掩码)。 对于 /20 地址块,它的掩码是 20 个连续的 1。 斜线记法中的数字就是掩码中1的个数。
最长前缀匹配 使用 CIDR 时,路由表中的每个项目由“网络前缀”和“下一跳地址”组成。在查找路由表时可能会得到不止一个匹配结果。 应当从匹配结果中选择具有最长网络前缀的路由:最长前缀匹配(longest-prefix matching)。 网络前缀越长,其地址块就越小,因而路由就越具体(more specific) 。 最长前缀匹配又称为最长匹配或最佳匹配。
网际控制报文协议 ICMP
ICMP 报文的格式
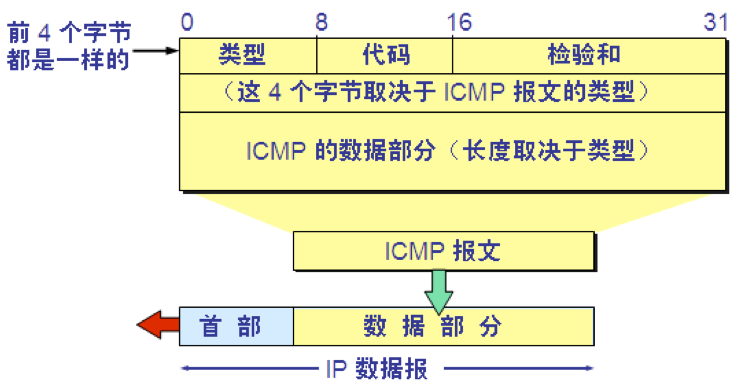
ICMP 报文的种类有两种,即 ICMP 差错报告报文和 ICMP 询问报文。
ICMP 差错报告报文共有 5 种:
终点不可达
源点抑制(Source quench)
时间超过
参数问题
改变路由(重定向)(Redirect)
不应发送 ICMP 差错报告报文的几种情况 1.对 ICMP 差错报告报文不再发送 ICMP 差错报告报文。 2.对第一个分片的数据报片的所有后续数据报片都不发送 ICMP 差错报告报文。 3.对具有多播地址的数据报都不发送 ICMP 差错报告报文。 4.对具有特殊地址(如127.0.0.0 或 0.0.0.0)的数据报不发送 ICMP 差错报告报文。
ICMP 询问报文有两种 回送请求和回答报文 时间戳请求和回答报文
PING PING 用来测试两个主机之间的连通性。 PING 使用了 ICMP 回送请求与回送回答报文。 PING 是应用层直接使用网络层 ICMP 的例子,它没有通过运输层的 TCP 或UDP。
因特网的路由选择协议
因特网有两大类路由选择协议
内部网关协议 IGP (Interior Gateway Protocol) 即在一个自治系统内部使用的路由选择协议。目前这类路由选择协议使用得最多,如 RIP 和 OSPF 协议。
外部网关协议EGP (External Gateway Protocol) 若源站和目的站处在不同的自治系统中,当数据报传到一个自治系统的边界时,就需要使用一种协议将路由选择信息传递到另一个自治系统中。这样的协议就是外部网关协议 EGP。在外部网关协议中目前使用最多的是 BGP-4。
内部网关协议 RIP
RIP 是一种分布式的基于距离向量的路由选择协议。
RIP 协议要求网络中的每一个路由器都要维护从它自己到其他每一个目的网络的距离记录。
“距离”的定义
从一路由器到直接连接的网络的距离定义为 1。
从一个路由器到非直接连接的网络的距离定义为所经过的路由器数加 1。
RIP 协议中的“距离”也称为“跳数”(hop count),因为每经过一个路由器,跳数就加 1。
这里的“距离”实际上指的是“最短距离”,
RIP 认为一个好的路由就是它通过的路由器的数目少,即“距离短”。
RIP 允许一条路径最多只能包含 15 个路由器。
“距离”的最大值为16 时即相当于不可达。可见 RIP 只适用于小型互联网。
RIP 不能在两个网络之间同时使用多条路由。RIP 选择一个具有最少路由器的路由(即最短路由),哪怕还存在另一条高速(低时延)但路由器较多的路由。
RIP 协议的三个要点 1.仅和相邻路由器交换信息。 2.交换的信息是当前本路由器所知道的全部信息,即自己的路由表。 3.按固定的时间间隔交换路由信息,例如,每隔 30 秒。
距离向量算法 收到相邻路由器(其地址为 X)的一个 RIP 报文: (1) 先修改此 RIP 报文中的所有项目:把“下一跳”字段中的地址都改为 X,并把所有的“距离”字段的值加 1。 (2) 对修改后的 RIP 报文中的每一个项目,重复以下步骤: 若项目中的目的网络不在路由表中,则把该项目加到路由表中。 否则若下一跳字段给出的路由器地址是同样的,则把收到的项 目 替换原路由表中的项目。 否则若收到项目中的距离小于路由表中的距离,则进行更新, 否则,什么也不做。 (3) 若 3 分钟还没有收到相邻路由器的更新路由表,则把此相邻路由器记为不可达路由器,即将距离置为16(距离为16表示不可达)。 (4) 返回。
RIP2 协议的报文格式
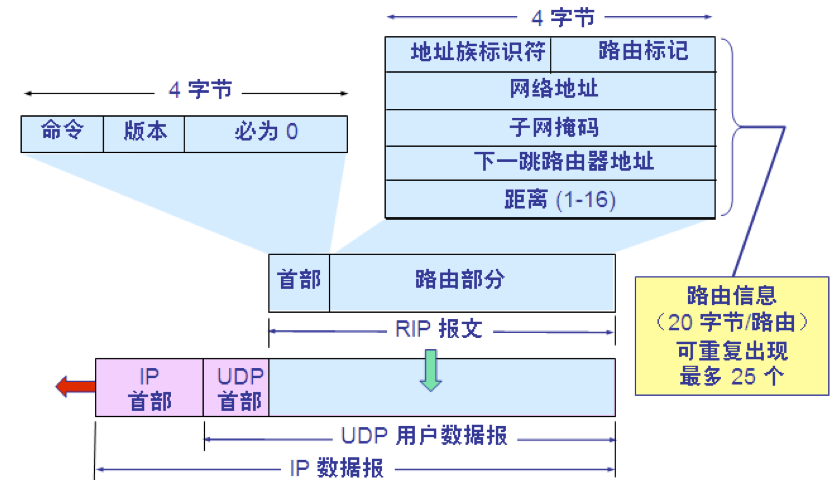
RIP2 报文中的路由部分由若干个路由信息组成。每个路由信息需要用 20 个字节。地址族标识符(又称为地址类别)字段用来标志所使用的地址协议。 路由标记填入自治系统的号码,这是考虑使RIP 有可能收到本自治系统以外的路由选择信息。再后面指出某个网络地址、该网络的子网掩码、下一跳路由器地址以及到此网络的距离。
RIP 协议的优缺点
RIP 存在的一个问题是当网络出现故障时,要经过比较长的时间才能将此信息传送到所有的路由器。(好消息传播得快,而坏消息传播得慢)
RIP 协议最大的优点就是实现简单,开销较小。
RIP 限制了网络的规模,它能使用的最大距离为 15(16 表示不可达)。
路由器之间交换的路由信息是路由器中的完整路由表,因而随着网络规模的扩大,开销也就增加。
内部网关协议 OSPF(开放最短路径优先)
OSPF 协议的基本特点 “开放”表明 OSPF 协议不是受某一家厂商控制,而是公开发表的。 “最短路径优先”是因为使用了 Dijkstra 提出的最短路径算法SPF OSPF 只是一个协议的名字,它并不表示其他的路由选择协议不是“最短路径优先”。 是分布式的链路状态协议。
三个要点
向本自治系统中所有路由器发送信息,这里使用的方法是洪泛法。
发送的信息就是与本路由器相邻的所有路由器的链路状态,但这只是路由器所知道的部分信息。
“链路状态”就是说明本路由器都和哪些路由器相邻,以及该链路的“度量”(metric)。
只有当链路状态发生变化时,路由器才用洪泛法向所有路由器发送此信息。
链路状态数据库
由于各路由器之间频繁地交换链路状态信息,因此所有的路由器最终都能建立一个链路状态数据库。
这个数据库实际上就是全网的拓扑结构图,它在全网范围内是一致的(这称为链路状态数据库的同步)。
OSPF 的链路状态数据库能较快地进行更新,使各个路由器能及时更新其路由表。OSPF 的更新过程收敛得快是其重要优点。
OSPF 直接用 IP 数据报传送
OSPF 不用 UDP 而是直接用 IP 数据报传送。
OSPF 构成的数据报很短。这样做可减少路由信息的通信量。
数据报很短的另一好处是可以不必将长的数据报分片传送。分片传送的数据报只要丢失一个,就无法组装成原来的数据报,而整个数据报就必须重传。
OSPF 的其他特点 1.OSPF 对不同的链路可根据 IP 分组的不同服务类型 TOS 而设置成不同的代价。因此,OSPF 对于不同类型的业务可计算出不同的路由。 2.如果到同一个目的网络有多条相同代价的路径,那么可以将通信量分配给这几条路径。这叫作多路径间的负载平衡。 3.所有在 OSPF 路由器之间交换的分组都具有鉴别的功能。 4.支持可变长度的子网划分和无分类编址 CIDR。 5.每一个链路状态都带上一个 32 位的序号,序号越大状态就越新。
OSPF 分组
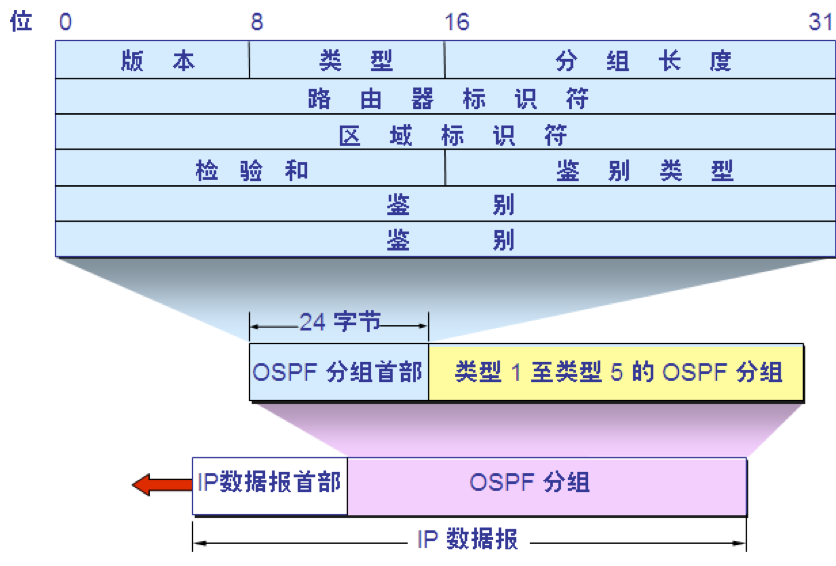
OSPF 的五种分组类型 类型1,问候(Hello)分组。 类型2,数据库描述(Database Description)分组。 类型3,链路状态请求(Link State Request)分组。 类型4,链路状态更新(Link State Update)分组,用洪泛法对全网更新链路状态。 类型5,链路状态确认(Link State Acknowledgment)分组。
OSPF 的其他特点 1.OSPF 还规定每隔一段时间,如 30 分钟,要刷新一次数据库中的链路状态。 2.由于一个路由器的链路状态只涉及到与相邻路由器的连通状态,因而与整个互联网的规模并无直接关系。因此当互联网规模很大时,OSPF 协议要比距离向量协议 RIP 好得多。 3.OSPF 没有“坏消息传播得慢”的问题,据统计,其响应网络变化的时间小于 100 ms。
外部网关协议 BGP
边界网关协议 BGP 只能是力求寻找一条能够到达目的网络且比较好的路由(不能兜圈子),而并非要寻找一条最佳路由。BGP采用了路径向量路由选择协议。 每一个自治系统的管理员要选择至少一个路由器作为该自治系统的“ BGP 发言人” 。使用 TCP 连接交换路由信息的两个 BGP 发言人,彼此成为对方的邻站或对等站。
BGP 协议的特点 1.BGP 协议交换路由信息的结点数量级是自治系统数的量级,这要比这些自治系统中的网络数少很多。 2.每一个自治系统中 BGP 发言人(或边界路由器)的数目是很少的。这样就使得自治系统之间的路由选择不致过分复杂。 3.BGP 支持 CIDR,因此 BGP 的路由表也就应当包括目的网络前缀、下一跳路由器,以及到达该目的网络所要经过的各个自治系统序列。 4.在BGP 刚刚运行时,BGP 的邻站是交换整个的 BGP 路由表。但以后只需要在发生变化时更新有变化的部分。这样做对节省网络带宽和减少路由器的处理开销方面都有好处。
路由器是一种具有多个输入端口和多个输出端口的专用计算机,其任务是转发分组。整个路由器的结构可分为两大部分:路由选择部分和分组转发部分。 路由选择部分也叫做控制部分。 分组转发部分由三部分组成:交换结构、输入端口组、输出端口组。 交换结构本身就是一种网络,但这种网络完全包含在路由器之中,因此可以看做是“在路由器中的网络”。 三种常用的交换方法:(1)通过存储器;(2)通过总线;(3)通过互联网络(纵横交换结构);
“转发”和“路由选择”的区别 “转发”(forwarding)就是路由器根据转发表将用户的 IP 数据报从合适的端口转发出去。 “路由选择”(routing)则是按照分布式算法,根据从各相邻路由器得到的关于网络拓扑的变化情况,动态地改变所选择的路由。 路由表是根据路由选择算法得出的。而转发表是从路由表得出的。 路由表总是由软件实现的,但转发表则甚至可用特殊的硬件来实现。
IP 多播的一些特点
(1) 多播使用组地址—— IP 使用 D 类地址支持多播。多播地址只能用于目的地址,而不能用于源地址。
(2) 永久组地址——由因特网号码指派管理局 IANA 负责指派。
(3) 动态的组成员
(4) 使用硬件进行多播,多播IP地址与以太网硬件地址的映射关系不是唯一的,所以收到多播数据报的主机还要在IP层利用软件进行过滤。
IP多播需要两种为了使路由器知道多播组成员的信息,需要利用网际组管理协议 IGMP (Internet Group Management Protocol)。 连接在局域网上的多播路由器还必须和因特网上的其他多播路由器协同工作,以便把多播数据报用最小代价传送给所有的组成员。这就需要使用多播路由选择协议。
IGMP 的本地使用范围 IGMP 并非在因特网范围内对所有多播组成员进行管理的协议。 IGMP 不知道 IP 多播组包含的成员数,也不知道这些成员都分布在哪些网络上。 IGMP 协议是让连接在本地局域网上的多播路由器知道本局域网上是否有主机(严格讲,是主机上的某个进程)参加或退出了某个多播组。
多播路由选择协议比单播路由选择协议复杂得多 1.多播转发必须动态地适应多播组成员的变化(这时网络拓扑并未发生变化)。请注意,单播路由选择通常是在网络拓扑发生变化时才需要更新路由。 2.多播路由器在转发多播数据报时,不能仅仅根据多播数据报中的目的地址,而是还要考虑这个多播数据报从什么地方来和要到什么地方去。 3.多播数据报可以由没有加入多播组的主机发出,也可以通过没有组成员接入的网络。 4.目前还没有在整个因特网范围使用的多播路由选择协议。
已有的多播路由选择协议常采用以下三种方法: 1.洪泛与剪除法。这种方法适合于较小的多播组,而所有的组成员接入的局域网也是相邻接的。为避免兜圈子采用了反向路径广播RPB的策略 2.隧道技术。适合于多播组的位置在地理上很分散的情况。比如会有不支持多播的路由器存在。 3.基于核心的发现技术。这种方法对于多播组的大小在较大范围内变化时都适用。
虚拟专用网 VPN
解决的是分布在不同地点的专用网需要进行通信的问题。 专用地址 10.0.0.0 到 10.255.255.255 172.16.0.0 到 172.31.255.255 192.168.0.0 到 192.168.255.255 这些地址只能用于一个机构的内部通信,而不能用于和因特网上的主机通信。 专用地址只能用作本地地址而不能用作全球地址。在因特网中的所有路由器对目的地址是专用地址的数据报一律不进行转发。 用隧道技术实现虚拟专用网
网络地址转换 NAT
解决的是已分配了本地IP地址的主机想和因特网上的主机通信的问题。 需要在专用网连接到因特网的路由器上安装 NAT 软件。装有 NAT 软件的路由器叫做 NAT路由器,它至少有一个有效的外部全球地址 IPG。显然,通过NAT路由器的通信必须由专用网内的主机发起。当NAT路由器具有n个全球IP地址时,专用网内最多可以同时有n个主机接入到因特网。 使用端口号的NAT也叫做网络地址与端口号转换NAPT。
第 5 章 运输层
运输层向它上面的应用层提供通信服务,它属于面向通信部分的最高层,同时也是用户功能中的最低层。运输层为相互通信的应用进程提供了逻辑通信(网络层提供的是主机之间的逻辑通信)。
当运输层采用面向连接的 TCP 协议时,尽管下面的网络是不可靠的(只提供尽最大努力服务),但这种逻辑通信信道就相当于一条全双工的可靠信道。
当运输层采用无连接的 UDP 协议时,这种逻辑通信信道是一条不可靠信道。
TCP 的端口 端口用一个 16 位端口号进行标志。 端口号只具有本地意义,即端口号只是为了标志本计算机应用层中的各进程。
三类端口 1.熟知端口,数值一般为 0~1023。 2.登记端口号,数值为1024~49151,为没有熟知端口号的应用程序使用的。使用这个范围的端口号必须在 IANA 登记,以防止重复。 3.客户端口号或短暂端口号,数值为49152~65535,留给客户进程选择暂时使用。当服务器进程收到客户进程的报文时,就知道了客户进程所使用的动态端口号。通信结束后,这个端口号可供其他客户进程以后使用。
用户数据报协议 UDP UDP 只在 IP 的数据报服务之上增加了很少一点的功能,即端口的功能和差错检测的功能。虽然 UDP 用户数据报只能提供不可靠的交付,但 UDP 在某些方面有其特殊的优点。
UDP 的主要特点
1.UDP 是无连接的,即发送数据之前不需要建立连接。
2.UDP 使用尽最大努力交付,即不保证可靠交付,同时也不使用拥塞控制。
3.UDP 是面向报文的。UDP 没有拥塞控制,很适合多媒体通信的要求。
4.UDP 支持一对一、一对多、多对一和多对多的交互通信。
5.UDP 的首部开销小,只有 8 个字节。
UDP 是面向报文的 发送方 UDP 对应用程序交下来的报文,在添加首部后就向下交付 IP 层。UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。 应用层交给 UDP 多长的报文,UDP 就照样发送,即一次发送一个报文。 接收方 UDP 对 IP 层交上来的 UDP 用户数据报,在去除首部后就原封不动地交付上层的应用进程,一次交付一个完整的报文。 应用程序必须选择合适大小的报文。
UDP 的首部格式
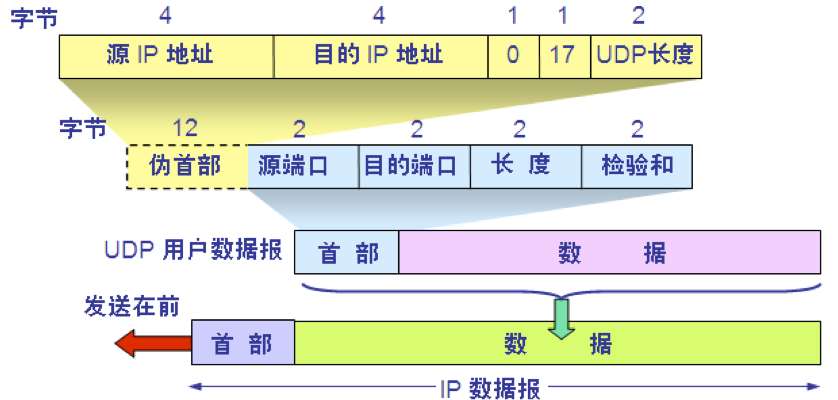
在计算检验和时,临时把“伪首部”和 UDP 用户数据报连接在一起。伪首部仅仅是为了计算检验和。
传输控制协议 TCP
TCP 最主要的特点
1.TCP 是面向连接的运输层协议。
2.每一条 TCP 连接只能有两个端点(endpoint),每一条 TCP 连接只能是点对点的(一对一)。
3.TCP 提供可靠交付的服务。
4.TCP 提供全双工通信。
5.面向字节流。
应当注意
1.TCP 连接是一条虚连接而不是一条真正的物理连接。
2.TCP 对应用进程一次把多长的报文发送到TCP 的缓存中是不关心的。
3.TCP 根据对方给出的窗口值和当前网络拥塞的程度来决定一个报文段应包含多少个字节(UDP 发送的报文长度是应用进程给出的)。
4.TCP 可把太长的数据块划分短一些再传送。TCP 也可等待积累有足够多的字节后再构成报文段发送出去。
TCP 的连接
1.TCP 把连接作为最基本的抽象。
2.每一条 TCP 连接有两个端点。
3.TCP 连接的端点不是主机,不是主机的IP 地址,不是应用进程,也不是运输层的协议端口。TCP 连接的端点叫做套接字(socket)或插口。端口号拼接到(contatenated with) IP 地址即构成了套接字。
4.每一条 TCP 连接唯一地被通信两端的两个端点(即两个套接字)所确定。
TCP 可靠通信的具体实现
1.TCP 连接的每一端都必须设有两个窗口——一个发送窗口和一个接收窗口。
2.TCP 的可靠传输机制用字节的序号进行控制。TCP 所有的确认都是基于序号而不是基于报文段。
3.TCP 两端的四个窗口经常处于动态变化之中。
4.TCP连接的往返时间 RTT 也不是固定不变的。需要使用特定的算法估算较为合理的重传时间。
TCP 报文段的首部格式
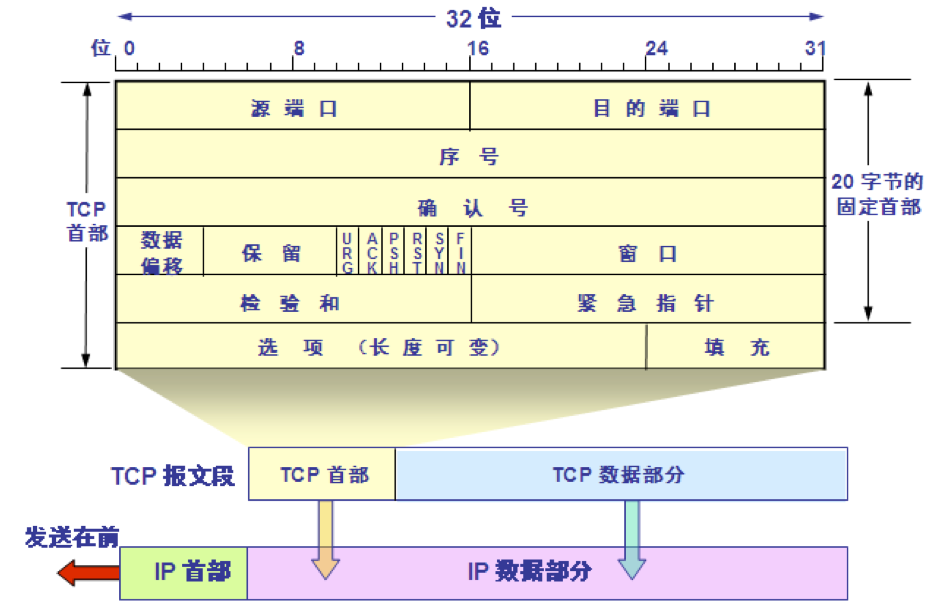
1.源端口和目的端口字段——各占 2 字节。端口是运输层与应用层的服务接口。运输层的复用和分用功能都要通过端口才能实现。
2.序号字段——占 4 字节。TCP 连接中传送的数据流中的每一个字节都编上一个序号。序号字段的值则指的是本报文段所发送的数据的第一个字节的序号。
3.确认号字段——占 4 字节,是期望收到对方的下一个报文段的数据的第一个字节的序号。
4.数据偏移(即首部长度)——占 4 位,它指出 TCP 报文段的数据起始处距离 TCP 报文段的起始处有多远。“数据偏移”的单位是 32 位字(以 4 字节为计算单位)。
5.保留字段——占 6 位,保留为今后使用,但目前应置为 0。
6.紧急 URG —— 当 URG 1 时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)。
7.确认 ACK —— 只有当 ACK 1 时确认号字段才有效。当 ACK 0 时,确认号无效。
8.推送 PSH (PuSH) —— 接收 TCP 收到 PSH = 1 的报文段,就尽快地交付接收应用进程,而不再等到整个缓存都填满了后再向上交付。
9.复位 RST (ReSeT) —— 当 RST 1 时,表明 TCP 连接中出现严重差错(如由于主机崩溃或其他原因),必须释放连接,然后再重新建立运输连接。
10.同步 SYN —— 同步 SYN = 1 表示这是一个连接请求或连接接受报文。
11.终止 FIN (FINis) —— 用来释放一个连接。FIN 1 表明此报文段的发送端的数据已发送完毕,并要求释放运输连接。
12.窗口字段 —— 占 2 字节,用来让对方设置发送窗口的依据,单位为字节。
13.检验和 —— 占 2 字节。检验和字段检验的范围包括首部和数据这两部分。在计算检验和时,要在 TCP 报文段的前面加上 12 字节的伪首部。
14.紧急指针字段 —— 占 16 位,指出在本报文段中紧急数据共有多少个字节(紧急数据放在本报文段数据的最前面)。
15.选项字段 —— 长度可变。TCP 最初只规定了一种选项,即最大报文段长度 MSS。MSS 告诉对方 TCP:“我的缓存所能接收的报文段的数据字段的最大长度是 MSS 个字节。”
16.填充字段 —— 这是为了使整个首部长度是 4 字节的整数倍。
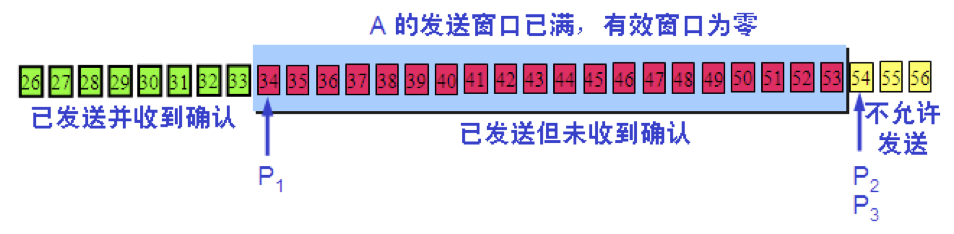
以字节为单位的滑动窗口
根据 B 给出的窗口值
【1】A 构造出自己的发送窗口
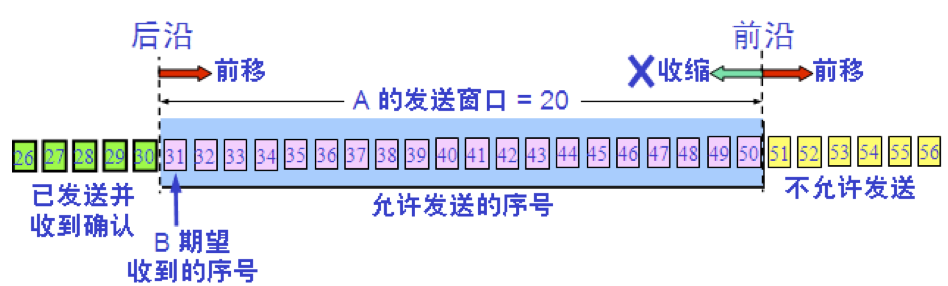
【2】A 发送了 11 个字节的数据
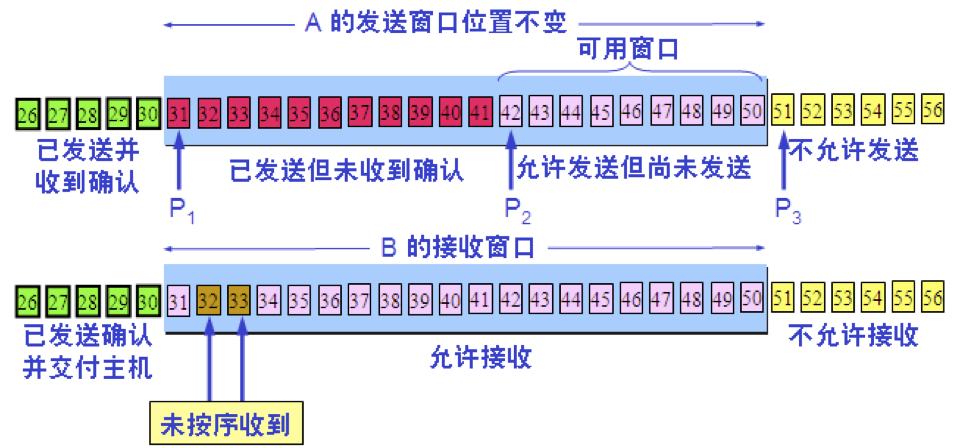
P3 – P1 = A 的发送窗口(又称为通知窗口)
P2 – P1 = 已发送但尚未收到确认的字节数
P3 – P2 = 允许发送但尚未发送的字节数(又称为可用窗口)
【3】A 收到新的确认号,发送窗口向前滑动
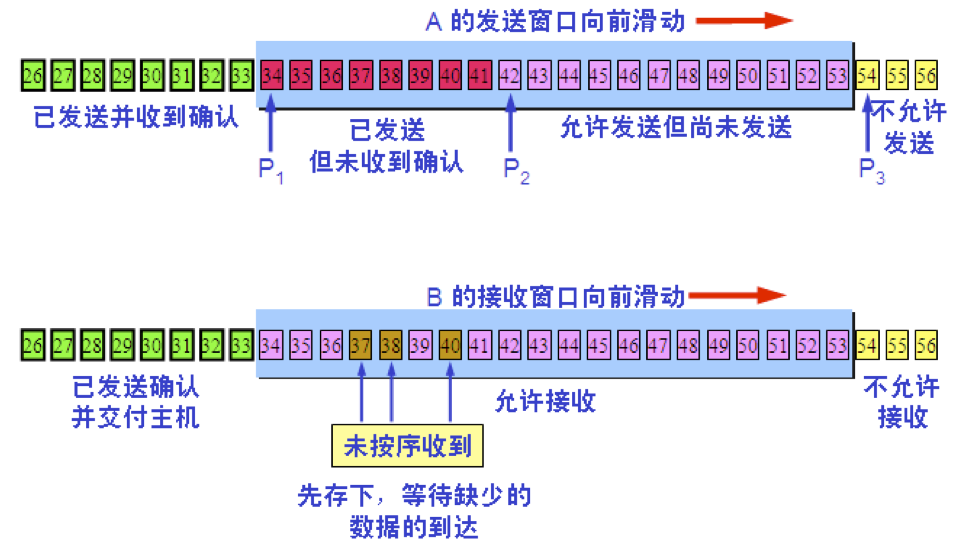
【4】A 的发送窗口内的序号都已用完,但还没有再收到确认,必须停止发送。
发送缓存与接收缓存的作用
发送缓存用来暂时存放: 1.发送应用程序传送给发送方 TCP 准备发送的数据; 2.TCP 已发送出但尚未收到确认的数据。 接收缓存用来暂时存放: 1.按序到达的、但尚未被接收应用程序读取的数据; 2.不按序到达的数据。
需要强调三点 1.A 的发送窗口并不总是和 B 的接收窗口一样大(因为有一定的时间滞后)。 2.TCP 标准没有规定对不按序到达的数据应如何处理。通常是先临时存放在接收窗口中,等到字节流中所缺少的字节收到后,再按序交付上层的应用进程。 3.TCP 要求接收方必须有累积确认的功能,这样可以减小传输开销。
TCP 的流量控制
流量控制(flow control)就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。利用滑动窗口机制可以很方便地在 TCP 连接上实现流量控制。
TCP的拥塞控制
若对网络中某资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏——产生拥塞(congestion)。
拥塞控制与流量控制的关系
1.拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
2.拥塞控制是一个全局性的过程,涉及到所有的主机、所有的路由器,以及与降低网络传输性能有关的所有因素。
3.流量控制往往指在给定的发送端和接收端之间的点对点通信量的控制。
4.流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
几种拥塞控制方法
慢开始和拥塞避免
发送方维持一个叫做拥塞窗口 cwnd (congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞窗口。如再考虑到接收方的接收能力,则发送窗口还可能小于拥塞窗口。
发送方控制拥塞窗口的原则是:只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
慢开始算法的原理 1.在主机刚刚开始发送报文段时可先设置拥塞窗口 cwnd = 1,即设置为一个最大报文段 MSS 的数值。 2.在每收到一个对新的报文段的确认后,将拥塞窗口加 1,即增加一个 MSS 的数值。 3.用这样的方法逐步增大发送端的拥塞窗口 cwnd,可以使分组注入到网络的速率更加合理。
传输轮次(transmission round) 使用慢开始算法后,每经过一个传输轮次,拥塞窗口 cwnd 就加倍。 一个传输轮次所经历的时间其实就是往返时间 RTT。 “传输轮次”更加强调:把拥塞窗口 cwnd 所允许发送的报文段都连续发送出去,并收到了对已发送的最后一个字节的确认。
设置慢开始门限状态变量ssthresh 慢开始门限 ssthresh 的用法如下: 当 cwnd < ssthresh 时,使用慢开始算法。 当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。 当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞避免算法。 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢地增大,即每经过一个往返时间 RTT 就把发送方的拥塞窗口 cwnd 加 1,而不是加倍,使拥塞窗口 cwnd 按线性规律缓慢增长。
当网络出现拥塞时 无论在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有按时收到确认),就要把慢开始门限 ssthresh 设置为出现拥塞时的发送方窗口值的一半(但不能小于2)。 然后把拥塞窗口 cwnd 重新设置为 1,执行慢开始算法。 这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
慢开始和拥塞避免算法的实现举例
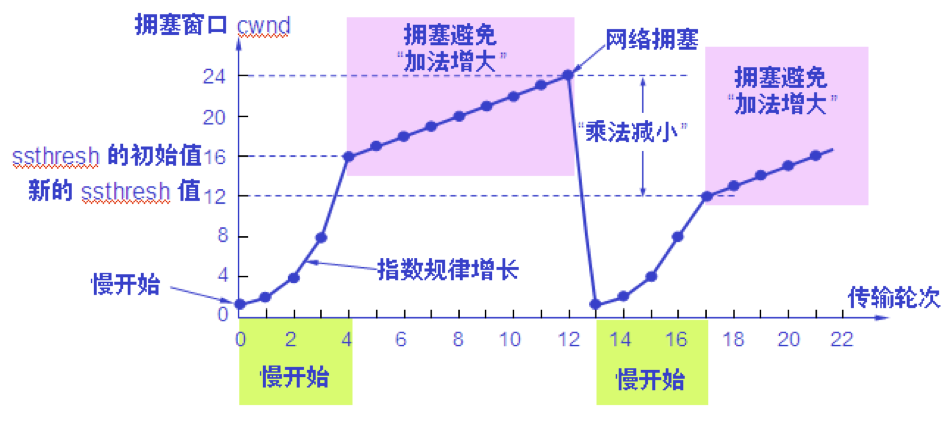
乘法减小(multiplicative decrease) “乘法减小“是指不论在慢开始阶段还是拥塞避免阶段,只要出现一次超时(即出现一次网络拥塞),就把慢开始门限值 ssthresh 设置为当前的拥塞窗口值乘以 0.5。 当网络频繁出现拥塞时,ssthresh 值就下降得很快,以大大减少注入到网络中的分组数。
加法增大(additive increase) “加法增大”是指执行拥塞避免算法后,在收到对所有报文段的确认后(即经过一个往返时间),就把拥塞窗口 cwnd增加一个 MSS 大小,使拥塞窗口缓慢增大,以防止网络过早出现拥塞。
必须强调指出 “拥塞避免”并非指完全能够避免了拥塞。利用以上的措施要完全避免网络拥塞还是不可能的。 “拥塞避免”是说在拥塞避免阶段把拥塞窗口控制为按线性规律增长,使网络比较不容易出现拥塞。
快重传和快恢复 快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认。这样做可以让发送方及早知道有报文段没有到达接收方。 发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段。 不难看出,快重传并非取消重传计时器,而是在某些情况下可更早地重传丢失的报文段。
快恢复算法 (1) 当发送端收到连续三个重复的确认时,就执行“乘法减小”算法,把慢开始门限 ssthresh 减半。但接下去不执行慢开始算法。 (2)由于发送方现在认为网络很可能没有发生拥塞,因此现在不执行慢开始算法,即拥塞窗口 cwnd 现在不设置为 1,而是设置为慢开始门限 ssthresh 减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
从连续收到三个重复的确认转入拥塞避免
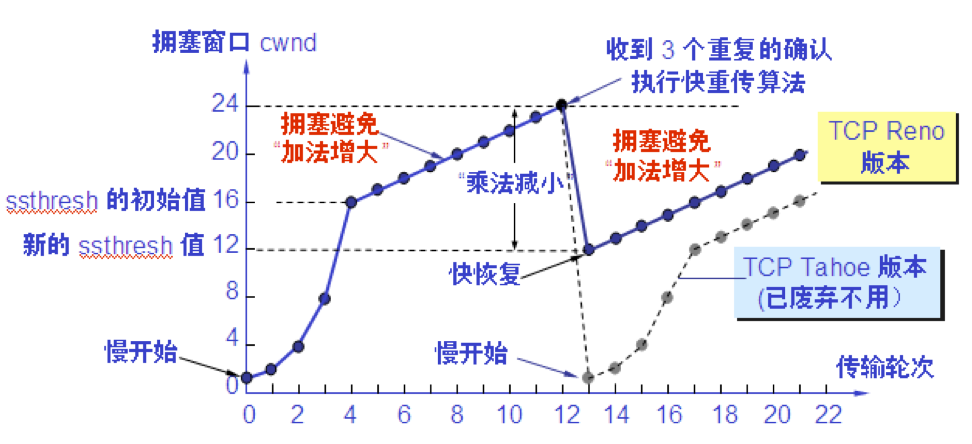
发送方的发送窗口的上限值应当取为接收方窗口 rwnd 和拥塞窗口 cwnd 这两个变量中较小的一个。
随机早期检测 RED 使路由器的队列维持两个参数,即队列长度最小门限 THmin 和最大门限 THmax。 RED 对每一个到达的数据报都先计算平均队列长度 LAV。 若平均队列长度小于最小门限 THmin,则将新到达的数据报放入队列进行排队。 若平均队列长度超过最大门限 THmax,则将新到达的数据报丢弃。 若平均队列长度在最小门限 THmin 和最大门限THmax 之间,则按照某一概率 p 将新到达的数据报丢弃。
TCP 的运输连接管理
运输连接就有三个阶段,即:连接建立、数据传送和连接释放。运输连接的管理就是使运输连接的建立和释放都能正常地进行。
TCP 的连接建立:用三次握手建立 TCP 连接
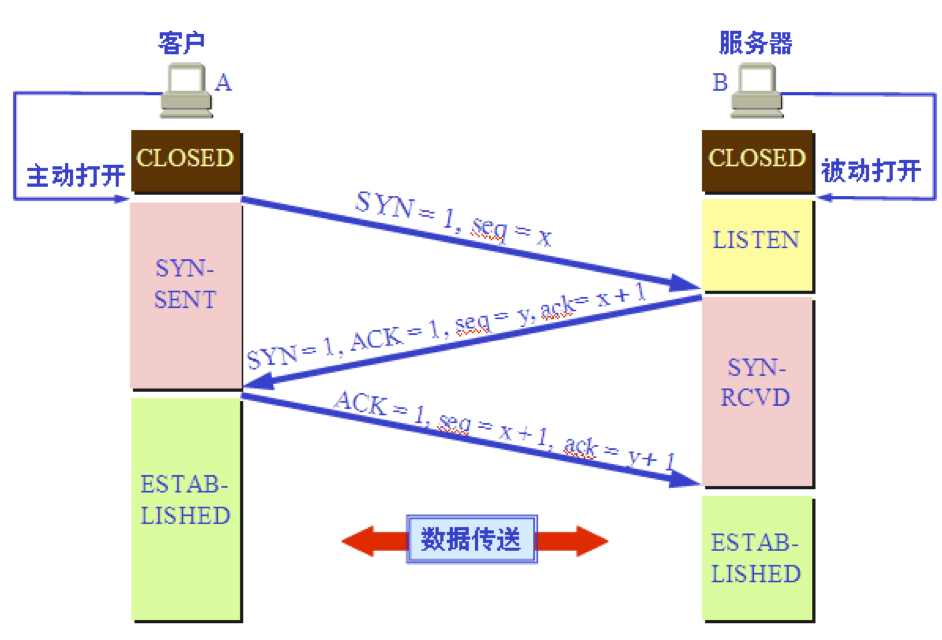
1.A 的 TCP 向 B 发出连接请求报文段,其首部中的同步位 SYN = 1,并选择序号 seq = x,表明传送数据时的第一个数据字节的序号是 x。
- B 的 TCP 收到连接请求报文段后,如同意,则发回确认。B 在确认报文段中应使
SYN = 1,使ACK = 1,其确认号ack = x+1,自己选择的序号seq = y。 - A 收到此报文段后向 B 给出确认,其
ACK = 1,确认号ack = y+1。A 的 TCP 通知上层应用进程,连接已经建立。B 的 TCP 收到主机 A 的确认后,也通知其上层应用进程:TCP 连接已经建立。
TCP 的连接释放
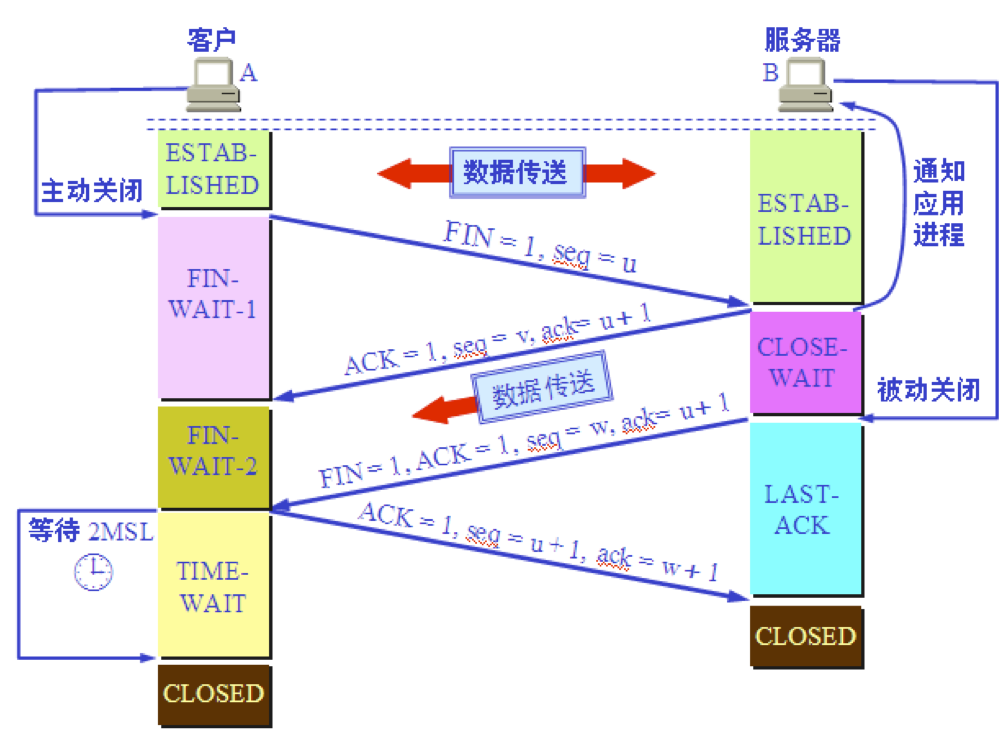
1.数据传输结束后,通信的双方都可释放连接。现在 A 的应用进程先向其 TCP 发出连接释放报文段,并停止再发送数据,主动关闭 TCP 连接。A 把连接释放报文段首部的 FIN = 1,其序号seq = u,等待 B 的确认。
- B 发出确认,确认号
ack = u+1,而这个报文段自己的序号seq = v。TCP 服务器进程通知高层应用进程。从 A 到 B 这个方向的连接就释放了,TCP 连接处于半关闭状态。B 若发送数据,A 仍要接收。 - 若 B 已经没有要向 A 发送的数据,其应用进程就通知 TCP 释放连接。
4.A 收到连接释放报文段后,必须发出确认。在确认报文段中
ACK = 1,确认号ack = w +1,自己的序号seq = u + 1。
A 必须等待 2MSL 的时间 第一,为了保证 A 发送的最后一个 ACK 报文段能够到达 B。 第二,防止 “已失效的连接请求报文段”出现在本连接中。A 在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以使本连接持续的时间内所产生的所有报文段,都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
第 6 章 应用层
域名系统 DNS 因特网采用层次结构的命名树作为主机的名字,并使用分布式的域名系统 DNS。 名字到 IP 地址的解析是由若干个域名服务器程序完成的。域名服务器程序在专设的结点上运行,运行该程序的机器称为域名服务器。
顶级域名 TLD (Top Level Domain) (1) 国家顶级域名 nTLD:如: .cn 表示中国,.us 表示美国,.uk 表示英国,等等。 (2) 通用顶级域名 gTLD:最早的顶级域名是: .com (公司和企业) .net (网络服务机构) .org (非赢利性组织) .edu (美国专用的教育机构() .gov (美国专用的政府部门) .mil (美国专用的军事部门) .int (国际组织) (3) 基础结构域名(infrastructure domain):这种顶级域名只有一个,即 arpa,用于反向域名解析,因此又称为反向域名。
域名服务器 一个服务器所负责管辖的(或有权限的)范围叫做区(zone)。 各单位根据具体情况来划分自己管辖范围的区。但在一个区中的所有节点必须是能够连通的。 每一个区设置相应的权限域名服务器,用来保存该区中的所有主机的域名到IP地址的映射。 DNS 服务器的管辖范围不是以“域”为单位,而是以“区”为单位。
域名服务器有以下四种类型 1.根域名服务器 2.顶级域名服务器 3.权限域名服务器 4.本地域名服务器
根域名服务器 根域名服务器是最重要的域名服务器。所有的根域名服务器都知道所有的顶级域名服务器的域名和 IP 地址。 不管是哪一个本地域名服务器,若要对因特网上任何一个域名进行解析,只要自己无法解析,就首先求助于根域名服务器。 在因特网上共有13 个不同 IP 地址的根域名服务器,它们的名字是用一个英文字母命名,从a 一直到 m(前13 个字母)。
顶级域名服务器 这些域名服务器负责管理在该顶级域名服务器注册的所有二级域名。 当收到 DNS 查询请求时,就给出相应的回答(可能是最后的结果,也可能是下一步应当找的域名服务器的 IP 地址)。
权限域名服务器 这就是前面已经讲过的负责一个区的域名服务器。 当一个权限域名服务器还不能给出最后的查询回答时,就会告诉发出查询请求的 DNS 客户,下一步应当找哪一个权限域名服务器。
本地域名服务器 当一个主机发出 DNS 查询请求时,这个查询请求报文就发送给本地域名服务器。 每一个因特网服务提供者 ISP,或一个大学,甚至一个大学里的系,都可以拥有一个本地域名服务器, 这种域名服务器有时也称为默认域名服务器。
域名的解析过程
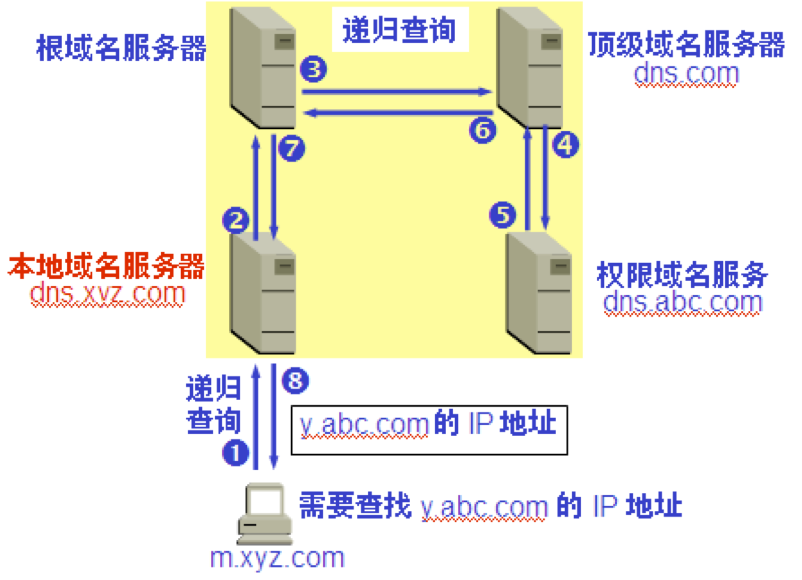
主机向本地域名服务器的查询一般都是采用递归查询。如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向其他根域名服务器继续发出查询请求报文。
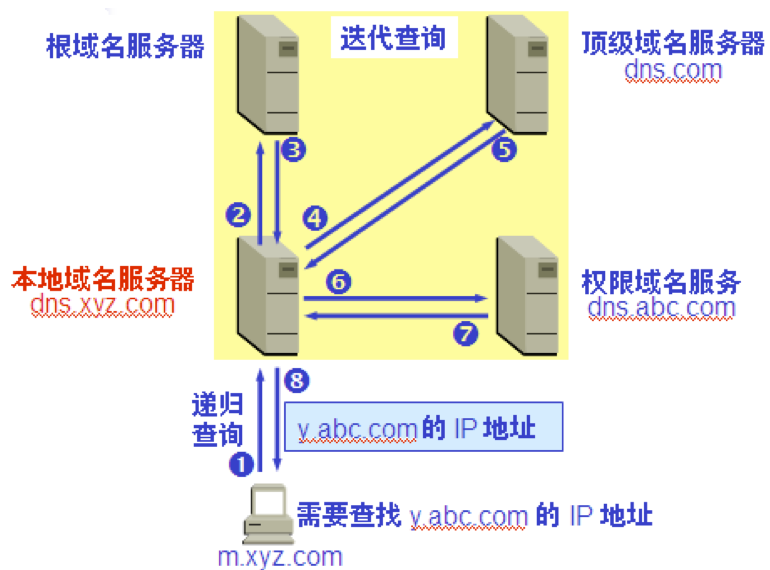
本地域名服务器向根域名服务器的查询通常是采用迭代查询。当根域名服务器收到本地域名服务器的迭代查询请求报文时,要么给出所要查询的 IP 地址,要么告诉本地域名服务器:“你下一步应当向哪一个域名服务器进行查询”。然后让本地域名服务器进行后续的查询。
文件传送协议
文件传送协议 FTP 只提供文件传送的一些基本的服务,它使用 TCP 可靠的运输服务。
FTP 的主要功能是减少或消除在不同操作系统下处理文件的不兼容性。
FTP 使用客户服务器方式。一个 FTP 服务器进程可同时为多个客户进程提供服务。FTP 的服务器进程由两大部分组成:一个主进程,负责接受新的请求;另外有若干个从属进程,负责处理单个请求。
主进程的工作步骤如下 1.打开熟知端口(端口号为 21),使客户进程能够连接上。 2.等待客户进程发出连接请求。 3.启动从属进程来处理客户进程发来的请求。从属进程对客户进程的请求处理完毕后即终止,但从属进程在运行期间根据需要还可能创建其他一些子进程。 4.回到等待状态,继续接受其他客户进程发来的请求。主进程与从属进程的处理是并发地进行。
两个TCP 连接 控制连接在整个会话期间一直保持打开,FTP 客户发出的传送请求通过控制连接发送给服务器端的控制进程,但控制连接不用来传送文件。 实际用于传输文件的是“数据连接”。服务器端的控制进程在接收到 FTP 客户发送来的文件传输请求后就创建“数据传送进程”和“数据连接”,用来连接客户端和服务器端的数据传送进程。 数据传送进程实际完成文件的传送,在传送完毕后关闭“数据传送连接”并结束运行。
两个不同的端口号 当客户进程向服务器进程发出建立连接请求时,要寻找连接服务器进程的熟知端口(21),同时还要告诉服务器进程自己的另一个端口号码,用于建立数据传送连接。 接着,服务器进程用自己传送数据的熟知端口(20)与客户进程所提供的端口号码建立数据传送连接。 由于 FTP 使用了两个不同的端口号,所以数据连接与控制连接不会发生混乱。
NFS 采用另一种思路 NFS 允许应用进程打开一个远地文件,并能在该文件的某一个特定的位置上开始读写数据。 NFS 可使用户只复制一个大文件中的一个很小的片段,而不需要复制整个大文件。 对于上述例子,计算机 A 的 NFS 客户软件,把要添加的数据和在文件后面写数据的请求一起发送到远地的计算机 B 的 NFS 服务器。NFS 服务器更新文件后返回应答信息。 在网络上传送的只是少量的修改数据。
简单文件传送协议 TFTP(Trivial File Transfer Protocol)
1.TFTP 是一个很小且易于实现的文件传送协议。
2.TFTP 使用客户服务器方式和使用 UDP 数据报,因此 TFTP 需要有自己的差错改正措施。
3.TFTP 只支持文件传输而不支持交互。
4.TFTP 没有一个庞大的命令集,没有列目录的功能,也不能对用户进行身份鉴别。
TFTP 的主要特点 (1) 每次传送的数据 PDU 中有 512 字节的数据,但最后一次可不足 512 字节。 (2) 数据 PDU 也称为文件块(block),每个块按序编号,从 1 开始。 (3) 支持 ASCII 码或二进制传送。 (4) 可对文件进行读或写。 (5) 使用很简单的首部。
远程终端协议 TELNET
TELNET 是一个简单的远程终端协议,也是因特网的正式标准。 用户用 TELNET 就可在其所在地通过 TCP 连接注册(即登录)到远地的另一个主机上(使用主机名或 IP 地址)。 TELNET 能将用户的击键传到远地主机,同时也能将远地主机的输出通过 TCP 连接返回到用户屏幕。这种服务是透明的,因为用户感觉到好像键盘和显示器是直接连在远地主机上。
TELNET 使用网络虚拟终端 NVT 格式 客户软件把用户的击键和命令转换成 NVT 格式,并送交服务器。 服务器软件把收到的数据和命令,从 NVT 格式转换成远地系统所需的格式。 向用户返回数据时,服务器把远地系统的格式转换为 NVT 格式,本地客户再从 NVT 格式转换到本地系统所需的格式。
万维网 WWW 代理服务器(proxy server)又称为万维网高速缓存(Web cache),它代表浏览器发出 HTTP 请求。 万维网高速缓存把最近的一些请求和响应暂存在本地磁盘中。 当与暂时存放的请求相同的新请求到达时,万维网高速缓存就把暂存的响应发送出去,而不需要按 URL 的地址再去因特网访问该资源。
HTTP 的报文结构 HTTP 有两类报文: 请求报文——从客户向服务器发送请求报文。 响应报文——从服务器到客户的回答。 由于HTTP 是面向正文的(text-oriented),因此在报文中的每一个字段都是一些 ASCII 码串,因而每个字段的长度都是不确定的。
在服务器上存放用户的信息 1.万维网站点使用 Cookie 来跟踪用户。 2.Cookie 表示在 HTTP 服务器和客户之间传递的状态信息。 3.使用 Cookie 的网站服务器为用户产生一个唯一的识别码。利用此识别码,网站就能够跟踪该用户在该网站的活动。
通用网关接口 CGI
CGI 是一种标准,它定义了动态文档应如何创建,输入数据应如何提供给应用程序,以及输出结果应如何使用。 万维网服务器与 CGI 的通信遵循 CGI 标准。 “通用”:CGI 标准所定义的规则对其他任何语言都是通用的。 “网关”:CGI 程序的作用像网关。 “接口”:有一些已定义好的变量和调用等可供其他 CGI 程序使用。
活动万维网文档 活动文档(active document)技术把所有的工作都转移给浏览器端。 每当浏览器请求一个活动文档时,服务器就返回一段程序副本在浏览器端运行。 活动文档程序可与用户直接交互,并可连续地改变屏幕的显示。 由于活动文档技术不需要服务器的连续更新传送,对网络带宽的要求也不会太高。
电子邮件 电子邮件的一些标准 发送邮件的协议:SMTP 读取邮件的协议:POP3 和 IMAP MIME 在其邮件首部中说明了邮件的数据类型(如文本、声音、图像、视像等),使用 MIME 可在邮件中同时传送多种类型的数据。
电子邮件的最主要的组成构件
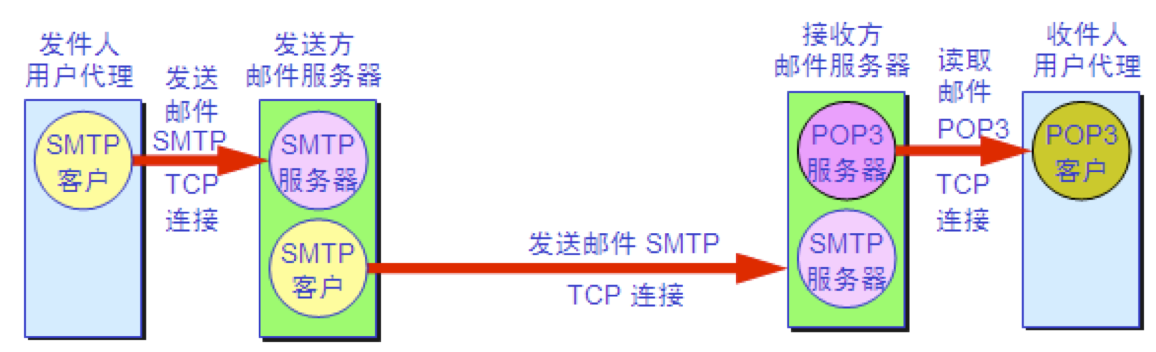
简单邮件传送协议 SMTP SMTP 通信的三个阶段
- 连接建立:连接是在发送主机的 SMTP 客户和接收主机的 SMTP 服务器之间建立的。SMTP不使用中间的邮件服务器。
- 邮件传送
- 连接释放:邮件发送完毕后,SMTP 应释放 TCP 连接。
邮件读取协议POP3 和 IMAP POP 也使用客户服务器的工作方式。 在接收邮件的用户 PC 机中必须运行 POP 客户程序,而在用户所连接的 ISP 的邮件服务器中则运行 POP 服务器程序。
IMAP 协议(Internet Message Access Protocol IMAP 也是按客户服务器方式工作,现在较新的是版本 4,即 IMAP4。 用户在自己的 PC 机上就可以操纵 ISP 的邮件服务器的邮箱,就像在本地操纵一样。 因此 IMAP 是一个联机协议。当用户 PC 机上的 IMAP 客户程序打开 IMAP 服务器的邮箱时,用户就可看到邮件的首部。若用户需要打开某个邮件,则该邮件才传到用户的计算机上。
IMAP 的特点 1.IMAP最大的好处就是用户可以在不同的地方使用不同的计算机随时上网阅读和处理自己的邮件。 2.IMAP 还允许收件人只读取邮件中的某一个部分。例如,收到了一个带有视像附件(此文件可能很大)的邮件。为了节省时间,可以先下载邮件的正文部分,待以后有时间再读取或下载这个很长的附件。 3.IMAP 的缺点是如果用户没有将邮件复制到自己的 PC 机上,则邮件一直是存放在 IMAP 服务器上。因此用户需要经常与 IMAP 服务器建立连接。
基于万维网的电子邮件

通用因特网邮件扩充 MIME SMTP 有以下缺点: 1.SMTP 不能传送可执行文件或其他的二进制对象。 2.SMTP 限于传送 7 位的 ASCII 码。许多其他非英语国家的文字(如中文、俄文,甚至带重音符号的法文或德文)就无法传送。 3.SMTP 服务器会拒绝超过一定长度的邮件。 4.某些 SMTP 的实现并没有完全按照[RFC 821]的 SMTP 标准。
MIME 的特点 MIME 并没有改动 SMTP 或取代它。 MIME 的意图是继续使用目前的[RFC 822]格式,但增加了邮件主体的结构,并定义了传送非 ASCII 码的编码规则。
MIME 和 SMTP 的关系

动态主机配置协议 DHCP 动态主机配置协议 DHCP 提供了即插即用连网(plug-and-play networking)的机制。 这种机制允许一台计算机加入新的网络和获取IP地址而不用手工参与。
DHCP 使用客户服务器方式 1.需要 IP 地址的主机在启动时就向 DHCP 服务器广播发送发现报文(DHCPDISCOVER),这时该主机就成为 DHCP 客户。 2.本地网络上所有主机都能收到此广播报文,但只有 DHCP 服务器才回答此广播报文。 3.DHCP 服务器先在其数据库中查找该计算机的配置信息。若找到,则返回找到的信息。若找不到,则从服务器的 IP 地址池(address pool)中取一个地址分配给该计算机。DHCP 服务器的回答报文叫做提供报文(DHCPOFFER)。
DHCP 中继代理(relay agent) 并不是每个网络上都有 DHCP 服务器,这样会使 DHCP 服务器的数量太多。现在是每一个网络至少有一个 DHCP 中继代理,它配置了 DHCP 服务器的 IP 地址信息。 当 DHCP 中继代理收到主机发送的发现报文后,就以单播方式向 DHCP 服务器转发此报文,并等待其回答。收到 DHCP 服务器回答的提供报文后,DHCP 中继代理再将此提供报文发回给主机。
租用期(lease period) DHCP 服务器分配给 DHCP 客户的 IP 地址的临时的,因此 DHCP 客户只能在一段有限的时间内使用这个分配到的 IP 地址。DHCP 协议称这段时间为租用期。
DHCP 协议的工作过程
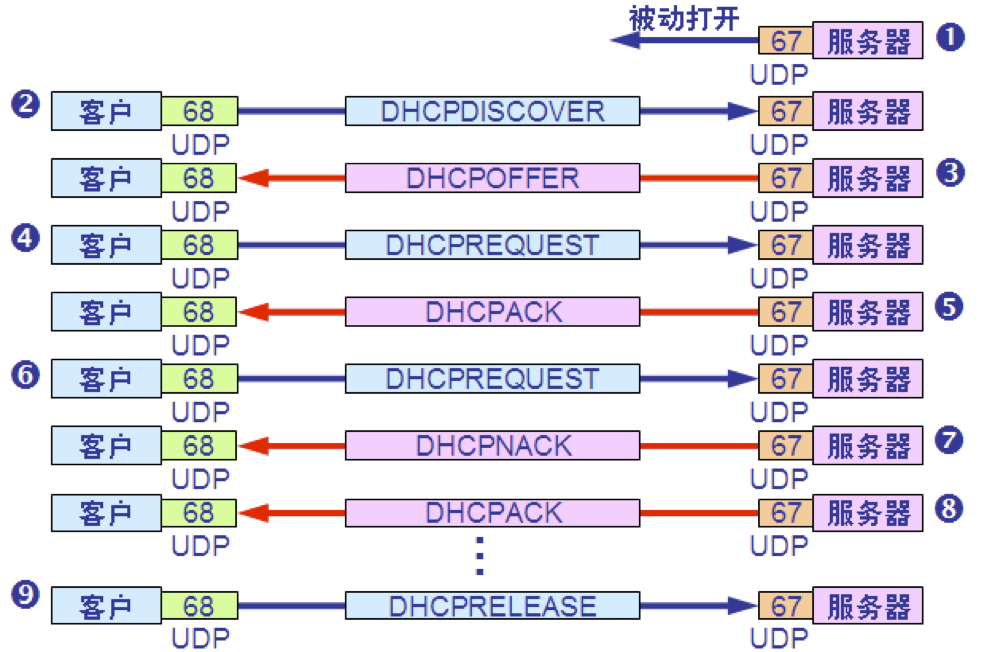
1.DHCP 服务器被动打开 UDP 端口 67,等待客户端发来的报文。 2.DHCP 客户从 UDP 端口 68发送 DHCP 发现报文。 3.凡收到 DHCP 发现报文的 DHCP 服务器都发出 DHCP 提供报文,因此 DHCP 客户可能收到多个 DHCP 提供报文。 4.DHCP 客户从几个 DHCP 服务器中选择其中的一个,并向所选择的 DHCP 服务器发送 DHCP 请求报文。 5.被选择的 DHCP 服务器发送确认报文DHCPACK,进入已绑定状态,并可开始使用得到的临时 IP 地址了。 DHCP 客户现在要根据服务器提供的租用期 T 设置两个计时器 T1 和 T2,它们的超时时间分别是 0.5T 和 0.875T。当超时时间到就要请求更新租用期。 6.租用期过了一半(T1 时间到),DHCP 发送请求报文 DHCPREQUEST 要求更新租用期。 7.DHCP 服务器若同意,则发回确认报文DHCPACK。DHCP 客户得到了新的租用期,重新设置计时器。 8.DHCP 服务器若不同意,则发回否认报文DHCPNACK。这时 DHCP 客户必须立即停止使用原来的 IP 地址,而必须重新申请 IP 地址(回到步骤2)。 若DHCP服务器不响应步骤6的请求报文DHCPREQUEST,则在租用期过了 87.5% 时,DHCP 客户必须重新发送请求报文 DHCPREQUEST(重复步骤6),然后又继续后面的步骤。 9.DHCP 客户可随时提前终止服务器所提供的租用期,这时只需向 DHCP 服务器发送释放报文 DHCPRELEASE 即可。
简单网络管理协议 SNMP SNMP 的指导思想 1.SNMP 最重要的指导思想就是要尽可能简单。 2.SNMP 的基本功能包括监视网络性能、检测分析网络差错和配置网络设备等。 3.在网络正常工作时,SNMP 可实现统计、配置、和测试等功能。当网络出故障时,可实现各种差错检测和恢复功能。 4.虽然 SNMP 是在 TCP/IP 基础上的网络管理协议,但也可扩展到其他类型的网络设备上。
SNMP 的管理站和委托代理 整个系统必须有一个管理站。 管理进程和代理进程利用 SNMP 报文进行通信,而 SNMP 报文又使用 UDP 来传送。 若网络元素使用的不是 SNMP 而是另一种网络管理协议,SNMP 协议就无法控制该网络元素。这时可使用委托代理(proxy agent)。委托代理能提供如协议转换和过滤操作等功能对被管对象进行管理。
SNMP 的网络管理由三个部分组成 1.SNMP 本身 SNMP 定义了管理站和代理之间所交换的分组格式。所交换的分组包含各代理中的对象(变量)名及其状态(值)。 SNMP 负责读取和改变这些数值。 2.管理信息结构 SMI (Structure of Management Information) SMI 定义了命名对象和定义对象类型(包括范围和长度)的通用规则,以及把对象和对象的值进行编码的规则。 这样做是为了确保网络管理数据的语法和语义的无二义性。但从 SMI 的名称并不能看出它的功能。 SMI 并不定义一个实体应管理的对象数目,也不定义被管对象名以及对象名及其值之间的关联。 3.管理信息库 MIB (Management Information Base)。 MIB 在被管理的实体中创建了命名对象,并规定了其类型。
第 7 章 网络安全
计算机网络面临的安全性威胁
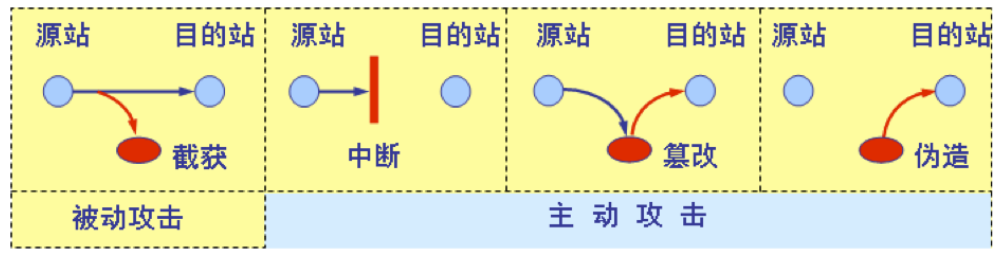
(1) 截获——从网络上窃听他人的通信内容。(被动攻击)
(2) 中断——有意中断他人在网络上的通信。
(3) 篡改——故意篡改网络上传送的报文。
(4) 伪造——伪造信息在网络上传送。
被动攻击和主动攻击 在被动攻击中,攻击者只是观察和分析某一个协议数据单元 PDU 而不干扰信息流。 主动攻击是指攻击者对某个连接中通过的 PDU 进行各种处理。
恶意程序(rogue program) (1) 计算机病毒——会“传染”其他程序的程序,“传染”是通过修改其他程序来把自身或其变种复制进去完成的。 (2) 计算机蠕虫——通过网络的通信功能将自身从一个结点发送到另一个结点并启动运行的程序。 (3) 特洛伊木马——一种程序,它执行的功能超出所声称的功能。 (4) 逻辑炸弹——一种当运行环境满足某种特定条件时执行其他特殊功能的程序。
两类密码体制
1.对称密钥密码体制 所谓常规密钥密码体制,即加密密钥与解密密钥是相同的密码体制。 这种加密系统又称为对称密钥系统。
数据加密标准 DES 数据加密标准 DES 属于常规密钥密码体制,是一种分组密码。 在加密前,先对整个明文进行分组。每一个组长为 64 位。 然后对每一个 64 位 二进制数据进行加密处理,产生一组 64 位密文数据。 最后将各组密文串接起来,即得出整个的密文。 使用的密钥为 64 位(实际密钥长度为 56 位,有 8 位用于奇偶校验)。
DES 的保密性 DES 的保密性仅取决于对密钥的保密,而算法是公开的。尽管人们在破译 DES 方面取得了许多进展,但至今仍未能找到比穷举搜索密钥更有效的方法。 DES 是世界上第一个公认的实用密码算法标准,它曾对密码学的发展做出了重大贡献。 目前较为严重的问题是 DES 的密钥的长度。 现在已经设计出来搜索 DES 密钥的专用芯片。
2.公钥密码体制 公钥密码体制使用不同的加密密钥与解密密钥,是一种“由已知加密密钥推导出解密密钥在计算上是不可行的”密码体制。 公钥密码体制的产生主要是因为两个方面的原因,一是由于常规密钥密码体制的密钥分配问题,另一是由于对数字签名的需求。 现有最著名的公钥密码体制是RSA 体制
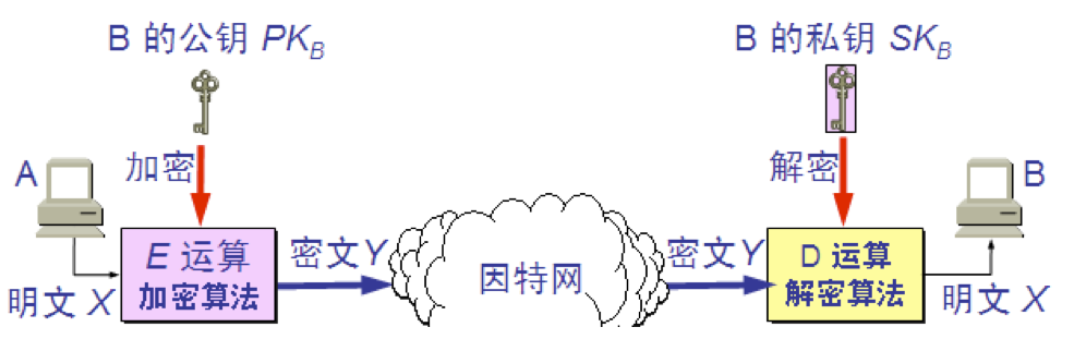
加密密钥与解密密钥 在公钥密码体制中,加密密钥(即公钥) PK 是公开信息,而解密密钥(即私钥或秘钥) SK 是需要保密的。 加密算法 E 和解密算法 D 也都是公开的。 虽然秘钥 SK 是由公钥 PK 决定的,但却不能根据 PK 计算出 SK。
应当注意 任何加密方法的安全性取决于密钥的长度,以及攻破密文所需的计算量。在这方面,公钥密码体制并不具有比传统加密体制更加优越之处。 由于目前公钥加密算法的开销较大,在可见的将来还看不出来要放弃传统的加密方法。公钥还需要密钥分配协议,具体的分配过程并不比采用传统加密方法时更简单。
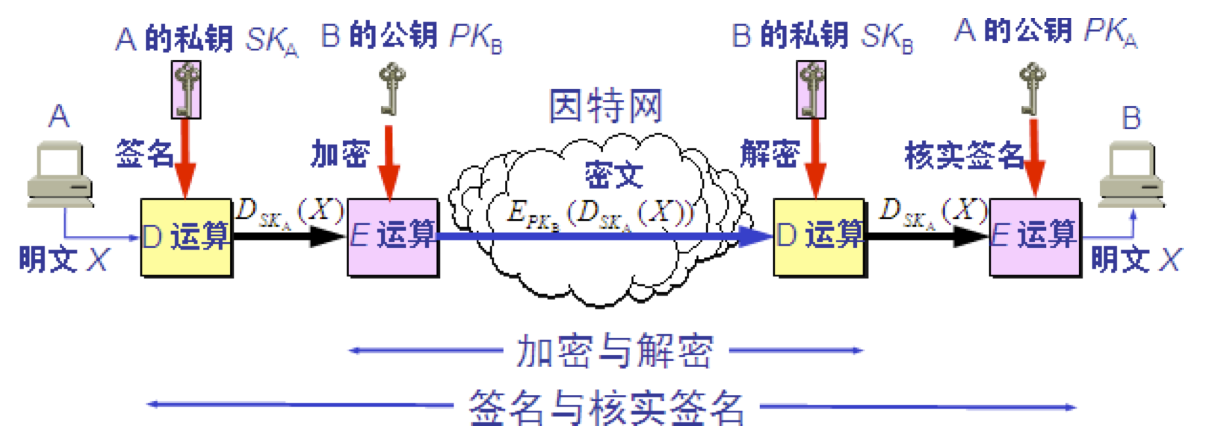
公钥算法的特点 1.发送者 A 用 B 的公钥 PKB 对明文 X 加密(E 运算)后,在接收者 B 用自己的私钥 SKB 解密(D 运算),即可恢复出明文。 2.解密密钥是接收者专用的秘钥,对其他人都保密。 3.加密密钥是公开的,但不能用它来解密。 4.加密和解密的运算可以对调。 5.在计算机上可容易地产生成对的 PK 和 SK。 6.从已知的 PK 实际上不可能推导出 SK,即从 PK 到 SK 是“计算上不可能的”。 7.加密和解密算法都是公开的。
公钥密码体制
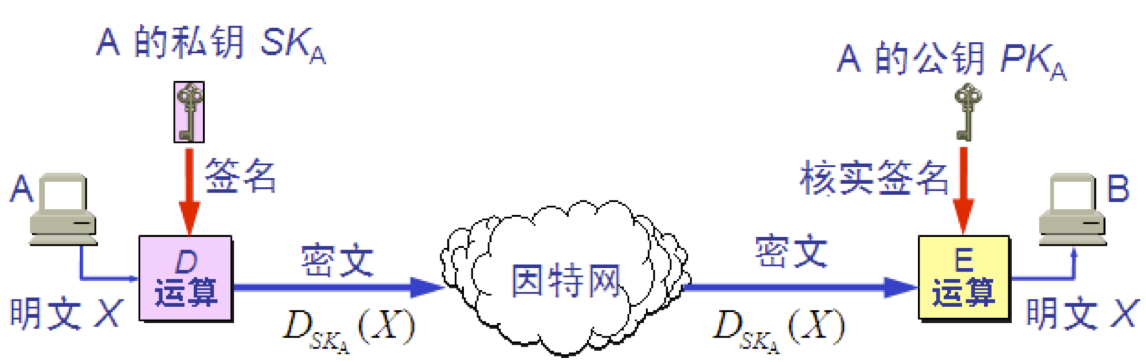
数字签名 数字签名必须保证以下三点: (1) 报文鉴别——接收者能够核实发送者对报文的签名; (2) 报文的完整性——发送者事后不能抵赖对报文的签名; (3) 不可否认——接收者不能伪造对报文的签名。
数字签名的实现
具有保密性的数字签名
鉴别 在信息的安全领域中,对付被动攻击的重要措施是加密,而对付主动攻击中的篡改和伪造则要用鉴别(authentication) 。使用加密就可达到报文鉴别的目的。但在网络的应用中,许多报文并不需要加密。应当使接收者能用很简单的方法鉴别报文的真伪。当我们传送不需要加密的报文时,应当使接收者能用很简单的方法鉴别报文的真伪。
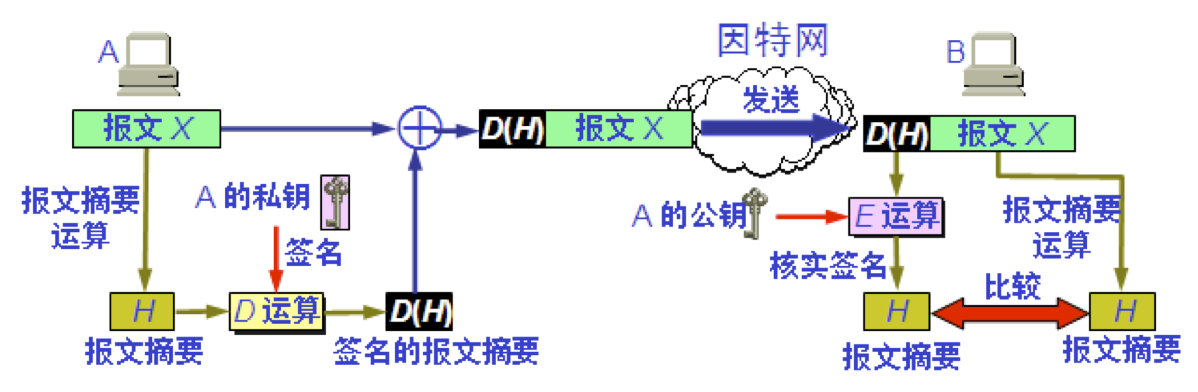
报文摘要 MD (Message Digest) A 将报文 X 经过报文摘要算法运算后得出很短的报文摘要 H。然后用自己的私钥对 H 进行 D 运算,即进行数字签名。得出已签名的报文摘要 D(H) ,并将其追加在报文 X 后面发送给 B。 B 收到报文后首先把已签名的 D(H) 和报文 X 分离。然后再做两件事。 1.用A的公钥对 D(H) 进行E运算,得出报文摘要 H 。 2.对报文 X 进行报文摘要运算,看是否能够得出同样的报文摘要 H。如一样,就能以极高的概率断定收到的报文是 A 产生的。否则就不是。
报文摘要的优点 仅对短得多的定长报文摘要 H 进行数字签名要比对整个长报文进行数字签名要简单得多,所耗费的计算资源也小得多。但对鉴别报文 X 来说,效果是一样的。也就是说,报文 X 和已签名的报文摘要 D(H) 合在一起是不可伪造的,是可检验的和不可否认的。
报文摘要算法 报文摘要算法就是一种散列函数。这种散列函数也叫做密码编码的检验和。报文摘要算法是精心选择的一种单向函数。可以很容易地计算出一个长报文 X 的报文摘要 H,但要想从报文摘要 H 反过来找到原始的报文 X,则实际上是不可能的。若想找到任意两个报文,使得它们具有相同的报文摘要,那么实际上也是不可能的。
报文摘要的实现
实体鉴别 实体鉴别和报文鉴别不同。报文鉴别是对每一个收到的报文都要鉴别报文的发送者,而实体鉴别是在系统接入的全部持续时间内对和自己通信的对方实体只需验证一次。
最简单的实体鉴别过程
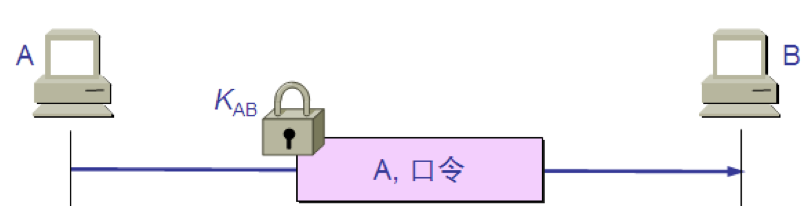
A 发送给 B 的报文的被加密,使用的是对称密钥 KAB。 B 收到此报文后,用共享对称密钥 KAB 进行解密,因而鉴别了实体 A 的身份。
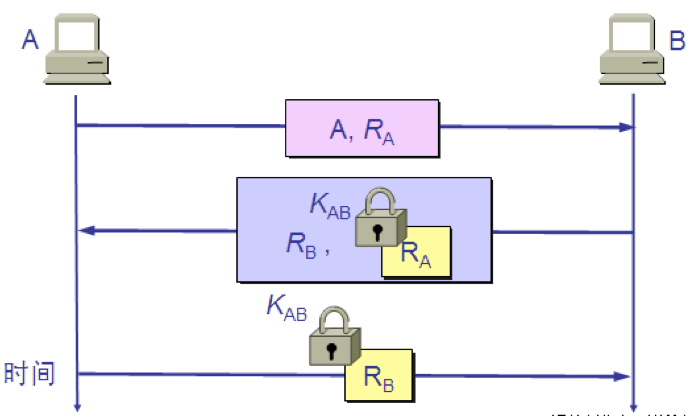
明显的漏洞 入侵者 C 可以从网络上截获 A 发给 B 的报文。C 并不需要破译这个报文(因为这可能很花很多时间)而可以直接把这个由 A 加密的报文发送给 B,使 B 误认为 C 就是 A。然后 B 就向伪装是 A 的 C 发送应发给 A 的报文。 这就叫做重放攻击(replay attack)。C 甚至还可以截获 A 的 IP 地址,然后把 A 的 IP 地址冒充为自己的 IP 地址(这叫做 IP 欺骗),使 B 更加容易受骗。 为了对付重放攻击,可以使用不重数(nonce)。不重数就是一个不重复使用的大随机数,即“一次一数”。
使用不重数进行鉴别
密钥分配
对称密钥的分配
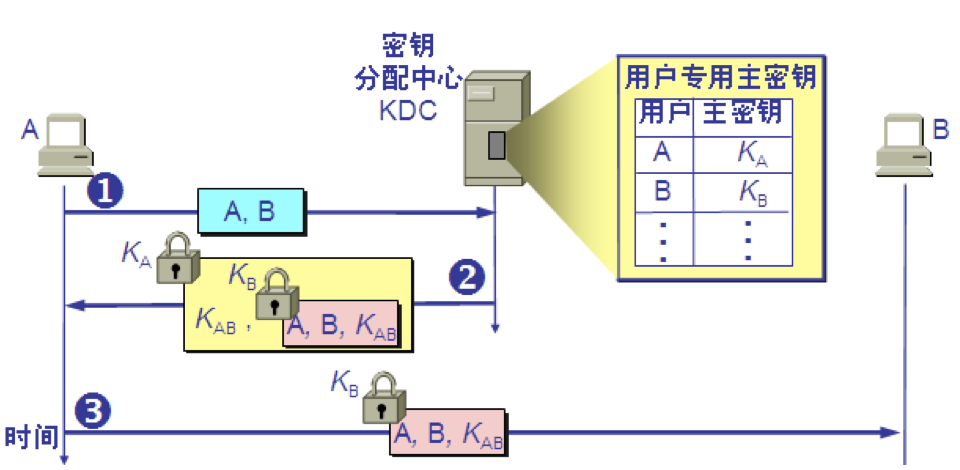
目前常用的密钥分配方式是设立密钥分配中心KDC (Key Distribution Center)。 KDC 是大家都信任的机构,其任务就是给需要进行秘密通信的用户临时分配一个会话密钥(仅使用一次)。 用户 A 和 B 都是 KDC 的登记用户,并已经在 KDC 的服务器上安装了各自和 KDC 进行通信的主密钥(master key)KA 和 KB。 “主密钥”可简称为“密钥”。
公钥的分配 需要有一个值得信赖的机构——即认证中心CA (Certification Authority),来将公钥与其对应的实体(人或机器)进行绑定(binding)。 认证中心一般由政府出资建立。每个实体都有CA 发来的证书(certificate),里面有公钥及其拥有者的标识信息。此证书被 CA 进行了数字签名。任何用户都可从可信的地方获得认证中心 CA 的公钥,此公钥用来验证某个公钥是否为某个实体所拥有。有的大公司也提供认证中心服务。
因特网使用的安全协议 网络层安全协议 IPsec 与安全关联 SA IPsec 中最主要的两个部分 鉴别首部 AH (Authentication Header): AH鉴别源点和检查数据完整性,但不能保密。 封装安全有效载荷 ESP (Encapsulation Security Payload):ESP 比 AH 复杂得多,它鉴别源点、检查数据完整性和提供保密。
安全关联 SA (Security Association) 在使用 AH 或 ESP 之前,先要从源主机到目的主机建立一条网络层的逻辑连接。此逻辑连接叫做安全关联 SA。 IPsec 就把传统的因特网无连接的网络层转换为具有逻辑连接的层。
运输层安全协议
安全套接层 SSL
SSL 是安全套接层 (Secure Socket Layer),可对万维网客户与服务器之间传送的数据进行加密和鉴别。 SSL 在双方的联络阶段协商将使用的加密算法和密钥,以及客户与服务器之间的鉴别。在联络阶段完成之后,所有传送的数据都使用在联络阶段商定的会话密钥。SSL 不仅被所有常用的浏览器和万维网服务器所支持,而且也是运输层安全协议 TLS (Transport Layer Security)的基础。
SSL 的位置

1.在发送方,SSL 接收应用层的数据(如 HTTP 或 IMAP 报文),对数据进行加密,然后把加了密的数据送往 TCP 套接字。 2.在接收方,SSL 从 TCP 套接字读取数据,解密后把数据交给应用层。
SSL 提供以下三个功能 (1) SSL 服务器鉴别 允许用户证实服务器的身份。具有 SS L 功能的浏览器维持一个表,上面有一些可信赖的认证中心 CA (Certificate Authority)和它们的公钥。 (2) 加密的 SSL 会话 客户和服务器交互的所有数据都在发送方加密,在接收方解密。 (3) SSL 客户鉴别 允许服务器证实客户的身份。
安全电子交易 SET (Secure Electronic Transaction) SET 的主要特点是: (1) SET 是专为与支付有关的报文进行加密的。 (2) SET 协议涉及到三方,即顾客、商家和商业银行。所有在这三方之间交互的敏感信息都被加密。 (3) SET 要求这三方都有证书。在 SET 交易中,商家看不见顾客传送给商业银行的信用卡号码。
应用层的安全协议 PGP (Pretty Good Privacy) PGP 是一个完整的电子邮件安全软件包,包括加密、鉴别、电子签名和压缩等技术。 PGP 并没有使用什么新的概念,它只是将现有的一些算法如 MD5,RSA,以及 IDEA 等综合在一起而已。 虽然 PGP 已被广泛使用,但 PGP 并不是因特网的正式标准。
PEM (Privacy Enhanced Mail) PEM 是因特网的邮件加密建议标准。 PEM 的功能和 PGP 的差不多,都是对基于 RFC 822 的电子邮件进行加密和鉴别。 PEM 有比 PGP 更加完善的密钥管理机制。由认证中心发布证书,上面有用户姓名、公钥以及密钥的使用期限。每个证书有一个唯一的序号。证书还包括用认证中心秘钥签了名的 MD5 散列函数。
链路加密与端到端加密 链路加密 在采用链路加密的网络中,每条通信链路上的加密是独立实现的。通常对每条链路使用不同的加密密钥。 相邻结点之间具有相同的密钥,因而密钥管理易于实现。链路加密对用户来说是透明的,因为加密的功能是由通信子网提供的。 由于报文是以明文形式在各结点内加密的,所以结点本身必须是安全的。所有的中间结点(包括可能经过的路由器)未必都是安全的。因此必须采取有效措施。 链路加密的最大缺点是在中间结点暴露了信息的内容。在网络互连的情况下,仅采用链路加密是不能实现通信安全的。
端到端加密 端到端加密是在源结点和目的结点中对传送的 PDU 进行加密和解密,报文的安全性不会因中间结点的不可靠而受到影响。 在端到端加密的情况下,PDU 的控制信息部分(如源结点地址、目的结点地址、路由信息等)不能被加密,否则中间结点就不能正确选择路由。
防火墙(firewall) 防火墙是由软件、硬件构成的系统,是一种特殊编程的路由器,用来在两个网络之间实施接入控制策略。接入控制策略是由使用防火墙的单位自行制订的,为的是可以最适合本单位的需要。
防火墙技术一般分为两类 (1) 网络级防火墙——用来防止整个网络出现外来非法的入侵。属于这类的有分组过滤和授权服务器。前者检查所有流入本网络的信息,然后拒绝不符合事先制订好的一套准则的数据,而后者则是检查用户的登录是否合法。 (2) 应用级防火墙——从应用程序来进行接入控制。通常使用应用网关或代理服务器来区分各种应用。例如,可以只允许通过访问万维网的应用,而阻止 FTP 应用的通过。
第 8 章 因特网上的音频/视频服务
目前因特网提供的音频/视频服务大体上可分为三种类型 流式(streaming)存储音频/视频 ——边下载边播放。 流式实况音频/视频 ——边录制边发送 。 交互式音频/视频——实时交互式通信。
第 9 章 无线网络
无线局域网
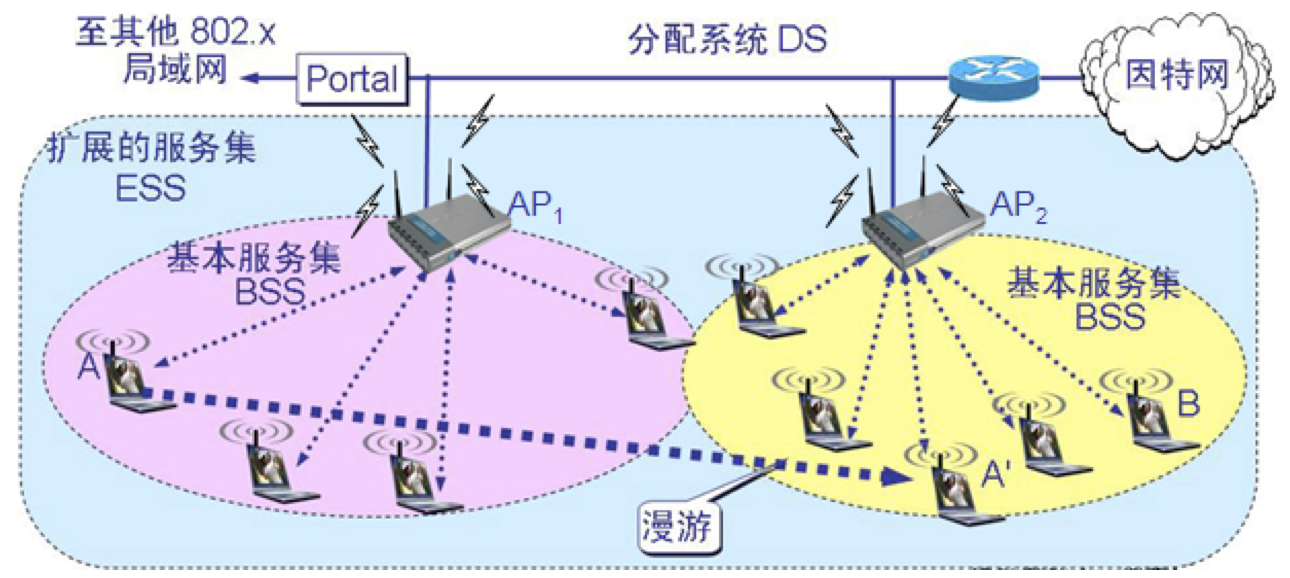
一个基本服务集 BSS 包括一个基站和若干个移动站,所有的站在本 BSS 以内都可以直接通信,但在和本 BSS 以外的站通信时 ,都要通过本 BSS 的基站。 基本服务集内的基站叫做接入点 AP (Access Point)其作用和网桥相似。当网络管理员安装 AP 时,必须为该 AP 分配一个不超过 32 字节的服务集标识符 SSID 和一个信道。 一个基本服务集可以是孤立的,也可通过接入点 AP连接到一个主干分配系统 DS (Distribution System),然后再接入到另一个基本服务集,构成扩展的服务集ESS (Extended Service Set)。ESS 还可通过叫做门户(portal)为无线用户提供到非 802.11 无线局域网(例如,到有线连接的因特网)的接入。门户的作用就相当于一个网桥。 移动站 A 从某一个基本服务集漫游到另一个基本服务集(到 A 的位置),仍可保持与另一个移动站 B 进行通信。
与接入点 AP 建立关联(association) 一个移动站若要加入到一个基本服务集 BSS,就必须先选择一个接入点 AP,并与此接入点建立关联。 建立关联就表示这个移动站加入了选定的 AP 所属的子网,并和这个 AP 之间创建了一个虚拟线路。 只有关联的 AP 才向这个移动站发送数据帧,而这个移动站也只有通过关联的 AP 才能向其他站点发送数据帧。
移动站与 AP 建立关联的方法 被动扫描,即移动站等待接收接入站周期性发出的信标帧(beacon frame)。信标帧中包含有若干系统参数(如服务集标识符 SSID 以及支持的速率等)。 主动扫描,即移动站主动发出探测请求帧(probe request frame),然后等待从 AP 发回的探测响应帧(probe response frame)。
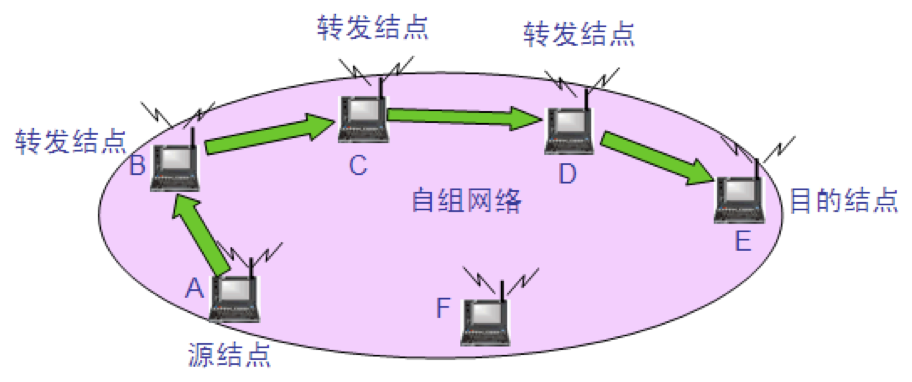
移动自组网络
自组网络是没有固定基础设施(即没有 AP)的无线局域网。这种网络由一些处于平等状态的移动站之间相互通信组成的临时网络。
无线传感器网络 WSN (Wireless Sensor Network) 由大量传感器结点通过无线通信技术构成的自组网络。 无线传感器网络的应用是进行各种数据的采集、处理和传输,一般并不需要很高的带宽,但是在大部分时间必须保持低功耗,以节省电池的消耗。 由于无线传感结点的存储容量受限,因此对协议栈的大小有严格的限制。 无线传感器网络还对网络安全性、结点自动配置、网络动态重组等方面有一定的要求。
移动自组网络和移动 IP 并不相同 1.移动 IP 技术使漫游的主机可以用多种方式连接到因特网。 2.移动 IP 的核心网络功能仍然是基于在固定互联网中一直在使用的各种路由选择协议。 3.移动自组网络是将移动性扩展到无线领域中的自治系统,它具有自己特定的路由选择协议,并且可以不和因特网相连。
802.11 局域网的 MAC 层协议
CSMA/CA 协议
无线局域网却不能简单地搬用 CSMA/CD 协议。这里主要有两个原因。
1.CSMA/CD 协议要求一个站点在发送本站数据的同时,还必须不间断地检测信道,但在无线局域网的设备中要实现这种功能就花费过大。
2.即使我们能够实现碰撞检测的功能,并且当我们在发送数据时检测到信道是空闲的,在接收端仍然有可能发生碰撞。
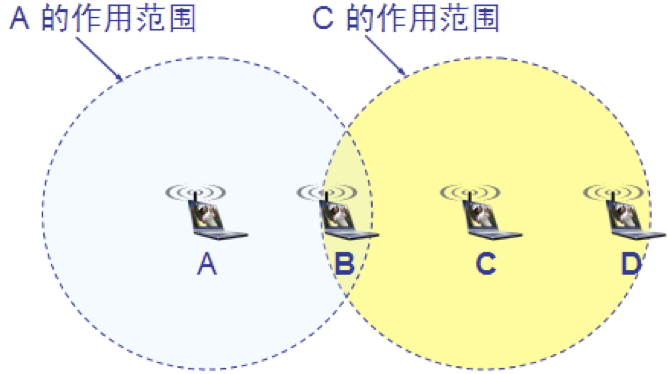
这种未能检测出媒体上已存在的信号的问题叫做隐蔽站问题(hidden station problem) 。当 A 和 C 检测不到无线信号时,都以为 B 是空闲的,因而都向 B 发送数据,结果发生碰撞。
当 A 和 C 检测不到无线信号时,都以为 B 是空闲的,因而都向 B 发送数据,结果发生碰撞。
其实 B 向 A 发送数据并不影响 C 向 D 发送数据这就是暴露站问题(exposed station problem)
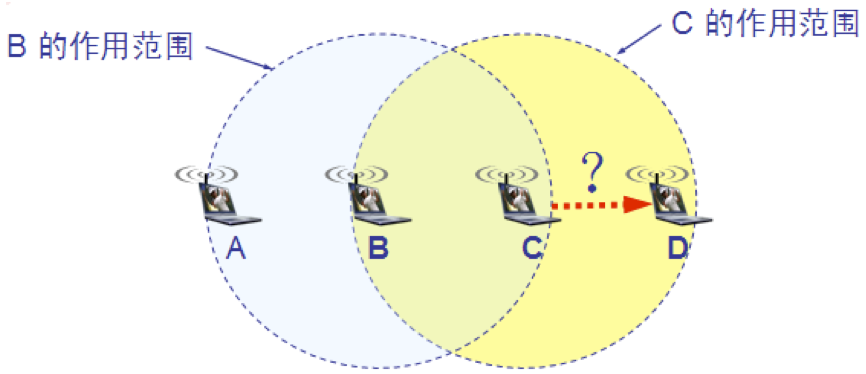
B 向 A 发送数据,而 C 又想和 D 通信。C 检测到媒体上有信号,于是就不敢向 D 发送数据。
CSMA/CA 协议的原理 欲发送数据的站先检测信道。在 802.11 标准中规定了在物理层的空中接口进行物理层的载波监听。 通过收到的相对信号强度是否超过一定的门限数值就可判定是否有其他的移动站在信道上发送数据。 当源站发送它的第一个 MAC 帧时,若检测到信道空闲,则在等待一段时间 DIFS 后就可发送。
为什么信道空闲还要再等待 这是考虑到可能有其他的站有高优先级的帧要发送。 如有,就要让高优先级帧先发送。
假定没有高优先级帧要发送 源站发送了自己的数据帧。 目的站若正确收到此帧,则经过时间间隔 SIFS 后,向源站发送确认帧 ACK。 若源站在规定时间内没有收到确认帧 ACK(由重传计时器控制这段时间),就必须重传此帧,直到收到确认为止,或者经过若干次的重传失败后放弃发送。
虚拟载波监听 虚拟载波监听(Virtual Carrier Sense)的机制是让源站将它要占用信道的时间(包括目的站发回确认帧所需的时间)通知给所有其他站,以便使其他所有站在这一段时间都停止发送数据。这样就大大减少了碰撞的机会。 “虚拟载波监听”是表示其他站并没有监听信道,而是由于其他站收到了“源站的通知”才不发送数据。 所谓“源站的通知”就是源站在其 MAC 帧首部中的第二个字段“持续时间”中填入了在本帧结束后还要占用信道多少时间(以微秒为单位),包括目的站发送确认帧所需的时间。
对信道进行预约 源站 A 在发送数据帧之前先发送一个短的控制帧,叫做请求发送 RTS (Request To Send),它包括源地址、目的地址和这次通信(包括相应的确认帧)所需的持续时间。 若媒体空闲,则目的站 B 就发送一个响应控制帧,叫做允许发送 CTS (Clear To Send),它包括这次通信所需的持续时间(从 RTS 帧中将此持续时间复制到 CTS 帧中)。
802.11 局域网的 MAC 帧 802.11 帧共有三种类型,即控制帧、数据帧和管理帧。 数据帧的三大部分 1.MAC 首部,共 30 字节。帧的复杂性都在帧的首部。 2.帧主体,也就是帧的数据部分,不超过2312 字节。这个数值比以太网的最大长度长很多。不过 802.11 帧的长度通常都是小于 1500 字节。 3.帧检验序列 FCS 是尾部,共 4 字节 802.11 数据帧最特殊的地方就是有四个地址字段。地址 4 用于自组网络。
无线个人区域网 WPAN (Wireless Personal Area Network) 在个人工作地方把属于个人使用的电子设备用无线技术连接起来自组网络,不需要使用接入点 AP。 整个网络的范围大约在 10 m 左右。它实际上就是一个低功率、小范围、低速率和低价格的电缆替代技术。WPAN 都工作在 2.4 GHz 的 ISM 频段。
蓝牙系统(Bluetooth) 最早使用的 WPAN 是 1994 年爱立信公司推出的蓝牙系统,其标准是 IEEE 802.15.1 。 蓝牙的数据率为 720 kb/s,通信范围在 10 米左右。
低速 WPAN 低速 WPAN 中最重要的就是 ZigBee。 ZigBee 技术主要用于各种电子设备(固定的、便携的或移动的)之间的无线通信,其主要特点是通信距离短(10 ~ 80 m),传输数据速率低,并且成本低廉。
高速 WPAN 高速 WPAN 用于在便携式多媒体装置之间传送数据,支持11 ~ 55 Mb/s的数据率。
无线城域网 WMAN WiMAX 常用来表示无线城域网 WMAN,这与Wi-Fi 常用来表示无线局域网 WLAN 相似。
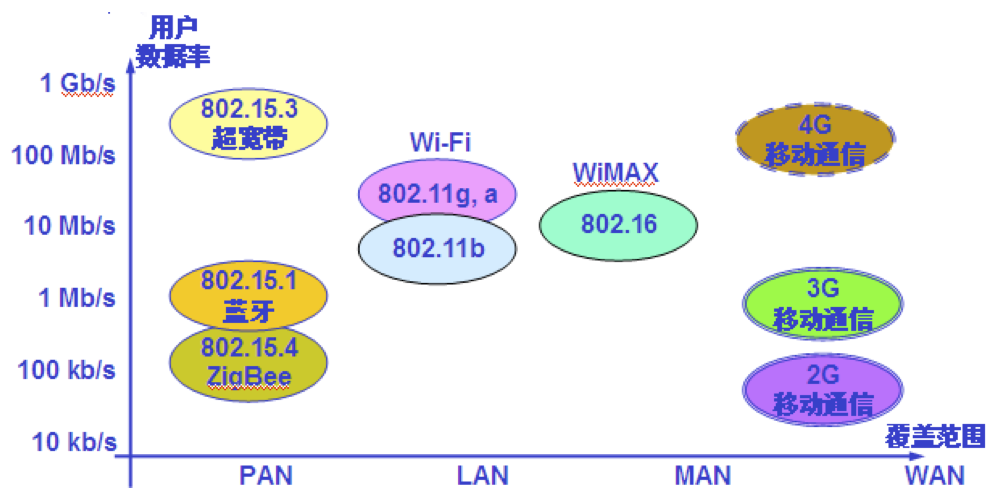
几种无线网络的比较
第 10 章 下一代因特网
下一代的网际协议 Ipv6 (Ipng) 要解决 IP 地址耗尽的问题的措施: 1.采用无类别编址 CIDR,使 IP 地址的分配更加合理。 2.采用网络地址转换 NAT 方法以节省全球 IP 地址。 3.采用具有更大地址空间的新版本的 IP 协议 IPv6。
IPv6 的基本首部 IPv6 数据报的首部 1.IPv6 将首部长度变为固定的 40 字节,称为基本首部(base header)。 2.将不必要的功能取消了,首部的字段数减少到只有 8 个。 3.取消了首部的检验和字段,加快了路由器处理数据报的速度。 4.在基本首部的后面允许有零个或多个扩展首部。 5.所有的扩展首部和数据合起来叫做数据报的有效载荷(payload)或净负荷。
IPv6 数据报的一般形式
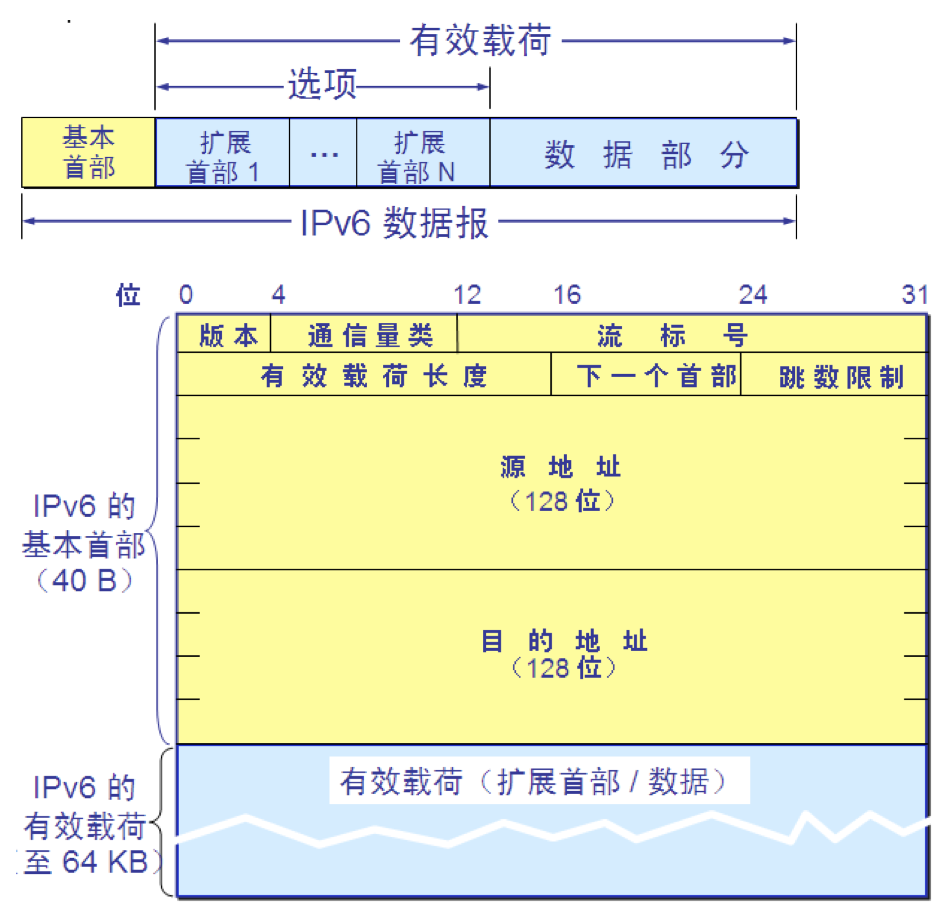
1.版本(version)—— 4 位。它指明了协议的版本,对 IPv6 该字段总是 6。 2.通信量类(traffic class)—— 8 位。这是为了区分不同的 IPv6 数据报的类别或优先级。目前正在进行不同的通信量类性能的实验。 3.流标号(flow label)—— 20 位。 “流”是互联网络上从特定源点到特定终点的一系列数据报, “流”所经过的路径上的路由器都保证指明的服务质量。所有属于同一个流的数据报都具有同样的流标号。 4.有效载荷长度(payload length)—— 16 位。它指明 IPv6 数据报除基本首部以外的字节数(所有扩展首部都算在有效载荷之内),其最大值是 64 KB。 5.下一个首部(next header)—— 8 位。它相当于 IPv4 的协议字段或可选字段。 6.跳数限制(hop limit)—— 8 位。源站在数据报发出时即设定跳数限制。路由器在转发数据报时将跳数限制字段中的值减1。当跳数限制的值为零时,就要将此数据报丢弃。 7.源地址—— 128 位。是数据报的发送站的 IP 地址。 8.目的地址—— 128 位。是数据报的接收站的 IP 地址。
IPv6 的扩展首部 IPv6 把原来 IPv4 首部中选项的功能都放在扩展首部中,并将扩展首部留给路径两端的源站和目的站的主机来处理。 数据报途中经过的路由器都不处理这些扩展首部(只有一个首部例外,即逐跳选项扩展首部)。 这样就大大提高了路由器的处理效率。
六种扩展首部 1.逐跳选项 2.路由选择 3.分片 4.鉴别 5.封装安全有效载荷 6.目的站选项
无扩展首部
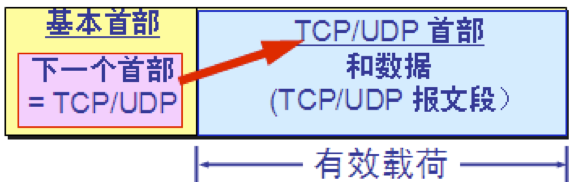
有扩展首部

扩展首部举例
IPv6 把分片限制为由源站来完成。源站可以采用保证的最小 MTU(1280字节),或者在发送数据前完成路径最大传送单元发现(Path MTU Discovery),以确定沿着该路径到目的站的最小 MTU。
分片扩展首部的格式如下:

IPv6 数据报的有效载荷长度为 3000 字节。下层的以太网的最大传送单元 MTU 是 1500 字节。
分成三个数据报片,两个 1400 字节长,最后一个是 200 字节长。
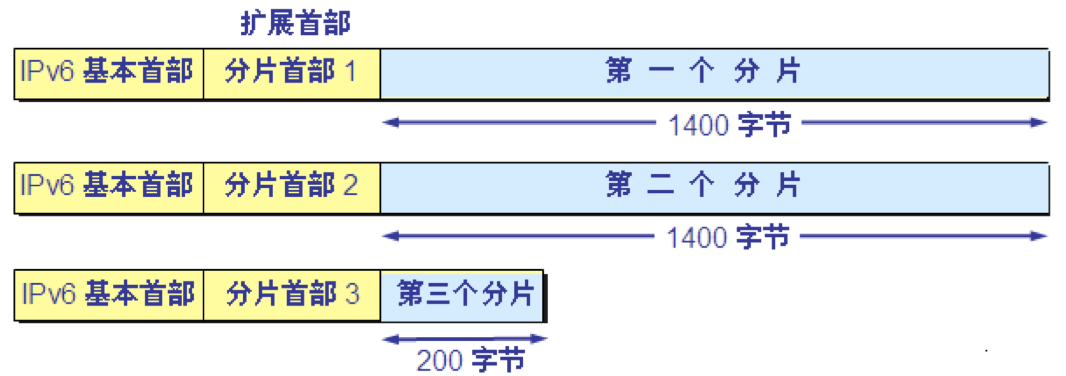
用隧道技术来传送长数据报 当路径途中的路由器需要对数据报进行分片时,就创建一个全新的数据报,然后将这个新的数据报分片,并在各个数据报片中插入扩展首部和新的基本首部。 路由器将每个数据报片发送给最终的目的站,而在目的站将收到的各个数据报片收集起来,组装成原来的数据报,再从中抽取出数据部分。
IPv6 的地址空间 地址的类型与地址空间 IPv6 数据报的目的地址可以是以下三种基本类型地址之一: (1) 单播(unicast) 单播就是传统的点对点通信。 (2) 多播(multicast) 多播是一点对多点的通信。 (3) 任播(anycast) 这是 IPv6 增加的一种类型。任播的目的站是一组计算机,但数据报在交付时只交付其中的一个,通常是距离最近的一个。
结点与接口 IPv6 将实现 IPv6 的主机和路由器均称为结点。 IPv6 地址是分配给结点上面的接口。 一个接口可以有多个单播地址。 一个结点接口的单播地址可用来唯一地标志该结点。
冒号十六进制记法 (colon hexadecimal notation) 每个 16 位的值用十六进制值表示,各值之间用冒号分隔。 68E6:8C64:FFFF:FFFF:0:1180:960A:FFFF 零压缩(zero compression),即一连串连续的零可以为一对冒号所取代。 FF05:0:0:0:0:0:0:B3 可以写成: FF05::B3
点分十进制记法的后缀 0:0:0:0:0:0:128.10.2.1 再使用零压缩即可得出: ::128.10.2.1 CIDR 的斜线表示法仍然可用。 60 位的前缀 12AB00000000CD3 可记为: 12AB:0000:0000:CD30:0000:0000:0000:0000/60 或12AB::CD30:0:0:0:0/60 或12AB:0:0:CD30::/60
地址空间的分配 IPv6 将 128 位地址空间分为两大部分。 第一部分是可变长度的类型前缀,它定义了地址的目的。 第二部分是地址的其余部分,其长度也是可变的。
特殊地址 未指明地址这是 16 字节的全 0 地址,可缩写为两个冒号“::”。这个地址只能为还没有配置到一个标准的 IP 地址的主机当作源地址使用。 环回地址即 0:0:0:0:0:0:0:1(记为 ::1)。 基于 IPv4 的地址前缀为 0000 0000 保留一小部分地址作为与 IPv4 兼容的。 本地链路单播地址
前缀为 0000 0000 的地址 前缀为 0000 0000 是保留一小部分地址与 IPv4 兼容的,这是因为必须要考虑到在比较长的时期 IPv 4和 IPv6 将会同时存在,而有的结点不支持 IPv6。 因此数据报在这两类结点之间转发时,就必须进行地址的转换。
全球单播地址的等级结构 IPv6 扩展了地址的分级概念,使用以下三个等级: (1) 全球路由选择前缀,占 48 位。 (2) 子网标识符,占16 位。 (3) 接口标识符,占 64 位。
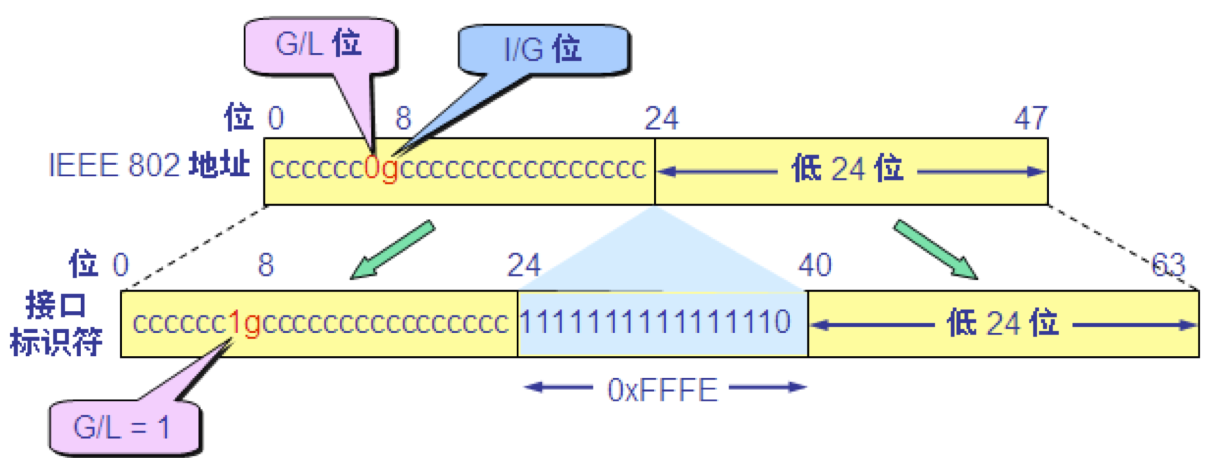
EUI-64 IEEE定 义了一个标准的 64 位全球唯一地址格式 EUI-64。 EUI-64 前三个字节(24 位)仍为公司标识符,但后面的扩展标识符是五个字节(40 位)。 较为复杂的是当需要将 48 位的以太网硬件地址转换为 IPv6 地址。
把以太网地址转换为 IPv6 地址
从 IPv4 向 IPv6 过渡
向 IPv6 过渡只能采用逐步演进的办法,同时,还必须使新安装的 IPv6 系统能够向后兼容。
IPv6 系统必须能够接收和转发 IPv4 分组,并且能够为 IPv4 分组选择路由。
双协议栈(dual stack)是指在完全过渡到 IPv6 之前,使一部分主机(或路由器)装有两个协议栈,一个 IPv4 和一个 IPv6。
使用隧道技术从 IPv4 到 IPv6 过渡
多协议标记交换 MPLS (MultiProtocol Label Switching) MPLS 的产生背景 在 20 世纪 80 年代,出现了一种思路:用面向连接的方式取代 IP 的无连接分组交换方式,这样就可以利用更快捷的查找算法,而不必使用最长前缀匹配的方法来查找路由表。 这种基本概念就叫做交换(switching)。 人们经常把这种交换概念与异步传递方式 ATM (Asynchronous Transfer Mode)联系起来, 在传统的路由器上也可以实现这种交换
MPLS 的特点 (1) 支持面向连接的服务质量。 (2) 支持流量工程,平衡网络负载。 (3) 有效地支持虚拟专用网 VPN。
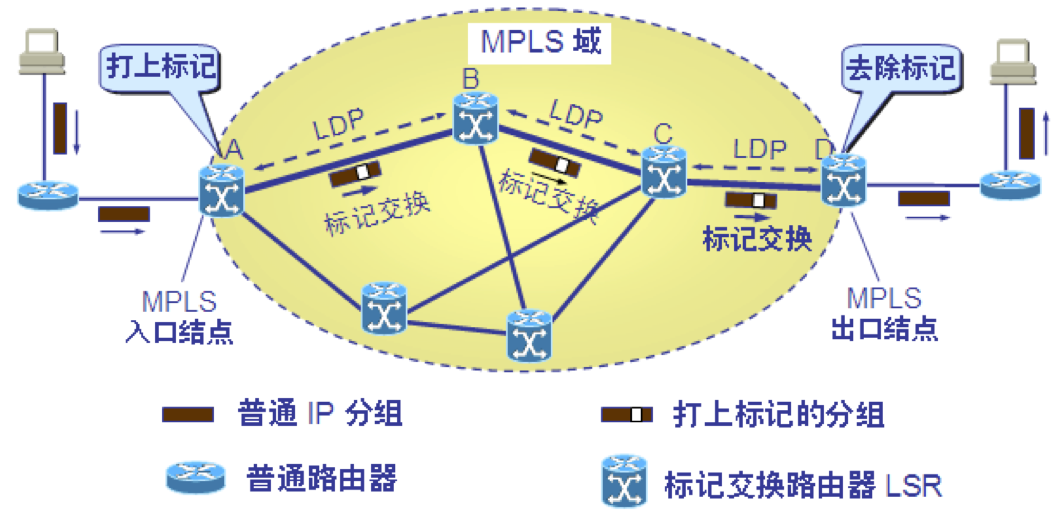
基本工作过程
MPLS 对打上固定长度“标记”的分组用硬件进行转发,使分组转发过程中省去了每到达一个结点都要查找路由表的过程,因而分组转发的速率大大加快。
采用硬件技术对打上标记的分组进行转发称为标记交换。“交换”也表示在转发分组时不再上升到第三层用软件分析 IP 首部和查找转发表,而是根据第二层的标记用硬件进行转发。